На что способен и на что должен быть способен FORTH?
Страница 1 из 1

На что способен и на что должен быть способен FORTH?
автор Gudleifr Пт Дек 01, 2017 12:54 pm
ПОЧЕМУ ОБ ЭТОМ СТОИТ ГОВОРИТЬ?
Свой путь земной пройдя до половины, я оказался в сумрачном лесу... /Сами знаете, кто/
Старые размышлизмы.
Точнее, старые вопросы, на некоторые из которых я смог ответить.
Стоп, стоп...
Это я десять лет назад мог написать "вопрос рассмотрен"... Даже те подробные инструкции и примеры, которые я выложил, теперь никому не помогают. Для машины A решаем задачу P...
Современный программист не способен как-то очертить контуры этой самой своей "машины A". Он мыслит о ней в рамках возможности запуска отдельных компиляторов/интерпретаторов, не понимая, как и с чем они работают, и, тем более, как и с чем будет работать скомпилированная программа.
Проблемы и с "целью писания P". Сформулировать ее в инженерных терминах современный программист тоже не способен. В лучшем случае он ставит во главу угла "оптимизацию", причем "оптимизацию всего и разом" - по обеспечению кроссплатформенности, быстродействию и компактности... В худшем, цель просто продать результат.
Наверное, таким "фортостроителям" просто не надо мешать. Пусть попробуют. Лет через пять, "когда все оригинальные попытки окончатся провалом, попробуют почитать инструкцию":
 ТЕМА #15, АБЗАЦ #386 (Позже расширил до "библиотеки" - см. каталог.).
ТЕМА #15, АБЗАЦ #386 (Позже расширил до "библиотеки" - см. каталог.).
ТЕМА #30 - как написать свой FORTH?
ТЕМА #43 - почему не получается написать свой FORTH?
Этот вопрос я позднее переформулировал: "Что делать с "возможностями" и "интерфейсами"?"
1. Создавать лексиконы наподобие Си-библиотек?
Появляется новое "устройство" - пишем новый лексикон (особый словарь), и все. Например, определяем слова ввода-вывода в порты, опроса семафоров и т.д. Комбинируем их в высокоуровневые слова типа "вкл/выкл". Плюс - можно подключить что угодно. Минус - теряется преимущество FORTH-подхода, программа становится практически неотличимой от написанной на Си.
2. Прятать внутрь интерпретатора? Закапываем всю машинерию вглубь интерпретатора. Пользователь даже не знает, что FORTH где-то что-то химичит. Например, так обеспечивается работа с FORTH-консолью в графических ОС и реализуется классическая многопользовательность путем переключения пользовательских областей. Плюс - FORTH-программы просты и стандартны. Минус - теряется способность программиста получить легкий доступ к внутренностям системы.
3. Усложнять интерпретатор? Расширяем классический интерпретатор не свойственными ему инструментами. Дополнительные Циклы Управления, включение новых хранилищ данных, процедур их итерпретации... Например, целевая компиляция, заменяющая стандартную интерпретацию реакцией на определенный ввод пользователя. Плюс - идеально подходит для изготовления нужного проблемно-ориентированного языка. Минус - FORTH перестает быть стандартным.
4. Использовать более одного интерпретатора? Объединить несколько FORTH-систем вместе. Например, у меня в FOBOS есть две форт-системы, объединенные общим словарем: одна заполняет словарь необходимыми для примера определениями, другая обрабатывает Win-сообщения примера. Плюс - каждая из систем остается простой. Минус - взаимопроникновение нескольких FORTH-систем совершенно не проработано.
Я выбрал четвертый вариант. По сути, это продолжение изначальной FORTH-идеи. От простых слов, соединенных простым способом перейти к простым машинам, опять просто соединенным.
Свой путь земной пройдя до половины, я оказался в сумрачном лесу... /Сами знаете, кто/
Старые размышлизмы.
Точнее, старые вопросы, на некоторые из которых я смог ответить.
Вопрос о том, как на минимальном "железе" и с минимумом затрат построить FORTH-систему, рассмотрен на данный момент очень широко и глубоко...
Стоп, стоп...
Это я десять лет назад мог написать "вопрос рассмотрен"... Даже те подробные инструкции и примеры, которые я выложил, теперь никому не помогают. Для машины A решаем задачу P...
Современный программист не способен как-то очертить контуры этой самой своей "машины A". Он мыслит о ней в рамках возможности запуска отдельных компиляторов/интерпретаторов, не понимая, как и с чем они работают, и, тем более, как и с чем будет работать скомпилированная программа.
Проблемы и с "целью писания P". Сформулировать ее в инженерных терминах современный программист тоже не способен. В лучшем случае он ставит во главу угла "оптимизацию", причем "оптимизацию всего и разом" - по обеспечению кроссплатформенности, быстродействию и компактности... В худшем, цель просто продать результат.
Наверное, таким "фортостроителям" просто не надо мешать. Пусть попробуют. Лет через пять, "когда все оригинальные попытки окончатся провалом, попробуют почитать инструкцию":
ТЕМА #15, АБЗАЦ #386 (Позже расширил до "библиотеки" - см. каталог.).ТЕМА #30 - как написать свой FORTH?ТЕМА #43 - почему не получается написать свой FORTH?А, вот, что делать, если аппаратно-программный комплекс, на котором мы будем реализовывать нашу FORTH-систему, позволяет расширять ее практически до полного исчерпания нашей фантазии? Ограничиться обеспечением FORTH-интерфейсов ко всем доступным в системе ресурсам, чем и предлагают заняться большинство FORTH-писателей? Даже на этом пути возникают проблемы. Как я показал в своей попытке написать сносный Win-интерфейс, попытка следовать парадигмам не-FORTH-систем в ущерб философии FORTH - дело очень муторное и бесполезное (в смысле - любой Delphi-программист может резонно спросить: "А зачем было выпендриваться?"). Кому нужна FORTH-система, в которой нельзя воспользоваться его преимуществами?
Этот вопрос я позднее переформулировал: "Что делать с "возможностями" и "интерфейсами"?"
1. Создавать лексиконы наподобие Си-библиотек?
Появляется новое "устройство" - пишем новый лексикон (особый словарь), и все. Например, определяем слова ввода-вывода в порты, опроса семафоров и т.д. Комбинируем их в высокоуровневые слова типа "вкл/выкл". Плюс - можно подключить что угодно. Минус - теряется преимущество FORTH-подхода, программа становится практически неотличимой от написанной на Си.
2. Прятать внутрь интерпретатора? Закапываем всю машинерию вглубь интерпретатора. Пользователь даже не знает, что FORTH где-то что-то химичит. Например, так обеспечивается работа с FORTH-консолью в графических ОС и реализуется классическая многопользовательность путем переключения пользовательских областей. Плюс - FORTH-программы просты и стандартны. Минус - теряется способность программиста получить легкий доступ к внутренностям системы.
3. Усложнять интерпретатор? Расширяем классический интерпретатор не свойственными ему инструментами. Дополнительные Циклы Управления, включение новых хранилищ данных, процедур их итерпретации... Например, целевая компиляция, заменяющая стандартную интерпретацию реакцией на определенный ввод пользователя. Плюс - идеально подходит для изготовления нужного проблемно-ориентированного языка. Минус - FORTH перестает быть стандартным.
4. Использовать более одного интерпретатора? Объединить несколько FORTH-систем вместе. Например, у меня в FOBOS есть две форт-системы, объединенные общим словарем: одна заполняет словарь необходимыми для примера определениями, другая обрабатывает Win-сообщения примера. Плюс - каждая из систем остается простой. Минус - взаимопроникновение нескольких FORTH-систем совершенно не проработано.
