Уэзерелл. Этюды для программистов. 1982
Страница 2 из 2
Страница 2 из 2 •  1, 2
1, 2
Re: Уэзерелл. Этюды для программистов. 1982
автор Gudleifr Вс Фев 28, 2021 8:06 pm
...
ОПИСАНИЕ КОМАНД
Опишем в этом разделе каждую команду. В первой строке описания приводится краткая справка, состоящая из названия команды, ее формата (RR, RS, IM, CH [Аббревиатуры от Register-Register (регистр-регистр), Register-Storage (регистр-память), IMmediate (непосредственная), CHaracter (байтовая).- Прим. перев.]), шестнадцатеричного кода операции, записи команды на языке ассемблера [На языке ассемблера разряд косвенной адресации задается звездочкой перед полем адреса, как, например, LN, R1*A, R2] и перечисления разрядов регистра признака результата, которые могут командой изменяться. Затем следует словесное описание. Содержимое РПР, устанавливаемое в результате выполнения команды, обозначается символами О, L, G, Е [Аббревиатуры от Overflow (переполнение), Less than (меньше, чем), Greater than (больше, чем), Equal (равно).- Прим. перев.] или Нет (указание на то, что РПР не изменяется).
Load Register RR 00 LR, R1 R2 GLE (Загрузка регистра)
В регистр R1 пересылается содержимое слова по исполнительному адресу. Пересылаемое значение сравнивается с нулем, и в РПР устанавливается соответствующий разряд: G, L или Е [При установке признака результата предполагается, что в операциях отношения слева стоит первый из указанных операндов, а справа - второй. То есть, если выработан признак "меньше, чем", значит, первый операнд меньше второго]. Если исполнительный адрес не попадает на границу слова, происходит ОСОБЫЙ СЛУЧАЙ НЕВЕРНОЙ АДРЕСАЦИИ СЛОВА.
Load RS 20 L, R1 A, R2 GLE (Загрузка)
Эта команда выполняется аналогично команде Load Register с тем отличием, что исполнительный адрес вычисляется по правилу адресации команд типа регистр-память.
Load Immediate IM 40 LI, R1 I GLE (Загрузка непосредственная)
Эта команда выполняется так же, как Load Register, с той разницей, что пересылаемая величина является непосредственным операндом I, при этом его знаковый разряд размножается на 12 битов влево. Особых случаев произойти не может.
Load Character CH 60 LC, R1 А, R2 GE (Загрузка байта)
Регистр R1 обнуляется, и байт по исполнительному адресу записывается в его разряды 24-31. Производится сравнение пересылаемой величины с нулем, и в РПР устанавливаются разряды G или E.
Load Negative Register RR 01 LNR, R1 R2 OGLE (Загрузка регистра отрицательная)
В регистр R1 засылается дополнительный код слова по исполнительному адресу. Результат сравнивается с нулем и устанавливается РПР. При переполнении в РПР устанавливается лишь разряд О. Может иметь место особый случай неверной адресации слова.
Load Negative RS 21 LN, R1 A, R2 OGLE (Загрузка отрицательная)
Эта команда выполняется так же, как Load Negative Register, но исполнительный адрес вычисляется по правилу адресации команд типа регистр-память.
Load Negative Immediate IM 41 LNI, R1 I GLE (Загрузка непосредственная отрицательная)
В регистр R1 помещается 32-разрядное двоичное дополнение 20-разрядного непосредственного операнда I, заданного в дополнительном коде. Переполнение произойти не может. Установка РПР осуществляется сравнением результата с нулем.
Load Negative Character CH 61 LNC, R1 A, R2 LE (Загрузка байта отрицательная)
Байт по исполнительному адресу дополняется слева нулями до 32 разрядов и дополнительный код полученного слова помещается в регистр R1. Переполнения произойти не может. Для установки РПР полученная величина сравнивается с нулем.
Store Register RR 02 STR, R1 R2 GLE (Запись регистра)
Содержимое R1 запоминается в слове по исполнительному адресу. Результат сравнивается с нулем, и устанавливается РПР. Может произойти особый случай неверной адресации слова.
Store RS 22 ST, R1 A, R2 GLE (Запись в память)
Эта команда выполняется так же, как команда Store Register, но исполнительный адрес вычисляется по правилу адресации команд типа регистр-память.
Store Character CH 62 STC, R1 A, R2 GE (Запись в память байта)
Разряды 24-31 регистра R1 помещаются в байт по исполнительному адресу. Для установки РПР занесенная величина сравнивается с нулем.
Swap Register RR 03 SWAPR, R1 R2 GLE (Обмен)
Содержимое регистра R1 и слова по исполнительному адресу меняются местами. Новая величина в R1 сравнивается с нулем, и устанавливается РПР. Может произойти особый случай неверной адресации слова.
Swap RS 23 SWAP, R1 A, R2 GLE (Обмен с памятью)
Эта команда выполняется так же, как команда Swap RegiRegister, но исполнительный адрес вычисляется по правилу адресации команд типа регистр-память.
Swap Character CH 63 SWAPC, R1 А, R2 GE (Обмен с байтом)
Разряды 24-31 регистра R1 меняются местами с байтом по исполнительному адресу. РПР устанавливается при сравнении, нового содержимого R1 с нулем. Разряды с 0-го по 23-й регистра R1 не изменяются.
And Register RR 04 ANDR, R1 R2 GLE (И)
В регистр R1 помещается поразрядное логическое произведение (И) содержимого R1 и слова по исполнительному адресу. Если все разряды результата состоят из единиц, то в РПР устанавливается G, если из нулей - то Е, иначе - L. Может иметь место особый случай неверной адресации слова.
And RS 24 AND, R1 A, R2 GLE (И)
Эта команда выполняется аналогично And Register с тем отличием, что для определения исполнительного адреса используется правило адресации команд типа регистр-память.
And Immediate IM 44 ANDI, R1 I LE (И)
В регистре R1 помещается поразрядное логическое произведение (И) содержимого R1 и непосредственно указанной величины I, дополненной слева 12 нулевыми разрядами. РПР устанавливается так же, как в команде And Register.
And Character CH 64 ANDC, R1 A, R2 GLE (И)
В регистре R1 разряды 24-31 заменяются их логическим произведением на байт по исполнительному адресу. Разряды 0-23 регистра R1 не изменяются. РПР устанавливается так же, как в команде And Register.
Or Register RR 05 ORR, R1 R2 GLE (ИЛИ) Эта команда выполняется так же, как And Register, но логическое И заменяется логическим ИЛИ.
Or RS 25 OR, R1 A, R2 GLE (ИЛИ) Эта команда выполняется так же, как Апd, но магическое И заменяется логическим ИЛИ.
Or Immediate IM 45 ORI, R1 I GLE (ИЛИ)
Эта команда выполняется также, как And Immediate, но логическое И заменяется логическим ИЛИ.
Or Character CH 65 ORC, R1 A, R2 (ИЛИ) Эта команда выполняется так же, как And Character, но логическое И заменяется логическим ИЛИ.
Exclusive Or Register RR 06 XORR, R1 R2 GLE (Исключающее ИЛИ)
Эта команда выполняется так же, как And Register, но логическое И заменяется исключающим ИЛИ.
Exclusive Or RS 26 XOR, R1 A, R2 GLE (Исключающее ИЛИ)
Эта команда выполняется так же, как And, но логическое И заменяется исключающим ИЛИ.
Exclusive Or Immediate IM 46 XORI, R1 I GLE (Исключающее
ИЛИ)
Эта команда выполняется так же, как And Immediate, но логическое И заменяется исключающим ИЛИ.
Exclusive Or Character CH 66 XORC, R1 A, R2 GLE (Исключающее ИЛИ)
Эта команда выполняется так же, как And Character, но логическое И заменяется исключающим ИЛИ.
Not Register RR 07 NOTR, R1 R2 GLE (Отрицание)
Эта команда выполняется так же, как And Register, но логическое И заменяется логическим отрицанием второго операнда. Исходное содержимое R1 игнорируется.
Not RS 27 NOT, R1 A, R2 GLE (Отрицание)
Эта команда выполняется так же, как And, но логическое И заменяется логическим отрицанием второго операнда. Исходное содержимое R1 игнорируется.
Not Immediate IM 47 NOTI, R1 I GLE (Отрицание)
Эта команда выполняется так же, как And Immediate, но логическое И заменяется логическим отрицанием расширенного второго операнда. Исходное содержимое R1 игнорируется.
Not Character CH 67 NOTC, R1 A, R2 GLE (Отрицание)
Эта команда выполняется так же, как And Character, но логическое И заменяется логическим отрицанием второго операнда. Содержимое разрядов 24-31 регистра R1 игнорируется.
Branch Conditions Set Register RR 08 BCSR, M1 R2 Нет (Условный переход по единице)
Если логическое произведение содержимого РПР и 4-разрядной маски M1 не равно нулю, содержимое САК замещается исполнительным адресом.
Branch Conditions Set RS 28 BCS, M1 A, R2 Нет (Условный переход по единице)
Эта команда выполняется так же как Branch Conditions Set Register, с тем отличием, что исполнительный адрес вычисляется с помощью правила адресации команд типа регистр-память.
Branch Conditions Reset Register RR 09 BCRR, M1 R2 Нет (Условный переход по нулю)
Если логическое произведение содержимого РПР и 4-разрядной маски Ml равно нулю, содержимое САК замещается исполнительным адресом.
Branch Conditions Reset RS 29 BCR, M1 A, R2 Нет (Условный переход по нулю)
Эта команда выполняется так же, как Branch Conditions Reset Register, с тем отличием, что исполнительный адрес вычисляется с помощью правила адресации команд типа регистр-память.
Branch and Link Register RR 0A BALR, R1 R2 Нет (Переход с возвратом)
Текущее содержимое САК засылается в регистр R1, а исполнительный адрес команды помещается в САК. Если признак косвенной адресации не задан, исполнительный адрес равен указателю регистра R2, умноженному на 4.
Branch and Link RS 2A BAL, R1 A, R2 Нет (Переход с возвратом)
Текущее содержимое САК заносится в регистр R1, а в САК засылается исполнительный адрес команды.
Save Condition Register RR 0B SACR, M1 R2 Нет (Сохранение состояния) Если логическое произведение И содержимого РПР и 4-разрядного поля маски M1 отлично от нуля, по исполнительному адресу записывается слово, состоящее из всех единиц; в противном случае записывается нулевое слово. Может иметь место особый случай неверной адресации слова.
Save Condition RS 2B SAC, M1 А, R2 Нет (Сохранение состояния)
Эта команда выполняется так же, как команда Save CondiCondition Register, с тем отличием, что исполнительный адрес вычисляется с помощью правила адресации команд типа регистр-память.
Save Condition Character CH 6B SACC, M1 A, R2 Нет (Сохранение состояния)
Если логическое произведение И содержимого РПР и 4-разрядного поля маски M1 отлично от нуля, по исполнительному адресу записывается байт, состоящий из всех единиц; в противном случае записывается нулевой байт.
Compare Register RR 0C CR, R1 R2 GLE (Сравнение)
В результате арифметического сравнения содержимого регистра R1 и слова по исполнительному адресу в РПР устанавливается соответствующий разряд: G, L или E. Может иметь место особый случай неверной адресации слова.
Compare RS 2C С, R1 A, R2 GLE (Сравнение)
Эта команда выполняется так же, как Compare Register, с тем отличием, что исполнительный адрес вычисляется по правилу адресации команд типа регистр-память.
Compare Immediate IM 4C CI, R1 I GLE (Сравнение непосредственное) Содержимое 32-разрядного регистра R1 арифметически сравнивается с полным словом, образованным из непосредственного операнда размножением его знакового разряда на 12 позиций влево. Вырабатывается соответствующий признак результата, и разряд G, L или Е устанавливается в РПР.
Compare Character CH 6C CC, R1 A, R2 GLE (Сравнение байтов)
Содержимое разрядов 24-31 регистра R1 сравнивается как 8-разрядное целое положительное число с байтом по исполнительному адресу. Вырабатывается соответствующий признак результата, и в РПР устанавливается разряд G, L или E.
Compare Character String RR 0E CCS, M1 R2 GLE (Сравнение цепочки байтов)
Указатель регистра R2 обозначает пару регистров R2 и (R2+1) mod 16 (второй регистр будем везде называть R2+1). В двойном слове, образованном парой R2 и R+1 должно содержаться описание цепочки, а именно в разрядах 16-31 регистра R2 указывается адрес байта A1, в разрядах 0-15 регистра R2+1 - длина цепочки L и в разрядах 16-31 регистра R2+1 - адрес байта А2. Для выполнения команды величины A1, A2 и L помещаются во внутренние регистры, РПР обнуляется и E-бит РПР устанавливается в единицу. Затем отрабатывает следующий цикл.
1. Если L=0, то разряды 0-15 обоих регистров обнуляются, в 16-31-й разряды R2 из внутренних регистров переносится A1, а в 16-31-й разряды R2+1 переносится A2, и выполнение команды заканчивается.
2. Байты по A1 и A2 сравниваются как 8-разрядные целые числа, и в РПР устанавливается соответствующий признак результата.
3. Если E-бит РПР не равен единице, то 0-15-й разряды регистра R2 обнуляются, а из внутренних регистров в 16-31-й разряды R2 пересылается A1, в 0-15-й разряды R2+1 - длина L и в 16-31-й разряды R2+1 - адрес A2, и команда завершается.
4. L уменьшается на 1, адрес A1 увеличивается на величину маски M1, представляющую собой 4-разрядное целое в дополнительном коде, A2 увеличивается на 1, и цикл повторяется с первого шага.
Move Character String RR 0F MCS, M1 R2 Нет (Пересылка цепочки байтов)
В двойном слове R2 и (R2+1) mod 16 содержится описание цепочки в виде, описанном в команде Compare Character String. Поля L, A1 и A2 загружаются во внутренние регистры. Затем выполняется цикл.
1. Если L = 0, разряды 0-15 регистров R2 и R2+1 очищаются, в 16-31-й разряды R2 помещается текущее A1, в 16-31-й разряды R2+1 - значение A2, и выполнение команды завершается.
2. Байт по адресу A1 пересылается в байт по A2.
3. L уменьшается на 1, а A2 увеличивается на 1.
4. A1 увеличивается на величину маски M1, рассматриваемую как 4-разрядное целое число в дополнительном коде, и цикл возвращается к первому шагу.
Supervisor Call RS 2E SVC, R1 A, R2 Нет (Обращение к супервизору)
Выполнение программы прерывается, и управление передается в управляющую программу супервизора.
Execute RS 2F EX, R1 A, R2 Нет (Выполнить)
Выполняется команда, содержащаяся по исполнительному адресу. Результаты ее исполнения становятся таковыми для данной команды Execute. Если исполнительный адрес команды Execute не четный, имеет место ОСОБЫЙ СЛУЧАЙ НЕКОРРЕКТНОСТИ КОМАНДЫ EXECUTE. Глубина вложений команды Execute может быть любой. Заметим, что изменение САК происходит только в случае, когда это явным образом производится в подчиненной команде.
Load Adress RS 4E LA, R1 A, R2 Нет (Загрузка адреса)
Исполнительный адрес команды помещается в регистр R1.
Load Multiple RS 6E LM, R1 A, R2 Нет (Загрузка групповая)
В регистры от R1 до R2 загружается содержимое последовательных слов памяти, начиная со слова по исполнительному адресу (исполнительный адрес вычисляется в предположении, что указан нулевой индекс-регистр). Если R2 меньше, чем R1, то загружаются регистры от R1 до 15 и от 0 до R2. Может иметь место особый случай неверной адресации слова.