Я выбрал четвертый вариант. По сути, это продолжение изначальной FORTH-идеи. От простых слов, соединенных простым способом перейти к простым машинам, опять просто соединенным.
Последний раз редактировалось: Gudleifr (Вс Июл 09, 2023 12:48 am), всего редактировалось 5 раз(а)

Gudleifr- Admin
- Сообщения : 3399
Дата регистрации : 2017-03-29
Re: На что способен и на что должен быть способен FORTH?
автор Gudleifr Вс Дек 03, 2017 2:46 pm
Другой FORTH-проблемой является проблема стандартизации. Опять же, очень много говорено о том, что должна уметь минимальная FORTH-система. Кому это надо? Маленький проект проще написать заново, оптимизировав до упора и обрезав все лишнее. Ведь прелесть стандартизации - в облегчении написания больших проектов. А о них не написано ни слова. Надо стандартизировать табуретки, тогда и столяры постепенно на стандартные рубанки перейдут.
И не надо кивать на Броуди, писавшего в те годы, когда 10Мб-винчестер был роскошью. Им была воспета "кирпичиковость" FORTH (пленяющая нас простотой реализации и логической законченностью), но нет никаких стоящих идей относительно "зданий", которые из этих "кирпичиков" надо строить. Вся наша "архитектура", в общем случае,- не-FORTH-овская.
Поэтому данная статья посвящена вопросу: "Какой должна быть сложная FORTH-система?".
Все оказалось не просто, а очень просто. Нет никакой проблемы стандартизации. Есть проблема разбиения FORTH-системы на отдельные FORTH-машины.
После того, как я тупо перечислил составные части простейшего интерпретатора и пришел к мысли, что для решения сложных задач эти интерпретаторы можно просто соединять между собой, стандартизировать что-то, что лежит "между" стало бессмысленно...
Последний раз редактировалось: Gudleifr (Вс Июл 09, 2023 12:40 am), всего редактировалось 2 раз(а)
Gudleifr- Admin
- Сообщения : 3399
Дата регистрации : 2017-03-29
Re: На что способен и на что должен быть способен FORTH?
автор Gudleifr Вс Дек 03, 2017 2:48 pm
ЧТО ЕСТЬ FORTH-ПРОГРАММА?
Я до сих пор пытаюсь это сделать. Но тут FORTH оказывается чересчур хорошим средством. Проблема перестает быть проблемой языка программирования и становится проблемой умения литературно писать.
Слишком много "явно очевидного на момент писания программы" я опускаю, как само собой разумеющееся. Когда я потом читаю свои тексты, я, действительно, эти лакуны без труда восстанавливаю, но для других это так же трудно, как и читать другие мои "маловысокохудожественные" излияния. Мой "поток мыслей" одинаково кажется непонятным моим оппонентам будь он изложен на FORTH или на обычном русском языке.
Переход к системе связанных FORTH-машин делает возможным любые варианты - читайте хоть по слогам, хоть на слух воспринимайте...
Вместо "саморазвертывания сложной системы" пишите "добавление новых систем", и будет вам счастье! И не надо ничего закладывать.
Согласно канонам, она должна представлять из себя предложения из осмысленно-человеческих слов, составленные в последовательности примерно: "дополнение подлежащее определение обстоятельство сказуемое", т.е. - определение контекста действия, предмет действия, уточнения предмета действия и действия, действие. Возможно использование "оборотов" - подстановка вместо отдельного слова целого предложения, являющегося его описанием. Приветствуется замена часто встречаемых предложений, в том числе неполных, на единое сложное слово.
Можно ли превратить FORTH-программу в полностью литературный текст?
Я до сих пор пытаюсь это сделать. Но тут FORTH оказывается чересчур хорошим средством. Проблема перестает быть проблемой языка программирования и становится проблемой умения литературно писать.
Слишком много "явно очевидного на момент писания программы" я опускаю, как само собой разумеющееся. Когда я потом читаю свои тексты, я, действительно, эти лакуны без труда восстанавливаю, но для других это так же трудно, как и читать другие мои "маловысокохудожественные" излияния. Мой "поток мыслей" одинаково кажется непонятным моим оппонентам будь он изложен на FORTH или на обычном русском языке.
Мешает то, что FORTH интересует только смысл высказывания, а человеческие фразы содержат много слоев информации:
1. отношение говорящего к своему высказыванию (вплоть до полного отрицания произнесенной фразы);
2. грамматическая информация (заглавные буквы, знаки препинания), помогающие определить роль слов в предложении;
3. смысл собственно слов;
4. подтверждающие роль слов в предложении довески (артикли и окончания).
Чисто технически, добавление в FORTH-транслятор дополнительных средств, распознающих слова, невзирая на склонение и знаки препинания (и честно рассчитывающих их роль в предложении), с одной стороны, кажется ненужным усложнением (вызывая применение механизмов из обычных контекстно-зависимых компиляторов, от которых FORTH так удачно отказался). С другой стороны, необходимость в таких механизмах становится явной, когда FORTH ставится задачи интерпретации других потоков текстовых данных - формул, регулярных выражений, записей баз данных (жестко форматированных или с разделителями).
Более того, по мере усложнения FORTH-системы, может возникнуть и потребность общения программы с человеком на естественном языке.
А, если мы рано или поздно вставим в свою FORTH-систему несколько сложных интерпретаторов, то почему мы должны ограничивать интерпретацию потока команд только простейшим из них?
Переход к системе связанных FORTH-машин делает возможным любые варианты - читайте хоть по слогам, хоть на слух воспринимайте...
Таким образом, примитивный FORTH-язык - слова в нормальной форме, разделенные пробелами, должен быть присущ только первой стадии саморазвертывания сложной FORTH-системы.
Строить более сложные трансляторы на основе контекстно-зависимой компиляции или на основе экспертных систем распознавания текста - не так уж и важно, надо только заложить в эмбрион FORTH-системы возможность переключения с первичного механизма трансляции на любой другой.
Конечно, есть мнение, что при построении ядра можно ограничиться самыми простыми механизмами, а, затем, полностью их переопределять при построении своих "продвинутых" модулей, но стоит ли так делать?
Вместо "саморазвертывания сложной системы" пишите "добавление новых систем", и будет вам счастье! И не надо ничего закладывать.
Последний раз редактировалось: Gudleifr (Вс Июл 09, 2023 12:47 am), всего редактировалось 2 раз(а)
Gudleifr- Admin
- Сообщения : 3399
Дата регистрации : 2017-03-29
Re: На что способен и на что должен быть способен FORTH?
автор Gudleifr Вс Дек 03, 2017 2:52 pm
ВТОРИЧНАЯ УТИЛИЗАЦИЯ ЯДРА
Никакая.
Общение FORTH-машин "через СЛОВАРЬ" - это только частный случай.
КАКОВА ДАЛЬНЕЙШАЯ СУДЬБА FORTH-ПАРАДИГМ?
Тут, главное, понять, что ПОТОК, СТЕК, СЛОВАРЬ и ЗНАЧЕНИЕ не являются FORTH-ценностями. Это только сиюминутные подробности реализации одной из машин (или интерфейса между двумя машинами).
Отвечая на вопрос, заданный в конце предыдущего параграфа, мы, на самом деле, отвечаем на вопрос, гораздо более важный: "Какова мощность множества слов первичного FORTH-словаря, которым мы будем пользоваться в больших проектах?".
Никакая.
Ведь, если я переопределю в своем модуле слова интерпретации, компиляции и размещения стеков, то не смогу пользоваться практически никакими словами из начального набора - они останутся в некотором "параллельном мире", доступ к которому будет сильно ограничен.