Store Multiple RS 6F STM, R1 A, R2 Нет (Запись групповая)
Содержимое регистров от R1 до R2 записывается в последовательные слова памяти, начиная со слова по исполнительному адресу (исполнительный адрес вычисляется в предположении, что указан нулевой индекс-регистр). Если R2 меньше R1, то записывается содержимое регистров от R1 до 15 и от 0 до R2. Может иметь место особый случай неверной адресации слова.
Add Register RR 10 AR, R1 R2 OGLE (Сложение)
Слово в регистре R1 складывается со словом по исполнительному адресу, и результат помещается в R1. Для установки РПР сумма сравнивается с нулем. В случае переполнения в РПР устанавливается лишь О-бит. Может иметь место особый случай неверной адресации слова.
Add RS 30 A, R1 A, R2 OGLE (Сложение)
Эта команда выполняется так же, как Add Register, с тем отличием, что исполнительный адрес вычисляется по правилу адресации команд типа регистр-память.
Add Immediate IM 50 A I, R1 I OGLE (Сложение непосредственное)
20-разрядный непосредственный операнд I, заданный в дополнительном коде, складывается с содержимым регистра R1, и сумма помещается в R1. Для установки РПР сумма сравнивается с нулем. При переполнении в РПР устанавливается только О-бит.
Add Character CH 70 AC, R1 A, R2 OGLE (Сложение байта)
Байт по исполнительному адресу дополняется слева 24 нулевыми разрядами и складывается с содержимым регистра R1, причем сумма помещается в R1. Для установки РПР сумма сравнивается с нулем. При переполнении в РПР устанавливается только О-бит.
Subtract Register RR 11 SR, R1 R2 OGLE (Вычитание)
Слово по исполнительному адресу (ВЫЧИТАЕМОЕ) вычитается из содержимого регистра R1 (УМЕНЬШАЕМОЕ), и разность записывается в R1. Для установки РПР разность сравнивается с нулем. При переполнении в РПР устанавливается только О-бит. Может иметь место особый случай неверной адресации слова.
Subtract RS 31 S, R1 A, R2 OGLE (Вычитание)
Эта команда выполняется так же, как Subtract Register, с тем отличием, что исполнительный адрес вычисляется по правилу адресации команд типа регистр-память.
Subtract Immediate IM 51 SI, R1 I OGLE (Вычитание непосредственное)
Из содержимого регистра R1 (уменьшаемое) вычитается 20-разрядный непосредственный операнд (вычитаемое), рассматриваемый как целое в дополнительном коде, и результат записывается в регистр R1. Для установки РПР разность сравнивается с нулем. При переполнении в РПР устанавливается только О-бит.
Subtract Character CH 71 SC, R1 A, R2 OGLE (Вычитание байта)
Из содержимого регистра R1 (уменьшаемое) вычитается байт по исполнительному адресу, дополненный слева 24 нулевыми разрядами (вычитаемое), который трактуется как положительное целое число. Результат записывается в R1. Для установки РПР разность сравнивается с нулем. При переполнении в РПР устанавливается только О-бит.
...
ОПИСАНИЕ КОМАНД
Опишем в этом разделе каждую команду. В первой строке описания приводится краткая справка, состоящая из названия команды, ее формата (RR, RS, IM, CH [Аббревиатуры от Register-Register (регистр-регистр), Register-Storage (регистр-память), IMmediate (непосредственная), CHaracter (байтовая).- Прим. перев.]), шестнадцатеричного кода операции, записи команды на языке ассемблера [На языке ассемблера разряд косвенной адресации задается звездочкой перед полем адреса, как, например, LN, R1*A, R2] и перечисления разрядов регистра признака результата, которые могут командой изменяться. Затем следует словесное описание. Содержимое РПР, устанавливаемое в результате выполнения команды, обозначается символами О, L, G, Е [Аббревиатуры от Overflow (переполнение), Less than (меньше, чем), Greater than (больше, чем), Equal (равно).- Прим. перев.] или Нет (указание на то, что РПР не изменяется).
Load Register RR 00 LR, R1 R2 GLE (Загрузка регистра)
В регистр R1 пересылается содержимое слова по исполнительному адресу. Пересылаемое значение сравнивается с нулем, и в РПР устанавливается соответствующий разряд: G, L или Е [При установке признака результата предполагается, что в операциях отношения слева стоит первый из указанных операндов, а справа - второй. То есть, если выработан признак "меньше, чем", значит, первый операнд меньше второго]. Если исполнительный адрес не попадает на границу слова, происходит ОСОБЫЙ СЛУЧАЙ НЕВЕРНОЙ АДРЕСАЦИИ СЛОВА.
Load RS 20 L, R1 A, R2 GLE (Загрузка)
Эта команда выполняется аналогично команде Load Register с тем отличием, что исполнительный адрес вычисляется по правилу адресации команд типа регистр-память.
Load Immediate IM 40 LI, R1 I GLE (Загрузка непосредственная)
Эта команда выполняется так же, как Load Register, с той разницей, что пересылаемая величина является непосредственным операндом I, при этом его знаковый разряд размножается на 12 битов влево. Особых случаев произойти не может.
Load Character CH 60 LC, R1 А, R2 GE (Загрузка байта)
Регистр R1 обнуляется, и байт по исполнительному адресу записывается в его разряды 24-31. Производится сравнение пересылаемой величины с нулем, и в РПР устанавливаются разряды G или E.
Load Negative Register RR 01 LNR, R1 R2 OGLE (Загрузка регистра отрицательная)
В регистр R1 засылается дополнительный код слова по исполнительному адресу. Результат сравнивается с нулем и устанавливается РПР. При переполнении в РПР устанавливается лишь разряд О. Может иметь место особый случай неверной адресации слова.
Load Negative RS 21 LN, R1 A, R2 OGLE (Загрузка отрицательная)
Эта команда выполняется так же, как Load Negative Register, но исполнительный адрес вычисляется по правилу адресации команд типа регистр-память.
Load Negative Immediate IM 41 LNI, R1 I GLE (Загрузка непосредственная отрицательная)
В регистр R1 помещается 32-разрядное двоичное дополнение 20-разрядного непосредственного операнда I, заданного в дополнительном коде. Переполнение произойти не может. Установка РПР осуществляется сравнением результата с нулем.
Load Negative Character CH 61 LNC, R1 A, R2 LE (Загрузка байта отрицательная)
Байт по исполнительному адресу дополняется слева нулями до 32 разрядов и дополнительный код полученного слова помещается в регистр R1. Переполнения произойти не может. Для установки РПР полученная величина сравнивается с нулем.
Store Register RR 02 STR, R1 R2 GLE (Запись регистра)
Содержимое R1 запоминается в слове по исполнительному адресу. Результат сравнивается с нулем, и устанавливается РПР. Может произойти особый случай неверной адресации слова.
Store RS 22 ST, R1 A, R2 GLE (Запись в память)
Эта команда выполняется так же, как команда Store Register, но исполнительный адрес вычисляется по правилу адресации команд типа регистр-память.
Store Character CH 62 STC, R1 A, R2 GE (Запись в память байта)
Разряды 24-31 регистра R1 помещаются в байт по исполнительному адресу. Для установки РПР занесенная величина сравнивается с нулем.
Swap Register RR 03 SWAPR, R1 R2 GLE (Обмен)
Содержимое регистра R1 и слова по исполнительному адресу меняются местами. Новая величина в R1 сравнивается с нулем, и устанавливается РПР. Может произойти особый случай неверной адресации слова.
Swap RS 23 SWAP, R1 A, R2 GLE (Обмен с памятью)
Эта команда выполняется так же, как команда Swap RegiRegister, но исполнительный адрес вычисляется по правилу адресации команд типа регистр-память.