Но, общепринятым способом написания большого проекта является создание удобного проблемно-ориентированного языка, на котором и пишется, собственно, программа. В отличие от всяких C++ (позволяющих написать на них любой проблемно-ориентированный язык при единственном условии - он должен быть тем же самым языком, что и исходный), FORTH, на свою беду, позволяет переписать себя полностью заново. Какова тогда роль эмбрионального словаря? Только средства саморазархивирования проекта? Конечно, в деятельности программистов случаются разные казусы, не встречающиеся "в дикой природе", но это уже перебор. Явно получается двойная работа.
Хочется заложить в ядро те механизмы, которые будут работать даже тогда, когда навешиваемые модули будут от него сильно отличаться логикой своей работы. Значит какую-никакую вариабельность и гибкость в него следует заложить. А, заодно, и те механизмы, которые не только не будут мешать программировать большие приложения, но и помогут в этом, и, даже, определят те направления в которых те будут развиваться. Такое не под силу ни одному языку, кроме FORTH, обидно этим не воспользоваться.
Общение FORTH-машин "через СЛОВАРЬ" - это только частный случай.
КАКОВА ДАЛЬНЕЙШАЯ СУДЬБА FORTH-ПАРАДИГМ?
Какие FORTH-ценности должны остаться незыблемыми при разрастании системы?
1. Отсутствие типизации - слово должно само заботится о том, откуда и в каком виде оно получает параметры и куда складывает результаты. Отсюда следует бредовость внедрения в FORTH-системы элементов объектно-ориентированного программирования (как и других систем, управляемых данными). Почему это важно? Потому, что иначе придется искусственно вводить в FORTH этап проектирования сверху-вниз, т.е. отказываться от важнейшего преимущества.
2. Шитый код. Цена его применения - отказ от параметров и типизации процедур, но это ограничение дает столько плюсов, что никто и никогда от него не откажется. Следовательно, вечен и шитый код. Разве что, убрать из него, на всякий случай, литералы?
3. Словари. Безусловно. Этот механизм компенсирует отсутствие всякого рода виртуальных функций и позволяет экономить пространство имен не хуже методов объектно-ориентированных функций. Надо ли его развивать? Обычного поиска в трех словарях (стандартном, поиска слов, добавления слов) вполне достаточно, однако, при проектировании этого механизма сразу следует учитывать, что механизмы работы со словарями могут очень сильно отличаться от словаря к словарю.
4. Стеки. Вот уж что я совершенно не согласен считать чем-то окончательным. Одно из самых важных FORTH-заблуждений касается именно универсальности стека. Действительно, простейшей FORTH-системе обычно достаточно двух - стека данных и стека возвратов (в обоих можно хранить целые числа и адреса). FORTH-программисты могут с упоением обсасывать проблемы оптимизацию размещения стеков в памяти, минимизацию набора слов для управления ими и т.п. Однако, как только FORTH-система начинает расти, появляется искушение добавить еще несколько стеков:
1. для усиления контроля на этапе исполнения и компиляции;
2. для данных, не вмещающихся в стандартную ячейку;
3. для отдельных подпроцессов.
К этой проблеме можно подойти с разных сторон:
1. С позиции теории обработки данных. Данные можно разделить на простые и сложные. Простые (вмещающиеся в одну ячейку) в зависимости от уровня их самодокументированности требуют для хранения от одной до трех ячеек: для собственно данных, признака типа (тэга) и ссылки на следующий элемент списка. Сложные (структуры, куски кода, вещественные числа, битовые и байтовые последовательности) требуют специальных хранилищ в памяти (с развитой системой сборки мусора).
Здесь, если и стек, то понимаемый уж очень широко.
2. С позиции теории вычислений. Стек - лишь примитивная разновидность ленты, которой снабжена всякая уважающая себя машина Тьюринга. В простой FORTH-системе стек гораздо удобнее, но для хранения данных во многих алгоритмах гораздо удобнее может оказаться и очередь, и дек, и примитивный массив.
3. С точки зрения унификации. А что такое поток ввода? Очередь байтов. Т.е. та же вечная лента. Причем, после трансляции она преобразуется опять в последовательность - адресов. И получается, что к нашим резонам расширить набор структур памяти добавляется еще один - структуры считывающиеся из различных источников (файлов, потоков, каналов и т.д) со всеми их проблемами буферизаций, рекурсий, транзакций и прочего.
Ответ кажется очевидным - каждый FORTH-модуль должен иметь свои структуры данных, может быть, ничего общего не имеющего со структурами остальных блоков.
5. Оптимизация и компиляция FORTH-кода. Бред изначально. Разом теряются все плюсы FORTH, FORTH-система опять превращается всего лишь в средство саморазархивирования. Хочешь пользоваться плодами этих "супертехнологий" - надстраивай над стандартом свои словари, поддерживающие эти "прибамбасы" и выпендривайся там.
Никто не говорит, что создавая свою FORTH-систему надо сразу закладывать в нее механизмы, обеспечивающие универсальность хранения данных, элементы баз знаний, процессоры для обработки всего, что можно измыслить...
Во-первых, такие структуры уже есть. Точнее, есть механизмы, позволяющие их легко дорастить и изолировать от примитивных зародышевых реализаций.
Во-вторых, если что-то и требуется добавить в эмбрион, так это какие-то связующие механизмы, позволяющие управлять разнородными модулями разрастающейся вширь FORTH-системы. Существующие решения (вроде многопользовательских FORTH-систем, связанных областями глобальных переменных), конечно, недостаточны.
В-третьих, я так ничего дельного и не сказал о том, во что же должна вырасти FORTH-система.
Тут, главное, понять, что ПОТОК, СТЕК, СЛОВАРЬ и ЗНАЧЕНИЕ не являются FORTH-ценностями. Это только сиюминутные подробности реализации одной из машин (или интерфейса между двумя машинами).
Последний раз редактировалось: Gudleifr (Вс Июл 09, 2023 12:57 am), всего редактировалось 1 раз(а)
Gudleifr- Admin
- Сообщения : 3399
Дата регистрации : 2017-03-29
Re: На что способен и на что должен быть способен FORTH?
автор Gudleifr Вс Дек 03, 2017 7:26 pm
Ну, все мои тогдашние измышлизмы по поводу внедрения в FORTH парадигм других языков, ООП всякого... устарели точно. А вот размышления о "чем-то большем" пусть еще повисят...
МОЗГИ! /ИЗ ФИЛЬМА ПРО ЖИВЫХ МЕРТВЕЦОВ/
Правомерно ли сравнение программы с организмом? Как ни крути, а программы пишуться только для достижения одной из двух целей:
1. облегчения человеку какой-либо работы (текстовые и графические редакторы, визуальные интерфейсы с заумными железяками...) и
2. замены человека в какой-либо сфере деятельности (управление этими самыми железяками, поиск информации, партнерство в играх...).
Причем, первая задача обычно является подзадачей более сложной - второй.
Значит, ожидание от умных программ какой-то человекообразности имеет обоснование. Как устроен человек?

Из книги "Алгориты разума" Н.М.Амосова:
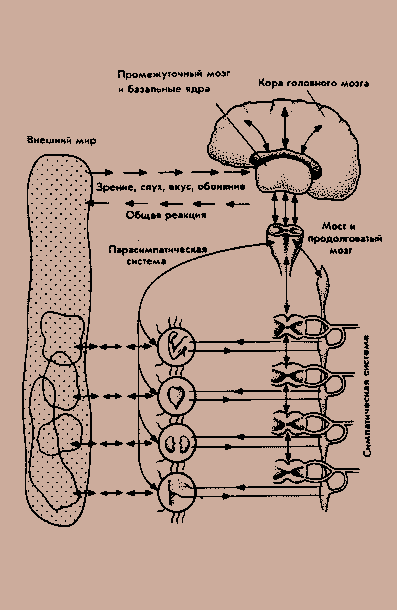
На рисунке показана схема интеллекта уровня человека и его отношения к внешнему миру, к среде. На схеме она представлена четырьмя составляющими. Это прежде всего природа, понимаемая во всей совокупности ее факторов. Затем - техника, под которой подразумеваются орудия воздействия на природу. Еще выше внешние модели - это наука. Наконец, наверху - общество. Новая схема отличается от предыдущей тем, что рецепторы получают не только энергию, косвенно сигнализирующую о внешней среде, но и прямую информацию в виде сигналов - от общества и внешних моделей. Между средой и рецепторами Рц встроены технические устройства ТУ1. Это всевозможные приборы, предназначенные для усиления внешних воздействий и превращения невоспринимаемых оргаорганами чувств видов энергии в воспринимаемые. Точно так же эффекторы Э могут быть вооружены инструментами ТУ2, значительно увеличивающими мощность их воздействий. От эффекторов идут стрелки, показывающие движение не только энергии, но и информации - сигналов, направленных в высшие системы, например в общество. Рецепторы имеют органы настройки Н, а эффекторы - свои собственные рецепторы Рцэ, обеспечивающие сигналы обратной связи. Рецепторы есть и в теле (Рцт). Моделирующая установка МУ ("Мозг") содержит модели внешней среды, тела, а также модели собственных программ и моделей действий МД. Наиболее разнообразны критерии Кр: в них представлены не только значимые качества тела, но и всех отделов внешней среды и, что самое интересное,- некоторые качества работы МУ ("мозга").
Опять натяжка? Природа - операционная система и новые драйвера, техника - драйвера, написанные нами, общество - другие программы? Смешно. Но ведь, практически все огрганы за исключением МУ и Кр уже неоднократно программировались большинством из читающих этих строки. (Более того, пользуясь этой схемой легко отделить (1) от (2).)
И если Ч.Мур - изобретатель FORTH - подчеркивал, что программирование FORTH-стиле соответствует его мышлению, то почему сложная FORTH-система должна быть способна на меньшее?
***
Как кибернетик решает задачу? "Переместить предмет X из пункта A в пункт B". Элементарно! Строим в пункте A машину, максимум энтропии которой достигается в пункте B, прицепляем к ней X, включаем, ждем...
Итак, хитрый кибернетик пользуется 2-ым началом термодинамики. Также им пользуются и все живые аппаратно-программные комплексы: информационное возбуждение нейронных сетей ограничивается их энергетическим затуханием, позволяющим обойтись без дополнительных логических петель.
В нашем программировании ничего подобного не наблюдается (за редким случаем некоторых особо удачных алгоритмов распределения ресурсов). Все наши вычисления строго информационны.
Это первое ограничение.
Второе ограничение связано с нашим нежеланием использовать в программировании вероятностные методы. Нет, конечно, анализ недетерминированных автоматов и алгоритмов иногда оказывается проще, да и хочется иногда написать "выведи сообщение где-нибудь на видном месте", но уж больно велики накладные расходы (пока нет квантовых компьютеров).
Третье ограничение - здравое понимание FORTH-программистами "бритвы Оккама": зачем делать обработчики сигналов сложнее, чем сами сигналы?
Зачем вообще мозгу нужны какие-то там критерии?
во-первых, для выбора одной из возможных моделей действий (МД) "при прочих равных";
во-вторых, для интегральной оценки успешности функционирования, которая может привести как к прекращению выполнения действия, так и к возврату к одному из узлов рекурсивного перебора.
В наиболее размытом виде:
- слово берется оттуда, откуда по мнению системы поступает наиболее важная информация (настройка рецепторов);
- слово имеет ряд контекстнозависимых признаков (сведения об источнике, логических, временнЫх и пространственных связях с ранее введенными словами);
- слова могут группироваться с выработкой обобщающего слова (понятия, абстракции);
- слово может не иметь точного совпадения со словами словаря;
- слов, подлежащих исполнению/компиляции может быть несколько (отложенная активность);
- вариантов исполнения слова может быть несколько (выбор по критерию).
***
А в абсолюте, наверное, в "Амосовской FORTH-машине":
слово - модель;
СТЕК - кратковременная память, СЛОВАРЬ - долговременная;
ВЫПОЛНИТЬ - оставить возбужденным в СТЕКЕ, в случае МД - реальное действие;
КОМПИЛИРОВАТЬ - связать в СЛОВАРЕ одновременно возбужденные модели;
создание новых словарных статей - возбуждение случайно возбужденных запасных моделей (и связывание с ними).
МОЗГИ! /ИЗ ФИЛЬМА ПРО ЖИВЫХ МЕРТВЕЦОВ/
Итак, в начале - простейшие структуры, позволяющие сделать что угодно как угодно. Второй этап - написание своих словарей для каждой Дейкстровой машины-бусины (по модному - уровня абстракции). И все...
И так до конца? Пока последний словарь не покроет наши потребности? Или пока вся эта пирамида словарей не вырастет настолько, что рухнув погребет нас под собой? И, причем, при полной невозможности стандартизации (FORTH-соглашения постулируют, что каждый пишет наиболее приемлемым для себя способом).
В чем может заключаться "третий этап"? Наличием некоторых структур-парадигм, описывающих универсальный FORTH-организм, в котором программист создает только те органы, которые ему нужны?
Например, в отечественной ТИП-технологии предлагалось все интерфейсы вертикально разделить на три уровня: представления (форматы хранения, алгоритмы, машинно-зависимый код), определения (работа в терминах атрибутов и методов) и концепций (внешний интерфейс); горизонтально - на четыре вида: генерации (перевод в начальное состояние, чтение данных), доступа (получение доступа к данным), модификации (приказ об изменении состояния, модификации данных), вывода (форматный вывод данных и статистик).
Понятно, что интереснее классифицировать не структурно, но функционально, например, делая FORTH-систему более похожей на живой организм (как пример удачного проектирования сложной системы самой природой).
Моделью живого организма является гомеостат Эшби. Эта штука нормально находится в равновесии. Внешнее воздействие равновесие нарушает. Гомеостат производит какие-то действия, чтобы его восстановить. Если внешнее воздействие слишком сильно чтобы равновесие могло восстановиться, то гомеостат переходит в новое состояние и пытается восстановить равновесие уже в нем...
Не правда ли, похоже на Windows? Я изменяю геометрию одного окна, и несчастный Must Die усиленно перерисовывает экран, чтобы остальные окна отрисовались как надо. К сожалению, сходство, по большей части, слишком поверхностное, т.к. программист должен приложить значительные усилия, чтобы Винда при этом не рухнула: вызвать/обработать кучу сообщений, грамотно закончить рисующие транзакции, освободить затребованные графические объекты...
Правомерно ли сравнение программы с организмом? Как ни крути, а программы пишуться только для достижения одной из двух целей:
1. облегчения человеку какой-либо работы (текстовые и графические редакторы, визуальные интерфейсы с заумными железяками...) и
2. замены человека в какой-либо сфере деятельности (управление этими самыми железяками, поиск информации, партнерство в играх...).
Причем, первая задача обычно является подзадачей более сложной - второй.
Значит, ожидание от умных программ какой-то человекообразности имеет обоснование. Как устроен человек?