Swap Character CH 63 SWAPC, R1 А, R2 GE (Обмен с байтом)
Разряды 24-31 регистра R1 меняются местами с байтом по исполнительному адресу. РПР устанавливается при сравнении, нового содержимого R1 с нулем. Разряды с 0-го по 23-й регистра R1 не изменяются.
And Register RR 04 ANDR, R1 R2 GLE (И)
В регистр R1 помещается поразрядное логическое произведение (И) содержимого R1 и слова по исполнительному адресу. Если все разряды результата состоят из единиц, то в РПР устанавливается G, если из нулей - то Е, иначе - L. Может иметь место особый случай неверной адресации слова.
And RS 24 AND, R1 A, R2 GLE (И)
Эта команда выполняется аналогично And Register с тем отличием, что для определения исполнительного адреса используется правило адресации команд типа регистр-память.
And Immediate IM 44 ANDI, R1 I LE (И)
В регистре R1 помещается поразрядное логическое произведение (И) содержимого R1 и непосредственно указанной величины I, дополненной слева 12 нулевыми разрядами. РПР устанавливается так же, как в команде And Register.
And Character CH 64 ANDC, R1 A, R2 GLE (И)
В регистре R1 разряды 24-31 заменяются их логическим произведением на байт по исполнительному адресу. Разряды 0-23 регистра R1 не изменяются. РПР устанавливается так же, как в команде And Register.
Or Register RR 05 ORR, R1 R2 GLE (ИЛИ) Эта команда выполняется так же, как And Register, но логическое И заменяется логическим ИЛИ.
Or RS 25 OR, R1 A, R2 GLE (ИЛИ) Эта команда выполняется так же, как Апd, но магическое И заменяется логическим ИЛИ.
Or Immediate IM 45 ORI, R1 I GLE (ИЛИ)
Эта команда выполняется также, как And Immediate, но логическое И заменяется логическим ИЛИ.
Or Character CH 65 ORC, R1 A, R2 (ИЛИ) Эта команда выполняется так же, как And Character, но логическое И заменяется логическим ИЛИ.
Exclusive Or Register RR 06 XORR, R1 R2 GLE (Исключающее ИЛИ)
Эта команда выполняется так же, как And Register, но логическое И заменяется исключающим ИЛИ.
Exclusive Or RS 26 XOR, R1 A, R2 GLE (Исключающее ИЛИ)
Эта команда выполняется так же, как And, но логическое И заменяется исключающим ИЛИ.
Exclusive Or Immediate IM 46 XORI, R1 I GLE (Исключающее
ИЛИ)
Эта команда выполняется так же, как And Immediate, но логическое И заменяется исключающим ИЛИ.
Exclusive Or Character CH 66 XORC, R1 A, R2 GLE (Исключающее ИЛИ)
Эта команда выполняется так же, как And Character, но логическое И заменяется исключающим ИЛИ.
Not Register RR 07 NOTR, R1 R2 GLE (Отрицание)
Эта команда выполняется так же, как And Register, но логическое И заменяется логическим отрицанием второго операнда. Исходное содержимое R1 игнорируется.
Not RS 27 NOT, R1 A, R2 GLE (Отрицание)
Эта команда выполняется так же, как And, но логическое И заменяется логическим отрицанием второго операнда. Исходное содержимое R1 игнорируется.
Not Immediate IM 47 NOTI, R1 I GLE (Отрицание)
Эта команда выполняется так же, как And Immediate, но логическое И заменяется логическим отрицанием расширенного второго операнда. Исходное содержимое R1 игнорируется.
Not Character CH 67 NOTC, R1 A, R2 GLE (Отрицание)
Эта команда выполняется так же, как And Character, но логическое И заменяется логическим отрицанием второго операнда. Содержимое разрядов 24-31 регистра R1 игнорируется.
Branch Conditions Set Register RR 08 BCSR, M1 R2 Нет (Условный переход по единице)
Если логическое произведение содержимого РПР и 4-разрядной маски M1 не равно нулю, содержимое САК замещается исполнительным адресом.
Branch Conditions Set RS 28 BCS, M1 A, R2 Нет (Условный переход по единице)
Эта команда выполняется так же как Branch Conditions Set Register, с тем отличием, что исполнительный адрес вычисляется с помощью правила адресации команд типа регистр-память.
Branch Conditions Reset Register RR 09 BCRR, M1 R2 Нет (Условный переход по нулю)
Если логическое произведение содержимого РПР и 4-разрядной маски Ml равно нулю, содержимое САК замещается исполнительным адресом.
Branch Conditions Reset RS 29 BCR, M1 A, R2 Нет (Условный переход по нулю)
Эта команда выполняется так же, как Branch Conditions Reset Register, с тем отличием, что исполнительный адрес вычисляется с помощью правила адресации команд типа регистр-память.
Branch and Link Register RR 0A BALR, R1 R2 Нет (Переход с возвратом)
Текущее содержимое САК засылается в регистр R1, а исполнительный адрес команды помещается в САК. Если признак косвенной адресации не задан, исполнительный адрес равен указателю регистра R2, умноженному на 4.
Branch and Link RS 2A BAL, R1 A, R2 Нет (Переход с возвратом)
Текущее содержимое САК заносится в регистр R1, а в САК засылается исполнительный адрес команды.
Save Condition Register RR 0B SACR, M1 R2 Нет (Сохранение состояния) Если логическое произведение И содержимого РПР и 4-разрядного поля маски M1 отлично от нуля, по исполнительному адресу записывается слово, состоящее из всех единиц; в противном случае записывается нулевое слово. Может иметь место особый случай неверной адресации слова.
Save Condition RS 2B SAC, M1 А, R2 Нет (Сохранение состояния)
Эта команда выполняется так же, как команда Save CondiCondition Register, с тем отличием, что исполнительный адрес вычисляется с помощью правила адресации команд типа регистр-память.
Save Condition Character CH 6B SACC, M1 A, R2 Нет (Сохранение состояния)
Если логическое произведение И содержимого РПР и 4-разрядного поля маски M1 отлично от нуля, по исполнительному адресу записывается байт, состоящий из всех единиц; в противном случае записывается нулевой байт.
Compare Register RR 0C CR, R1 R2 GLE (Сравнение)
В результате арифметического сравнения содержимого регистра R1 и слова по исполнительному адресу в РПР устанавливается соответствующий разряд: G, L или E. Может иметь место особый случай неверной адресации слова.
Compare RS 2C С, R1 A, R2 GLE (Сравнение)
Эта команда выполняется так же, как Compare Register, с тем отличием, что исполнительный адрес вычисляется по правилу адресации команд типа регистр-память.
Compare Immediate IM 4C CI, R1 I GLE (Сравнение непосредственное) Содержимое 32-разрядного регистра R1 арифметически сравнивается с полным словом, образованным из непосредственного операнда размножением его знакового разряда на 12 позиций влево. Вырабатывается соответствующий признак результата, и разряд G, L или Е устанавливается в РПР.
Compare Character CH 6C CC, R1 A, R2 GLE (Сравнение байтов)
Содержимое разрядов 24-31 регистра R1 сравнивается как 8-разрядное целое положительное число с байтом по исполнительному адресу. Вырабатывается соответствующий признак результата, и в РПР устанавливается разряд G, L или E.
Compare Character String RR 0E CCS, M1 R2 GLE (Сравнение цепочки байтов)
Указатель регистра R2 обозначает пару регистров R2 и (R2+1) mod 16 (второй регистр будем везде называть R2+1). В двойном слове, образованном парой R2 и R+1 должно содержаться описание цепочки, а именно в разрядах 16-31 регистра R2 указывается адрес байта A1, в разрядах 0-15 регистра R2+1 - длина цепочки L и в разрядах 16-31 регистра R2+1 - адрес байта А2. Для выполнения команды величины A1, A2 и L помещаются во внутренние регистры, РПР обнуляется и E-бит РПР устанавливается в единицу. Затем отрабатывает следующий цикл.