Из книги "Алгориты разума" Н.М.Амосова:
На рисунке показана схема интеллекта уровня человека и его отношения к внешнему миру, к среде. На схеме она представлена четырьмя составляющими. Это прежде всего природа, понимаемая во всей совокупности ее факторов. Затем - техника, под которой подразумеваются орудия воздействия на природу. Еще выше внешние модели - это наука. Наконец, наверху - общество. Новая схема отличается от предыдущей тем, что рецепторы получают не только энергию, косвенно сигнализирующую о внешней среде, но и прямую информацию в виде сигналов - от общества и внешних моделей. Между средой и рецепторами Рц встроены технические устройства ТУ1. Это всевозможные приборы, предназначенные для усиления внешних воздействий и превращения невоспринимаемых оргаорганами чувств видов энергии в воспринимаемые. Точно так же эффекторы Э могут быть вооружены инструментами ТУ2, значительно увеличивающими мощность их воздействий. От эффекторов идут стрелки, показывающие движение не только энергии, но и информации - сигналов, направленных в высшие системы, например в общество. Рецепторы имеют органы настройки Н, а эффекторы - свои собственные рецепторы Рцэ, обеспечивающие сигналы обратной связи. Рецепторы есть и в теле (Рцт). Моделирующая установка МУ ("Мозг") содержит модели внешней среды, тела, а также модели собственных программ и моделей действий МД. Наиболее разнообразны критерии Кр: в них представлены не только значимые качества тела, но и всех отделов внешней среды и, что самое интересное,- некоторые качества работы МУ ("мозга").
Опять натяжка? Природа - операционная система и новые драйвера, техника - драйвера, написанные нами, общество - другие программы? Смешно. Но ведь, практически все огрганы за исключением МУ и Кр уже неоднократно программировались большинством из читающих этих строки. (Более того, пользуясь этой схемой легко отделить (1) от (2).)
И если Ч.Мур - изобретатель FORTH - подчеркивал, что программирование FORTH-стиле соответствует его мышлению, то почему сложная FORTH-система должна быть способна на меньшее?
***
Как кибернетик решает задачу? "Переместить предмет X из пункта A в пункт B". Элементарно! Строим в пункте A машину, максимум энтропии которой достигается в пункте B, прицепляем к ней X, включаем, ждем...
Итак, хитрый кибернетик пользуется 2-ым началом термодинамики. Также им пользуются и все живые аппаратно-программные комплексы: информационное возбуждение нейронных сетей ограничивается их энергетическим затуханием, позволяющим обойтись без дополнительных логических петель.
В нашем программировании ничего подобного не наблюдается (за редким случаем некоторых особо удачных алгоритмов распределения ресурсов). Все наши вычисления строго информационны.
Это первое ограничение.
Второе ограничение связано с нашим нежеланием использовать в программировании вероятностные методы. Нет, конечно, анализ недетерминированных автоматов и алгоритмов иногда оказывается проще, да и хочется иногда написать "выведи сообщение где-нибудь на видном месте", но уж больно велики накладные расходы (пока нет квантовых компьютеров).
Третье ограничение - здравое понимание FORTH-программистами "бритвы Оккама": зачем делать обработчики сигналов сложнее, чем сами сигналы?
Зачем вообще мозгу нужны какие-то там критерии?
во-первых, для выбора одной из возможных моделей действий (МД) "при прочих равных";
во-вторых, для интегральной оценки успешности функционирования, которая может привести как к прекращению выполнения действия, так и к возврату к одному из узлов рекурсивного перебора.
В наиболее размытом виде:
- слово берется оттуда, откуда по мнению системы поступает наиболее важная информация (настройка рецепторов);
- слово имеет ряд контекстнозависимых признаков (сведения об источнике, логических, временнЫх и пространственных связях с ранее введенными словами);
- слова могут группироваться с выработкой обобщающего слова (понятия, абстракции);
- слово может не иметь точного совпадения со словами словаря;
- слов, подлежащих исполнению/компиляции может быть несколько (отложенная активность);
- вариантов исполнения слова может быть несколько (выбор по критерию).
***
А в абсолюте, наверное, в "Амосовской FORTH-машине":
слово - модель;
СТЕК - кратковременная память, СЛОВАРЬ - долговременная;
ВЫПОЛНИТЬ - оставить возбужденным в СТЕКЕ, в случае МД - реальное действие;
КОМПИЛИРОВАТЬ - связать в СЛОВАРЕ одновременно возбужденные модели;
создание новых словарных статей - возбуждение случайно возбужденных запасных моделей (и связывание с ними).
Последний раз редактировалось: Gudleifr (Вс Июл 09, 2023 1:01 am), всего редактировалось 2 раз(а)
Gudleifr- Admin
- Сообщения : 3399
Дата регистрации : 2017-03-29
Re: На что способен и на что должен быть способен FORTH?
автор Gudleifr Пн Дек 04, 2017 12:17 am
Просто перечисление интеллектуальных возможностей FORTH-машин уже наводит на мысль о добавлении в нее некоторых новых узлов (например, арбитров, или, по Амосову, СУТ - систему усиления/торможения).
Чтобы еще немного усугубить:
СОЛЬЕМСЯ В ЭКСТАЗЕ! /ПИТКИН В ТЫЛУ ВРАГА/
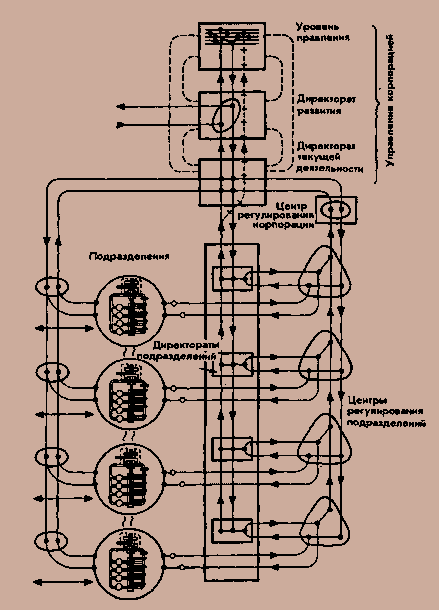
Из книги "Мозг фирмы" Стаффорда Бира. Слева - человек, справа - корпорация.
Бир утверждает, что всякая уважающая себя автономная самоуправляемая система состоит из пяти уровней.
1. Первый уровень - отдельные органы (рецепторы и эффекторы), которые обеспечивают функциональность системы. Нарисованы в кружочках. Это единственные органы системы, которые обладают некоторой автономией. Автономия управляющих органов на других уровнях - зло, которое надо искоренять.
2. Второй уровень - вертикально (по важности для организма, циклу производства корпорации) организованная цепь, связывающая органы в единую сеть.
3. Третий уровень - орган равновесия, следящий за балансом систем органов. Сюда, кроме отчетности, приходящей по вертикальному каналу со второго уровня, сходится "парасимпатическая" информация, свидетельствующая об общем благополучии систем первого уровня (Бир называет ее алгедонической). Так же и управление осуществляется как по вертикали - приказы "что делать", так и в обход системы два - указания "как напрягаться". Квадратик, образуемый пересечением линий в "Центре регулирования информации", символизирует гомеостат - кибернетическую абстракцию сверхустойчивой системы (которая до последнего пытается остаться в текущем состоянии, поддерживая равновесие параметров, по, при слишком сильном возмущении, переходит в соседнее состояние и пытается достичь равновесия в нем).
4. Четвертый уровень - главный фильтр информации, передаваемой на пятый уровень, а, заодно, и средство поддержания коммуникации с внешним миром. Здесь надо отметить, что главным требованием в кибернетическом управлении является разнообразие (в кибернетическом смысле) управляющей системы большее, чем управляемой. Так что управляющие системы всех уровней занимаются фильтрацией информации, отправвляя "наверх" только самую необходимую.
5. Пятый уровень - собственно "думатель". Сложная система нейронов (людей), принимающих решения (далее - по Амосову, с его М-моделями). Основным свойством подобной организации управления Бир считает рекурсивность, т.е. рассматриваемая пятиуровневая автономная система служит в качестве системы первого уровня другой - ее охватывающей (работники - фирмы - корпорации - государства - мировое сообщество).
А как выглядят на этом фоне современные программы? Возьмем самый распространенный тип - автоматизированное рабочее место (АРМ). Т.е. программа, превращающая компьютер в некий пульт управления чем-либо (например, в интеллектуальную пишущую машинку - в случае MS Word). "По Эшби и Биру" такая программа выглядит как довесок к человеку. Т.е. оператор - "мозг" системы - уровень 5. Соответственно, оконный интерфейс - уровень 4.
В большинстве же реально существующих программ оператор рассматривается в качестве "внешней среды", формы оконного интерфейса практически полностью покрывают уровень 1, а редкие "смысловые" вкрапления и управляющие структуры образуют уровень 2. При таком подходе, казалось бы, огромное значение приобретает поддержание системы в равновесии (из которого его пытается вывести пользователь своими командами), но уровень 3, этим занимающийся, обычно отсутствует. Уровней 4 и 5 тоже не наблюдается. И не может наблюдаться в принципе, поскольку современный подход к "АСУчиванию" никаким образом не предусматривает потерю информации при передаче ее "наверх". Поэтому мы и говорим сейчас обычно не о кибернетике, а об информатике - т.е. максимально возможном накоплении информации, с развитыми способами ее поиска, сортировки, переформатирования, визуализации, передачи, и очень ограниченными - семантической обработки и использовании в управлении.
А что значит "системы 1-го уровня обладают автономией"? Наверное, стоит их выделить в отдельные процессы/потоки. Конечно, сейчас модно выносить в отдельный поток выполнение любой команды, но то что при этом мы выигрываем в отсутствии сложного конечного автомата, отслеживающего состояние системы, то проигрываем в необходимости синхронизации потоков.
Каким образом соединять FORTH-машины для получения таких цепочек?
Чтобы еще немного усугубить:
СОЛЬЕМСЯ В ЭКСТАЗЕ! /ПИТКИН В ТЫЛУ ВРАГА/


Из книги "Мозг фирмы" Стаффорда Бира. Слева - человек, справа - корпорация.
Бир утверждает, что всякая уважающая себя автономная самоуправляемая система состоит из пяти уровней.
1. Первый уровень - отдельные органы (рецепторы и эффекторы), которые обеспечивают функциональность системы. Нарисованы в кружочках. Это единственные органы системы, которые обладают некоторой автономией. Автономия управляющих органов на других уровнях - зло, которое надо искоренять.
2. Второй уровень - вертикально (по важности для организма, циклу производства корпорации) организованная цепь, связывающая органы в единую сеть.
3. Третий уровень - орган равновесия, следящий за балансом систем органов. Сюда, кроме отчетности, приходящей по вертикальному каналу со второго уровня, сходится "парасимпатическая" информация, свидетельствующая об общем благополучии систем первого уровня (Бир называет ее алгедонической). Так же и управление осуществляется как по вертикали - приказы "что делать", так и в обход системы два - указания "как напрягаться". Квадратик, образуемый пересечением линий в "Центре регулирования информации", символизирует гомеостат - кибернетическую абстракцию сверхустойчивой системы (которая до последнего пытается остаться в текущем состоянии, поддерживая равновесие параметров, по, при слишком сильном возмущении, переходит в соседнее состояние и пытается достичь равновесия в нем).
4. Четвертый уровень - главный фильтр информации, передаваемой на пятый уровень, а, заодно, и средство поддержания коммуникации с внешним миром. Здесь надо отметить, что главным требованием в кибернетическом управлении является разнообразие (в кибернетическом смысле) управляющей системы большее, чем управляемой. Так что управляющие системы всех уровней занимаются фильтрацией информации, отправвляя "наверх" только самую необходимую.
5. Пятый уровень - собственно "думатель". Сложная система нейронов (людей), принимающих решения (далее - по Амосову, с его М-моделями). Основным свойством подобной организации управления Бир считает рекурсивность, т.е. рассматриваемая пятиуровневая автономная система служит в качестве системы первого уровня другой - ее охватывающей (работники - фирмы - корпорации - государства - мировое сообщество).
А как выглядят на этом фоне современные программы? Возьмем самый распространенный тип - автоматизированное рабочее место (АРМ). Т.е. программа, превращающая компьютер в некий пульт управления чем-либо (например, в интеллектуальную пишущую машинку - в случае MS Word). "По Эшби и Биру" такая программа выглядит как довесок к человеку. Т.е. оператор - "мозг" системы - уровень 5. Соответственно, оконный интерфейс - уровень 4.
В большинстве же реально существующих программ оператор рассматривается в качестве "внешней среды", формы оконного интерфейса практически полностью покрывают уровень 1, а редкие "смысловые" вкрапления и управляющие структуры образуют уровень 2. При таком подходе, казалось бы, огромное значение приобретает поддержание системы в равновесии (из которого его пытается вывести пользователь своими командами), но уровень 3, этим занимающийся, обычно отсутствует. Уровней 4 и 5 тоже не наблюдается. И не может наблюдаться в принципе, поскольку современный подход к "АСУчиванию" никаким образом не предусматривает потерю информации при передаче ее "наверх". Поэтому мы и говорим сейчас обычно не о кибернетике, а об информатике - т.е. максимально возможном накоплении информации, с развитыми способами ее поиска, сортировки, переформатирования, визуализации, передачи, и очень ограниченными - семантической обработки и использовании в управлении.
А что значит "системы 1-го уровня обладают автономией"? Наверное, стоит их выделить в отдельные процессы/потоки. Конечно, сейчас модно выносить в отдельный поток выполнение любой команды, но то что при этом мы выигрываем в отсутствии сложного конечного автомата, отслеживающего состояние системы, то проигрываем в необходимости синхронизации потоков.
Каким образом соединять FORTH-машины для получения таких цепочек?
Последний раз редактировалось: Gudleifr (Вс Июл 09, 2023 1:05 am), всего редактировалось 2 раз(а)
Gudleifr- Admin
- Сообщения : 3399
Дата регистрации : 2017-03-29
Re: На что способен и на что должен быть способен FORTH?
автор Gudleifr Пн Дек 04, 2017 12:22 am
КАК КОММЕНТИРОВАТЬ КОММЕНТАРИИ?
Если, с точки зрения декомпозиции, т.е. разбиения сложной программы на обозримые фрагменты, FORTH оставлет далеко за флагом все остальные языки, то проблема управления проектированием программ проработана явно недостаточно.
Как, вообще, может помочь компьютер программисту в написании программ? Т.к. компьютер не умеет думать, то, наверное, он должен уметь сохранять результаты раздумий программиста (даже в незаконченной форме) и обеспечивать удобный способов извлечения этих данных для доведения до ума и вставки в проект. База знаний в чистом виде. Языки высокого уровня на это замахнулись, обрастая со временем бешеным количеством библиотек на все случаи программистской жизни, введя абстрактные классы и шаблоны. Однако, им не хватает двух вещей: отсутствует возможность хранения незаконченных фрагментов и, что более существенно, поиск нужного полуфабриката приходится производить методом полного перебора библиотеки.