1. Если L=0, то разряды 0-15 обоих регистров обнуляются, в 16-31-й разряды R2 из внутренних регистров переносится A1, а в 16-31-й разряды R2+1 переносится A2, и выполнение команды заканчивается.
2. Байты по A1 и A2 сравниваются как 8-разрядные целые числа, и в РПР устанавливается соответствующий признак результата.
3. Если E-бит РПР не равен единице, то 0-15-й разряды регистра R2 обнуляются, а из внутренних регистров в 16-31-й разряды R2 пересылается A1, в 0-15-й разряды R2+1 - длина L и в 16-31-й разряды R2+1 - адрес A2, и команда завершается.
4. L уменьшается на 1, адрес A1 увеличивается на величину маски M1, представляющую собой 4-разрядное целое в дополнительном коде, A2 увеличивается на 1, и цикл повторяется с первого шага.
Move Character String RR 0F MCS, M1 R2 Нет (Пересылка цепочки байтов)
В двойном слове R2 и (R2+1) mod 16 содержится описание цепочки в виде, описанном в команде Compare Character String. Поля L, A1 и A2 загружаются во внутренние регистры. Затем выполняется цикл.
1. Если L = 0, разряды 0-15 регистров R2 и R2+1 очищаются, в 16-31-й разряды R2 помещается текущее A1, в 16-31-й разряды R2+1 - значение A2, и выполнение команды завершается.
2. Байт по адресу A1 пересылается в байт по A2.
3. L уменьшается на 1, а A2 увеличивается на 1.
4. A1 увеличивается на величину маски M1, рассматриваемую как 4-разрядное целое число в дополнительном коде, и цикл возвращается к первому шагу.
Supervisor Call RS 2E SVC, R1 A, R2 Нет (Обращение к супервизору)
Выполнение программы прерывается, и управление передается в управляющую программу супервизора.
Execute RS 2F EX, R1 A, R2 Нет (Выполнить)
Выполняется команда, содержащаяся по исполнительному адресу. Результаты ее исполнения становятся таковыми для данной команды Execute. Если исполнительный адрес команды Execute не четный, имеет место ОСОБЫЙ СЛУЧАЙ НЕКОРРЕКТНОСТИ КОМАНДЫ EXECUTE. Глубина вложений команды Execute может быть любой. Заметим, что изменение САК происходит только в случае, когда это явным образом производится в подчиненной команде.
Load Adress RS 4E LA, R1 A, R2 Нет (Загрузка адреса)
Исполнительный адрес команды помещается в регистр R1.
Load Multiple RS 6E LM, R1 A, R2 Нет (Загрузка групповая)
В регистры от R1 до R2 загружается содержимое последовательных слов памяти, начиная со слова по исполнительному адресу (исполнительный адрес вычисляется в предположении, что указан нулевой индекс-регистр). Если R2 меньше, чем R1, то загружаются регистры от R1 до 15 и от 0 до R2. Может иметь место особый случай неверной адресации слова.
Store Multiple RS 6F STM, R1 A, R2 Нет (Запись групповая)
Содержимое регистров от R1 до R2 записывается в последовательные слова памяти, начиная со слова по исполнительному адресу (исполнительный адрес вычисляется в предположении, что указан нулевой индекс-регистр). Если R2 меньше R1, то записывается содержимое регистров от R1 до 15 и от 0 до R2. Может иметь место особый случай неверной адресации слова.
Add Register RR 10 AR, R1 R2 OGLE (Сложение)
Слово в регистре R1 складывается со словом по исполнительному адресу, и результат помещается в R1. Для установки РПР сумма сравнивается с нулем. В случае переполнения в РПР устанавливается лишь О-бит. Может иметь место особый случай неверной адресации слова.
Add RS 30 A, R1 A, R2 OGLE (Сложение)
Эта команда выполняется так же, как Add Register, с тем отличием, что исполнительный адрес вычисляется по правилу адресации команд типа регистр-память.
Add Immediate IM 50 A I, R1 I OGLE (Сложение непосредственное)
20-разрядный непосредственный операнд I, заданный в дополнительном коде, складывается с содержимым регистра R1, и сумма помещается в R1. Для установки РПР сумма сравнивается с нулем. При переполнении в РПР устанавливается только О-бит.
Add Character CH 70 AC, R1 A, R2 OGLE (Сложение байта)
Байт по исполнительному адресу дополняется слева 24 нулевыми разрядами и складывается с содержимым регистра R1, причем сумма помещается в R1. Для установки РПР сумма сравнивается с нулем. При переполнении в РПР устанавливается только О-бит.
Subtract Register RR 11 SR, R1 R2 OGLE (Вычитание)
Слово по исполнительному адресу (ВЫЧИТАЕМОЕ) вычитается из содержимого регистра R1 (УМЕНЬШАЕМОЕ), и разность записывается в R1. Для установки РПР разность сравнивается с нулем. При переполнении в РПР устанавливается только О-бит. Может иметь место особый случай неверной адресации слова.
Subtract RS 31 S, R1 A, R2 OGLE (Вычитание)
Эта команда выполняется так же, как Subtract Register, с тем отличием, что исполнительный адрес вычисляется по правилу адресации команд типа регистр-память.
Subtract Immediate IM 51 SI, R1 I OGLE (Вычитание непосредственное)
Из содержимого регистра R1 (уменьшаемое) вычитается 20-разрядный непосредственный операнд (вычитаемое), рассматриваемый как целое в дополнительном коде, и результат записывается в регистр R1. Для установки РПР разность сравнивается с нулем. При переполнении в РПР устанавливается только О-бит.
Subtract Character CH 71 SC, R1 A, R2 OGLE (Вычитание байта)
Из содержимого регистра R1 (уменьшаемое) вычитается байт по исполнительному адресу, дополненный слева 24 нулевыми разрядами (вычитаемое), который трактуется как положительное целое число. Результат записывается в R1. Для установки РПР разность сравнивается с нулем. При переполнении в РПР устанавливается только О-бит.
...

Gudleifr- Admin
- Сообщения : 3252
Дата регистрации : 2017-03-29
Re: Уэзерелл. Этюды для программистов. 1982
автор Gudleifr Вс Фев 28, 2021 8:10 pm
...
Reverse Subtract Register RR 12 RSR, R1 R2 OGLE (Вычитание обратное)
Эта команда выполняется так же, как команда Subtract Register, с тем отличием, что вычитаемое и уменьшаемое меняются ролями [Хотя во всех командах Reverse значения двух операндов и меняются ролями, результат записывается туда же, куда и раньше..
Reverse Subtract RS 32 RS, R1 A, R2 OGLE (Вычитание обратное)
Эта команда выполняется так же, как Subtract, с тем отличием, что вычитаемое и уменьшаемое меняются ролями.
Reverse Subtract Immediate IM 52 RS I, R1 I OGLE (Вычитание непосредственное обратное)
Эта команда выполняется так же, как Subtract Immediate, с тем отличием, что вычитаемое и уменьшаемое меняются ролями.
Reverse Subtract Character CH 72 RSC, R1 A, R2 OGLE (Вычитание байта обратное)
Эта команда выполняется так же, как Subtract Character, с тем отличием, что вычитаемое и уменьшаемое меняются ролями.
Multiply Register RR 13 MR, R1 R2 OGLE (Умножение)
Перемножаются содержимое регистра R1 и слова по исполнительному адресу; младшие 32 разряда произведения записываются в регистр R1. Для установки РПР результат в R1 сравнивается с нулем. При переполнении в РПР устанавливается только О-бит. Может иметь место особый случай неверной адресации слова.
Multiply RS 33 M, R1 A, R2 OGLE (Умножение)
Эта команда выполняется так же, как Multiply Register, с тем отличием, что исполнительный адрес вычисляется по правилу адресации команд типа регистр-память.
Multiply Immediate IM 53 MI, R1 I OGLE (Умножение непосредственное)
В регистр RI записываются младшие 32 разряда произведения содержимого регистра R1 на 20-разрядный непосредственный операнд I. Для установки РПР произведение в R1 сравнивается с нулем. При переполнении в РПР устанавливается только О-бит.
Multiply Character CH 73 МС, R1 А, R2 OGLE (Умножение байта)
В регистр R1 записываются младшие 32 разряда произведения содержимого регистра R1 на 8-разрядное положительное целое число, расположенное в байте по исполнительному адресу. Для установки РПР величина в R1 сравнивается с нулем. При переполнении в РПР устанавливается только О-бит.
Divide Register RR 14 DR, R1 R2 OGLE (Деление)
Содержимое регистра R1 (делимое) делится на слово по исполнительному адресу (делитель), и частное записывается в регистр R1. Деление определено таким образом, что остаток получается неотрицательным. Для установки РПР частное сравнивается с нулем. При переполнении в РПР устанавливается только О-бит. Может иметь место особый случай неверной адресации слова. Если делитель равен нулю, то происходит ОСОБЫЙ СЛУЧАЙ ДЕЛЕНИЯ НА НУЛЬ и регистр R1 не меняется.
Divide RS 34 D, R1 A, R2 OGLE (Деление)
Эта команда выполняется так же, как Divide Register, с тем отличием, что исполнительный адрес вычисляется по правилу адресации команд типа регистр-память.
Divide Immediate IM 54 DI, R1 I OGLE (Деление непосредственное)
В регистр R1 записывается частное от деления содержимого R1 (делимое) на значение 20-разрядного непосредственного операнда I в дополнительном коде. Операция определяется таким образом, чтобы остаток от деления был неотрицательным. Для установки РПР частное сравнивается с нулем. При переполнении в РПР устанавливается только О-бит. Если делитель равен нулю, то происходит особый случай деления на нуль и регистр R1 не изменяется.
Divide Character CH 74 DC, R1 A, R2 GLE (Деление на байт)
В регистр R1 записывается частное от деления содержимого регистра R1 (делимое) на положительное 8-разрядное целое число в байте по исполнительному адресу (делитель). Частное определяется таким образом, чтобы остаток от деления был неотрицательным. Для установки РПР частное сравнивается с нулем. Если делитель равен нулю, то происходит особый случай деления на нуль и регистр R1 не изменяется. Переполнение невозможно.
Reverse Divide Register RR 15 RDR, R1 R2 OGLE (Деление обратное)
Эта команда выполняется так же, как Divide Register, с тем отличием, что делимое и делитель меняются ролями.
Reverse Divide RS 35 RD, R1 A, R2 OGLE (Деление обратное)
Эта команда выполняется так же, как Divide, с тем отличием, что делимое и делитель меняются ролями.
Reverse Divide Immediate IM 55 RDI, R1 I GLE (Деление непосредственное обратное)
Эта команда выполняется так же, как Divide Immediate, с тем отличием; что делимое и делитель меняются ролями.
Reverse Divide Character CH 75 RDC, R1 A, R2 GLE (Деление на байт обратное)
Эта команда выполняется так же, как Divide Character, с тем отличием, что делимое и делитель меняются ролями.
Remainder Register RR 16 REMR, R1 R2 GE (Остаток от деления)
В регистр R1 записывается неотрицательный остаток от деления содержимого регистра R1 (делимое) на слово по исполнительному адресу (делитель). Для установки РПР остаток сравнивается с нулем. Может иметь место особый случай неверной адресации слова. Если делитель равен нулю, происходит особый случай деления на нуль и регистр R1 не изменяется.
Remainder RS 36 REM, R1 А, R2 GE (Остаток от деления)
Эта команда выполняется так же, как Remainder Register, с тем отличием, что исполнительный адрес вычисляется по правилу адресации команд типа регистр-память.
Remainder Immediate IM 56 REMI, R1 I GE (Остаток от деления непосредственного)
В регистр R1 записывается неотрицательный остаток от деления содержимого R1 (делимое) на значение 20-разрядного непосредственного операнда I в дополнительном коде (делитель). Для установки РПР остаток сравнивается с нулем. Если делитель равен нулю, происходит особый случай деления на нуль и регистр R1 не изменяется.
Remainder Character CH 76 REMC, R1 A, R2 GE (Остаток от деления на байт)
В регистр R1 записывается неотрицательный остаток от деления содержимого регистра R1 (делимое) на положительное 8-разрядное целое число (делитель) в байте по исполнительному адресу. Для установки РПР остаток сравнивается с нулем. Если делитель равен нулю, происходит особый случай деления на нуль и регистр R1 не изменяется.
Reverse Remainder Register RR 17 RREMR, R1 R2 GE (Остаток от деления обратного)
Эта команда выполняется так же, как Remainder Register, с тем отличием, что делимое и делитель меняются ролями.
Reverse Remainder RS 37 RREM, R1 A, R2 GE (Остаток от деления обратного)
Эта команда выполняется так же, как Remainder, с тем отличием, что делимое и делитель меняются ролями.
Reverse Remainder Immediate IM 57 RREMI, R1 I GE (Остаток от деления непосредственного обратного)
Эта команда выполняется так же, как Remainder Immediate, с тем отличием, что делимое и делитель меняются ролями.
Reverse Remainder Character CH 77 RREMC, R1 A, R2 GE (Остаток от деления на байт обратного)
Эта команда выполняется так же, как Remainder Character, с тем отличием, что делимое и делитель меняются ролями.
Real Add Register RR 18 FAR, R1 R2 GLE (Сложение вещественное)
Величина в регистре R1 складывается с вещественным числом по исполнительному адресу, и результат записывается в регистр R1. Для установки РПР сумма сравнивается с нулем. Могут иметь место особые случаи и неверной адресации слова, и некорректности вещественного представления [Мнемоническим обозначениям команд арифметических операций с вещественными числами предшествует буква "F" в силу исторически сложившегося названия представления вещественных чисел как чисел с плавающей точкой (floating point). Это отражается также в мнемонике кодов операций FLOATR, FLOAT и FLOATI]).
Real Add RS 38 FA, R1A, R2 GLE (Сложение вещественное)
Эта команда выполняется так же, как R1 Add Register, с тем отличием, что исполнительный адрес вычисляется по правилу адресации команд типа регистр-память.
Real Add Immediate IM 58 FAI, R1 I GLE (Сложение вещественное непосредственное)
В регистр R1 записывается сумма величины из регистра R1 и непосредственного операнда I в коротком вещественном формате. Может иметь место особый случай некорректности вещественного представления.
Real Subtract Register RR 19 FSR, R1 R2 GLE (Вычитание вещественное)
Из содержимого регистра R1 (уменьшаемое) вычитается вещественное число по исполнительному адресу (вычитаемое), и результат записывается в регистр R1. Для установки РПР разность сравнивается с нулем. Могут иметь место особые случаи неверной адресации слова и некорректности вещественного представления.
Real Subtract RS 39 FS, R1 A, R2 GLE (Вычитание вещественное)
Эта команда такая же, как Real Subtract Register, с тем отличием, что исполнительный адрес вычисляется по правилу адресации команд типа регистр-память.
Real Subtract Immediate IM 59 FSI, R1 I GLE (Вычитание вещественное непосредственное)
Из величины в регистре R1 (уменьшаемое) вычитается непосредственный короткий вещественный операнд I (вычитаемое), и результат записывается в регистр R1. Для установки РПР разность сравнивается с нулем. Может иметь место особый случай некорректности вещественного представления.