Единственным узаконенным FORTH-полуфабрикатом является черновая запись слова с игнорированием стековых операций. Это близко к той "нитке бус", которую предлагал Дейкстра, но абсолютно неприемлемо для последователей структурного программирования в стиле Вирта (для которых структуры данных важнее структуры программы).
С точки зрения "машин пятого поколения", язык для "записи идей" должен включать: средства описания и вычисления предикатов (в том числе, вероятностные), развитые структуры данных, семантические сети. (Не удивительно, что у японцев ничего не получилось.)
***
Другое, сразу приходящее в голову, усовершенствование языка программирования для описания идей - возможность компактной записи вариантов программного блока. Когда работа над блоком начинается, мы записываем сюда просто его спецификацию. Когда пытаемся проверить программу без него - пишем заглушку. Иногда вставляем в это место пользовательский интерфейс - для отображения ситуации и ручного ввода якобы выходных параметров этого блока. В конце концов это место занимает настоящая программная реализация - в отладочном или окончательном виде. Желательно бывает хранить здесь не одну, а несколько реализаций.
В C-подобных языках подобное реализуется (очень неаккуратно) тремя механизмами: комментариями, условной компиляцией или наличием нескольких вариантов библиотек (условной сборкой). Условная компиляция, вроде бы, дает большую наглядность, но приводит к появлению совершенно нечитаемых текстов. Это послужило причиной многочисленных рекомендаций, в случае наличия нескольких реализаций модуля, хранить их в виде отдельных библиотек (хоть это и громоздко).
Дейкстра группировал варианты в рамках одной машины, говоря о наборах бусин. Кнут разбивал процедурные блоки на три группы - комментариев, определений и кода (связывая их перекрестными ссылками).
FORTH в этом случае оказывается не на высоте. Слова-синонимы, конечно, возможны, но сохранить их так, чтобы самому не запутаться вряд ли возможно. Кроме того необходим некоторый формализм меток блоков (как у Кнута). Блок должен быть явно помечен как, например: ОПИСАНИЕ, ПРЕДИКАТЫ, ЗАГЛУШКА, ЗАПРОС, ОТЛАДКА, РЕАЛИЗАЦИЯ и т.д. Необходимо так же хранить подобные блоки рядом, да еще с указанием применимости каждого из них в конкретном случае: самодокументирование, отладка, операционная система такая-то...
Возникает мысль использовать что-то вроде условных конструкций Дейкстры (пары условие-действие, перебираемые с случайном порядке, пока условие не выполнится) и даже возникает крамольный вопрос, не допустимо ли оставить в проекте не одну реализацию, а несколько, с ненулевой вероятностью выбора? Однако, это не совсем то, что нужно в FORTH, ориентированном в первую очередь на вычисления и таблицы, а не на громоздкие CASE-конструкции.
***
Недавно снова столкнулся с подобной проблемой в FORTH. Что должно быть более информатировным для пользователя при интерактивной разработке: листинг программы, результат ее работы или некоторая дополнительная справочная система?
Если, с точки зрения декомпозиции, т.е. разбиения сложной программы на обозримые фрагменты, FORTH оставлет далеко за флагом все остальные языки, то проблема управления проектированием программ проработана явно недостаточно.
Как, вообще, может помочь компьютер программисту в написании программ? Т.к. компьютер не умеет думать, то, наверное, он должен уметь сохранять результаты раздумий программиста (даже в незаконченной форме) и обеспечивать удобный способов извлечения этих данных для доведения до ума и вставки в проект. База знаний в чистом виде. Языки высокого уровня на это замахнулись, обрастая со временем бешеным количеством библиотек на все случаи программистской жизни, введя абстрактные классы и шаблоны. Однако, им не хватает двух вещей: отсутствует возможность хранения незаконченных фрагментов и, что более существенно, поиск нужного полуфабриката приходится производить методом полного перебора библиотеки.
Единственным узаконенным FORTH-полуфабрикатом является черновая запись слова с игнорированием стековых операций. Это близко к той "нитке бус", которую предлагал Дейкстра, но абсолютно неприемлемо для последователей структурного программирования в стиле Вирта (для которых структуры данных важнее структуры программы).
С точки зрения "машин пятого поколения", язык для "записи идей" должен включать: средства описания и вычисления предикатов (в том числе, вероятностные), развитые структуры данных, семантические сети. (Не удивительно, что у японцев ничего не получилось.)
***
Другое, сразу приходящее в голову, усовершенствование языка программирования для описания идей - возможность компактной записи вариантов программного блока. Когда работа над блоком начинается, мы записываем сюда просто его спецификацию. Когда пытаемся проверить программу без него - пишем заглушку. Иногда вставляем в это место пользовательский интерфейс - для отображения ситуации и ручного ввода якобы выходных параметров этого блока. В конце концов это место занимает настоящая программная реализация - в отладочном или окончательном виде. Желательно бывает хранить здесь не одну, а несколько реализаций.
В C-подобных языках подобное реализуется (очень неаккуратно) тремя механизмами: комментариями, условной компиляцией или наличием нескольких вариантов библиотек (условной сборкой). Условная компиляция, вроде бы, дает большую наглядность, но приводит к появлению совершенно нечитаемых текстов. Это послужило причиной многочисленных рекомендаций, в случае наличия нескольких реализаций модуля, хранить их в виде отдельных библиотек (хоть это и громоздко).
Дейкстра группировал варианты в рамках одной машины, говоря о наборах бусин. Кнут разбивал процедурные блоки на три группы - комментариев, определений и кода (связывая их перекрестными ссылками).
FORTH в этом случае оказывается не на высоте. Слова-синонимы, конечно, возможны, но сохранить их так, чтобы самому не запутаться вряд ли возможно. Кроме того необходим некоторый формализм меток блоков (как у Кнута). Блок должен быть явно помечен как, например: ОПИСАНИЕ, ПРЕДИКАТЫ, ЗАГЛУШКА, ЗАПРОС, ОТЛАДКА, РЕАЛИЗАЦИЯ и т.д. Необходимо так же хранить подобные блоки рядом, да еще с указанием применимости каждого из них в конкретном случае: самодокументирование, отладка, операционная система такая-то...
Возникает мысль использовать что-то вроде условных конструкций Дейкстры (пары условие-действие, перебираемые с случайном порядке, пока условие не выполнится) и даже возникает крамольный вопрос, не допустимо ли оставить в проекте не одну реализацию, а несколько, с ненулевой вероятностью выбора? Однако, это не совсем то, что нужно в FORTH, ориентированном в первую очередь на вычисления и таблицы, а не на громоздкие CASE-конструкции.
***
Недавно снова столкнулся с подобной проблемой в FORTH. Что должно быть более информатировным для пользователя при интерактивной разработке: листинг программы, результат ее работы или некоторая дополнительная справочная система?
Последний раз редактировалось: Gudleifr (Пн Дек 04, 2017 12:34 am), всего редактировалось 1 раз(а)
Gudleifr- Admin
- Сообщения : 3399
Дата регистрации : 2017-03-29
Re: На что способен и на что должен быть способен FORTH?
автор Gudleifr Пн Дек 04, 2017 12:28 am
ГРАНИЦЫ САМОРАСШИРЕНИЯ
Брукс, Мифический целовеко-месяц:
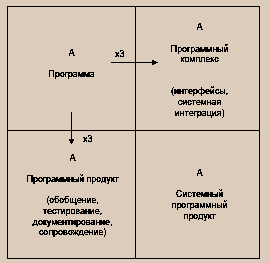
"В левом верхнем углу рисунка находится программа. Она является завершенным продуктом, пригодным для запуска своим автором на системе, на которой была разработана. В гаражах обычно производится такой продукт, и это - тот объект, посредством которого отдельный программист оценивает свою производительность.
Есть два способа, которыми программу можно превратить в более полезный, но и более дорогой объект. Эти два способа представлены по краям рисунка.
При перемещении вниз через горизонтальную границу программа превращается в программный продукт. Это программа, которую любой человек может запускать, тестировать, исправлять и развивать. Она может использоваться в различных операционных средах и со многими наборами данных. Чтобы стать общеупотребительным программным продуктом, программа должна быть написана в обобщенном стиле. В частности, диапазон и вид входных данных должны быть настолько обобщенными, насколько это допускается базовым алгоритмом. Затем программу нужно тщательно протестировать, чтобы быть уверенным в ее надежности. Для этого нужно подготовить достаточное количество контрольных примеров для проверки диапазона допустимых значений входных данных и определения его границ, обработать эти примеры и зафиксировать результаты. Наконец, развитие программы в программный продукт требует создания подробной документации, с помощью которой каждый мог бы использовать ее, делать исправления и расширять. Я пользуюсь практическим правилом, согласно которому программный продукт стоит, по меньшей мере, втрое дороже, чем просто отлаженная программа с такой же функциональностью.
При пересечении вертикальной границы программа становится компонентом программного комплекса. Последний представляет собой набор взаимодействующих программ, согласованных по функциям и форматам, и вкупе составляющих полное средство для решения больших задач. Чтобы стать частью программного комплекса, синтаксис и семантика ввода и вывода программы должны удовлетворять точно определенным интерфейсам. Программа должна быть также спроектирована таким образом, чтобы использовать заранее оговоренный бюджет ресурсов - объем памяти, устройства ввода/вывода, процессорное время. Наконец, программу нужно протестировать вместе с прочими системными компонентами во всех сочетаниях, которые могут встретиться. Это тестирование может оказаться большим по объему, поскольку количество тестируемых случаев растет экспоненциально. Оно также занимает много времени, так как скрытые ошибки выявляются при неожиданных взаимодействиях отлаживаемых компонентов. Компонент программного комплекса стоит, по крайней мере, втрое дороже, чем автономная программа с теми же функциями. Стоимость может увеличиться, если в системе много компонентов.
В правом нижнем углу рисунка находится системный программный продукт. От обычной программы он отличается во всех перечисленных выше отношениях. И стоит, соответственно, в десять раз дороже. Но это действительно полезный объект, который является целью большинства системных программных проектов".
Как же обстоит дело для программ, написанных на Forth (FORTH-системой)?
Сделать из программы программный продукт? Ну, она изначально должна быть в некоторой степени "программным продуктом", поскольку изначально включает интерактивную составляющую.
А программный компонент? Ну нет! Уж лучше создать свой Forth-комплекс, чем встроить свою Forth-программу в существующий. Операционные системы (ОС) предлагают свои способы - ориентированные на процессы и/или сообщения, но Forth с его BASIC-подобным вводом-выводом не может ни того, ни другого... Нет, конечно можно написать Forth-программу, которая будет взаимодействовать с какой-либо частью ОС по ее законам, но этот интерфей будет лишь "результатом работы", но никак не "естественным общением". А это самое "естественное общение" и есть основопологающая составная Forth-систем. Ведь, "ввод", который ожидает Forth-система - это приказы на естественном Forth-языке, а не просто набор данных, которые нужно обработать...
Программный комплекс, должен быть, скорее, новой машиной, чем доработкой старой.
Наконец, хочется, чтобы системный программный продукт был машиной, пригодной для встраивания в более сложные машины...
Брукс, Мифический целовеко-месяц:

"В левом верхнем углу рисунка находится программа. Она является завершенным продуктом, пригодным для запуска своим автором на системе, на которой была разработана. В гаражах обычно производится такой продукт, и это - тот объект, посредством которого отдельный программист оценивает свою производительность.
Есть два способа, которыми программу можно превратить в более полезный, но и более дорогой объект. Эти два способа представлены по краям рисунка.
При перемещении вниз через горизонтальную границу программа превращается в программный продукт. Это программа, которую любой человек может запускать, тестировать, исправлять и развивать. Она может использоваться в различных операционных средах и со многими наборами данных. Чтобы стать общеупотребительным программным продуктом, программа должна быть написана в обобщенном стиле. В частности, диапазон и вид входных данных должны быть настолько обобщенными, насколько это допускается базовым алгоритмом. Затем программу нужно тщательно протестировать, чтобы быть уверенным в ее надежности. Для этого нужно подготовить достаточное количество контрольных примеров для проверки диапазона допустимых значений входных данных и определения его границ, обработать эти примеры и зафиксировать результаты. Наконец, развитие программы в программный продукт требует создания подробной документации, с помощью которой каждый мог бы использовать ее, делать исправления и расширять. Я пользуюсь практическим правилом, согласно которому программный продукт стоит, по меньшей мере, втрое дороже, чем просто отлаженная программа с такой же функциональностью.
При пересечении вертикальной границы программа становится компонентом программного комплекса. Последний представляет собой набор взаимодействующих программ, согласованных по функциям и форматам, и вкупе составляющих полное средство для решения больших задач. Чтобы стать частью программного комплекса, синтаксис и семантика ввода и вывода программы должны удовлетворять точно определенным интерфейсам. Программа должна быть также спроектирована таким образом, чтобы использовать заранее оговоренный бюджет ресурсов - объем памяти, устройства ввода/вывода, процессорное время. Наконец, программу нужно протестировать вместе с прочими системными компонентами во всех сочетаниях, которые могут встретиться. Это тестирование может оказаться большим по объему, поскольку количество тестируемых случаев растет экспоненциально. Оно также занимает много времени, так как скрытые ошибки выявляются при неожиданных взаимодействиях отлаживаемых компонентов. Компонент программного комплекса стоит, по крайней мере, втрое дороже, чем автономная программа с теми же функциями. Стоимость может увеличиться, если в системе много компонентов.
В правом нижнем углу рисунка находится системный программный продукт. От обычной программы он отличается во всех перечисленных выше отношениях. И стоит, соответственно, в десять раз дороже. Но это действительно полезный объект, который является целью большинства системных программных проектов".
Как же обстоит дело для программ, написанных на Forth (FORTH-системой)?
Сделать из программы программный продукт? Ну, она изначально должна быть в некоторой степени "программным продуктом", поскольку изначально включает интерактивную составляющую.
А программный компонент? Ну нет! Уж лучше создать свой Forth-комплекс, чем встроить свою Forth-программу в существующий. Операционные системы (ОС) предлагают свои способы - ориентированные на процессы и/или сообщения, но Forth с его BASIC-подобным вводом-выводом не может ни того, ни другого... Нет, конечно можно написать Forth-программу, которая будет взаимодействовать с какой-либо частью ОС по ее законам, но этот интерфей будет лишь "результатом работы", но никак не "естественным общением". А это самое "естественное общение" и есть основопологающая составная Forth-систем. Ведь, "ввод", который ожидает Forth-система - это приказы на естественном Forth-языке, а не просто набор данных, которые нужно обработать...
Программный комплекс, должен быть, скорее, новой машиной, чем доработкой старой.
Наконец, хочется, чтобы системный программный продукт был машиной, пригодной для встраивания в более сложные машины...
Gudleifr- Admin
- Сообщения : 3399
Дата регистрации : 2017-03-29
Страница 1 из 1
Права доступа к этому форуму:
Вы не можете отвечать на сообщения