Reverse Real Subtract Register RR 1A RFSR, R1 R2 GLE (Вычитание вещественное обратное)
Эта команда такая же, как Real Subtract Register, с тем отличием, что уменьшаемое и вычитаемое меняются ролями.
Reverse Real Subtract RS 3A RFS, R1 A, R2 GLE (Вычитание вещественное обратное)
Эта команда такая же, как Real Subtract, с тем отличием, что уменьшаемое и вычитаемое меняются ролями.
Reverse Real Subtract Immediate IM 5A RFSI, R1 I GLE (Вычитание вещественное непосредственное обратное)
Эта команда такая же, как Real Subtract Immediate, с тем отличием, что уменьшаемое и вычитаемое меняются ролями.
Real Multiply Register RR 1B FMR, R1 R2 GLE (Умножение вещественное)
Величина в регистре R1 умножается на вещественное число по исполнительному адресу, и результат записывается в регистр R1. Для установки РПР произведение сравнивается с нулем. Могут иметь место особые случаи как неверной адресации слова, так и некорректности вещественного представления.
Real Multiply RS 3B FM, R1 A, R2 GLE (Умножение вещественное)
Эта команда такая же, как Real Multiply Register, с тем отличием, что исполнительный адрес вычисляется по правилу адресации команд типа регистр-память.
Real Multiply Immediate IM 5B FMI, R1 I GLE (Умножение вещественное непосредственное)
Величина в регистре R1 умножается на короткий вещественный непосредственный операнд I, и результат записывается в регистр R1. Для установки РПР произведение сравнивается с нулем. Может иметь место особый случай некорректности вещественного представления.
Real Divide Register RR 1C FDR, R1 R2 GLE (Деление вещественное)
Величина в регистре R1 (делимое) делится на вещественное число по исполнительному адресу (делитель), и результат записывается в регистр R1. Для установки РПР частное сравнивается с нулем. Могут иметь место особые случаи неверной адресации слова, некорректности вещественного представления и деления на нуль.
Real Divide RS 3C FD, R1 A, R2 GLE (Деление вещественное)
Эта команда такая же, как Real Divide Register, с тем отличием, что исполнительный адрес вычисляется по правилу адресации команд типа регистр-память.
Real Divide Immediate IM 5C FDI, R1 I GLE (Деление вещественное непосредственное)
Величина в регистре R1 (делимое) делится на короткий вещественный непосредственный операнд I (делитель), и результат записывается в регистр R1. Для установки РПР частное сравнивается с нулем. Могут иметь место особые случаи некорректности вещественного представления и деления на нуль.
Reverse Real Divide Register RR 1D RFDR, R1 R2 GLE (Деление вещественное обратное)
Эта команда такая же как Real Divide Register с тем отличием, что делимое и делитель меняются ролями.
Reverse Real Divide RS 3D RFD, R1 A, R2 GLE (Деление вещественное непосредственное обратное)
Эта команда такая же, как Real Divide, с тем отличием, что делимое и делитель меняются ролями.
Reverse Real Divide Immediate IM 5D RFDI, R1 I GLE (Деление вещественное непосредственное обратное)
Эта команда такая же, как Real Divide Immediate, с тем отлычием, что делимое и делитель меняются ролями.
Convert To Real Register RR 1E FLOATR, R1 R2 GLE (Преобразование в вещественное)
32-разрядное целое в дополнительном коде по исполнительному адресу преобразуется в формат вещественного числа и записывается в регистр R1. Для установки РПР результат преобразования сравнивается с нулем. Может иметь место особый случай неверной адресации слова.
Convert To Real RS 3E FLOAT, R1 A, R2 GLE (Преобразование в вещественное)
Эта команда такая же, как Convert To Real Register, с тем отличием, что исполнительный адрес вычисляется по правилу адресации команд типа регистр-память.
Convert To Real Immediate IM 5E FLOATI, R1 I GLE (Преобразование в вещественное непосредственное)
Непосредственный операнд, рассматриваемый как 20-разрядное целое в дополнительном коде, преобразуется в формат вещественного числа и записывается в регистр R1. Для установки РПР результат сравнивается с нулем.
Convert To Integer Register RR 1F FIXR, R1 R2 OGLE (Преобразование в целое)
Целая часть вещественного числа в слове по исполнительному адресу преобразуется в 32-разрядное целое в дополнительном коде и записывается в регистр R1. При переполнении результат обнуляется и в РПР устанавливается О-бит. Для установки в РПР других разрядов результат сравнивается с нулем. Может иметь место особый случай неверной адресации слова [Эти команды обозначены FIXR, FIX и FIXI, поскольку представление целых чисел исторически называется представлением с фиксированной точкой (fixed point)].
Convert To Integer RS 3F FIX, R1 A, R2 OGLE (Преобразование в целое)
Эта команда такая же, как Convert To Integer Register, если не считать того, что исполнительный адрес вычисляется по правилу адресации команд типа регистр-память.
Convert To Integer Immediate IM 5F FIXI, R1 I OGLE (Преобразование в целое непосредственное)
Короткий вещественный непосредственный операнд I преобразуется в 32-разрядное целое в дополнительном коде и записывается в регистр R1. При переполнении результат обнуляется и в РПР устанавливается О-бит. Для установки в РПР других разрядов результат сравнивается с нулем.
Real Floor RS 78 FLOOR, R1 A, R2 GLE (Вещественное округление с недостатком)
В регистр R1 записывается в вещественном формате ближайшее целое, не превосходящее вещественного числа по исполнительному адресу. Для установки РПР результат сравнивается с нулем. Может иметь место особый случай неверной адресации слова.
Real Ceiling RS 79 CEIL, R1 A, R2 GLE (Вещественное округление с избытком)
В регистр R1 записывается в вещественном формате ближайшее целое, не меньшее вещественного числа по исполнительному адресу. Для установки РПР результат сравнивается с нулем. Может иметь место особый случай неверной адресации слова.
Minimum RS 7A MIN, R1 A, R2 LE (Минимум)
В регистр R1 записывается минимальная из величин, содержащихся в регистре R1 и слове по исполнительному адресу. Установка РПР производится в результате сравнения исходного и конечного содержимого R1. Может иметь место особый случай неверной адресации слова.
Maximum RS 7B МАХ, R1 А, R2 GE (Максимум)
Эта команда такая же, как Minimum, с тем отличием, что минимум заменяется на максимум.
Shift Logical RS 7C SHIFTL, R1 A, R2 OGLE (Сдвиг логический)
Исполнительный адрес рассматривается как 16-разрядное число в дополнительном коде, называемое счетчиком сдвига. Содержимое регистра R1 сдвигается на число разрядов, равное значению счетчика сдвига, сдвиг происходит влево при положительном значении счетчика и вправо - при отрицательном. Разряды, выталкиваемые за границы регистра, теряются. При потере хотя бы одного единичного разряда в РПР устанавливается О-бит. Для установки в РПР остальных разрядов результат сравнивается с нулем [Счетчик сдвига, по абсолютной величине больший 32, определяет те же действия, что и соответствующий счетчик, по модулю равный или меньший 32. При выполнении команды сдвига большие значения счетчика заменяются меньшими]).
Shift Circular RS 7D SHIFTC, R1 A, R2 GLE (Сдвиг циклический)
Эта команда работает так же, как Shift Logical, с тем отличием, что разряды, выталкиваемые за пределы регистра, занимают освобождающиеся позиции с другой стороны. Переполнение произойти не может.
Shift Arithmetic RS 7E SHIFTA, R1 A, R2 OGLE (Сдвиг арифметический)
Эта команда работает аналогично команде Shift Logical при сдвигах влево, а при сдвигах вправо освободившимся разрядам присваивается значение нулевого разряда. Если при сдвиге влево бит, выдвинутый в знаковый разряд, отличается от последнего, происходит переполнение.
Shift Real RS 7F SHIFTR, R1 A, R2 GLE (Сдвиг вещественный)
Исполнительный адрес рассматривается как 16-разрядный счетчик сдвига в дополнительном коде. Мантисса абсолютного значения вещественного числа в регистре R1 сдвигается влево или вправо на 4 разряда, освободившиеся позиции заполняются нулями. Если в итоге мантисса равна нулю, значит, таков результат. В противном случае из порядка вычитается значение счетчика сдвига и полученная величина записывается с исходным знаком в регистр R1. Переполнение произойти не может, но возможен особый случай некорректности вещественного представления. Для установки РПР результат сравнивается с нулем.
Таблица 25.1. Сводка кодов операций

Номер строки определяет младшие столбца 4 разряда кода операции, номер столбца - 3 старших разряда.
...
Reverse Subtract Register RR 12 RSR, R1 R2 OGLE (Вычитание обратное)
Эта команда выполняется так же, как команда Subtract Register, с тем отличием, что вычитаемое и уменьшаемое меняются ролями [Хотя во всех командах Reverse значения двух операндов и меняются ролями, результат записывается туда же, куда и раньше..
Reverse Subtract RS 32 RS, R1 A, R2 OGLE (Вычитание обратное)
Эта команда выполняется так же, как Subtract, с тем отличием, что вычитаемое и уменьшаемое меняются ролями.
Reverse Subtract Immediate IM 52 RS I, R1 I OGLE (Вычитание непосредственное обратное)
Эта команда выполняется так же, как Subtract Immediate, с тем отличием, что вычитаемое и уменьшаемое меняются ролями.
Reverse Subtract Character CH 72 RSC, R1 A, R2 OGLE (Вычитание байта обратное)
Эта команда выполняется так же, как Subtract Character, с тем отличием, что вычитаемое и уменьшаемое меняются ролями.
Multiply Register RR 13 MR, R1 R2 OGLE (Умножение)
Перемножаются содержимое регистра R1 и слова по исполнительному адресу; младшие 32 разряда произведения записываются в регистр R1. Для установки РПР результат в R1 сравнивается с нулем. При переполнении в РПР устанавливается только О-бит. Может иметь место особый случай неверной адресации слова.
Multiply RS 33 M, R1 A, R2 OGLE (Умножение)
Эта команда выполняется так же, как Multiply Register, с тем отличием, что исполнительный адрес вычисляется по правилу адресации команд типа регистр-память.
Multiply Immediate IM 53 MI, R1 I OGLE (Умножение непосредственное)
В регистр RI записываются младшие 32 разряда произведения содержимого регистра R1 на 20-разрядный непосредственный операнд I. Для установки РПР произведение в R1 сравнивается с нулем. При переполнении в РПР устанавливается только О-бит.
Multiply Character CH 73 МС, R1 А, R2 OGLE (Умножение байта)
В регистр R1 записываются младшие 32 разряда произведения содержимого регистра R1 на 8-разрядное положительное целое число, расположенное в байте по исполнительному адресу. Для установки РПР величина в R1 сравнивается с нулем. При переполнении в РПР устанавливается только О-бит.
Divide Register RR 14 DR, R1 R2 OGLE (Деление)
Содержимое регистра R1 (делимое) делится на слово по исполнительному адресу (делитель), и частное записывается в регистр R1. Деление определено таким образом, что остаток получается неотрицательным. Для установки РПР частное сравнивается с нулем. При переполнении в РПР устанавливается только О-бит. Может иметь место особый случай неверной адресации слова. Если делитель равен нулю, то происходит ОСОБЫЙ СЛУЧАЙ ДЕЛЕНИЯ НА НУЛЬ и регистр R1 не меняется.
Divide RS 34 D, R1 A, R2 OGLE (Деление)
Эта команда выполняется так же, как Divide Register, с тем отличием, что исполнительный адрес вычисляется по правилу адресации команд типа регистр-память.
Divide Immediate IM 54 DI, R1 I OGLE (Деление непосредственное)
В регистр R1 записывается частное от деления содержимого R1 (делимое) на значение 20-разрядного непосредственного операнда I в дополнительном коде. Операция определяется таким образом, чтобы остаток от деления был неотрицательным. Для установки РПР частное сравнивается с нулем. При переполнении в РПР устанавливается только О-бит. Если делитель равен нулю, то происходит особый случай деления на нуль и регистр R1 не изменяется.
Divide Character CH 74 DC, R1 A, R2 GLE (Деление на байт)
В регистр R1 записывается частное от деления содержимого регистра R1 (делимое) на положительное 8-разрядное целое число в байте по исполнительному адресу (делитель). Частное определяется таким образом, чтобы остаток от деления был неотрицательным. Для установки РПР частное сравнивается с нулем. Если делитель равен нулю, то происходит особый случай деления на нуль и регистр R1 не изменяется. Переполнение невозможно.
Reverse Divide Register RR 15 RDR, R1 R2 OGLE (Деление обратное)
Эта команда выполняется так же, как Divide Register, с тем отличием, что делимое и делитель меняются ролями.
Reverse Divide RS 35 RD, R1 A, R2 OGLE (Деление обратное)
Эта команда выполняется так же, как Divide, с тем отличием, что делимое и делитель меняются ролями.
Reverse Divide Immediate IM 55 RDI, R1 I GLE (Деление непосредственное обратное)
Эта команда выполняется так же, как Divide Immediate, с тем отличием; что делимое и делитель меняются ролями.
Reverse Divide Character CH 75 RDC, R1 A, R2 GLE (Деление на байт обратное)
Эта команда выполняется так же, как Divide Character, с тем отличием, что делимое и делитель меняются ролями.
Remainder Register RR 16 REMR, R1 R2 GE (Остаток от деления)
В регистр R1 записывается неотрицательный остаток от деления содержимого регистра R1 (делимое) на слово по исполнительному адресу (делитель). Для установки РПР остаток сравнивается с нулем. Может иметь место особый случай неверной адресации слова. Если делитель равен нулю, происходит особый случай деления на нуль и регистр R1 не изменяется.
Remainder RS 36 REM, R1 А, R2 GE (Остаток от деления)
Эта команда выполняется так же, как Remainder Register, с тем отличием, что исполнительный адрес вычисляется по правилу адресации команд типа регистр-память.
Remainder Immediate IM 56 REMI, R1 I GE (Остаток от деления непосредственного)
В регистр R1 записывается неотрицательный остаток от деления содержимого R1 (делимое) на значение 20-разрядного непосредственного операнда I в дополнительном коде (делитель). Для установки РПР остаток сравнивается с нулем. Если делитель равен нулю, происходит особый случай деления на нуль и регистр R1 не изменяется.
Remainder Character CH 76 REMC, R1 A, R2 GE (Остаток от деления на байт)
В регистр R1 записывается неотрицательный остаток от деления содержимого регистра R1 (делимое) на положительное 8-разрядное целое число (делитель) в байте по исполнительному адресу. Для установки РПР остаток сравнивается с нулем. Если делитель равен нулю, происходит особый случай деления на нуль и регистр R1 не изменяется.
Reverse Remainder Register RR 17 RREMR, R1 R2 GE (Остаток от деления обратного)
Эта команда выполняется так же, как Remainder Register, с тем отличием, что делимое и делитель меняются ролями.
Reverse Remainder RS 37 RREM, R1 A, R2 GE (Остаток от деления обратного)
Эта команда выполняется так же, как Remainder, с тем отличием, что делимое и делитель меняются ролями.
Reverse Remainder Immediate IM 57 RREMI, R1 I GE (Остаток от деления непосредственного обратного)
Эта команда выполняется так же, как Remainder Immediate, с тем отличием, что делимое и делитель меняются ролями.
Reverse Remainder Character CH 77 RREMC, R1 A, R2 GE (Остаток от деления на байт обратного)
Эта команда выполняется так же, как Remainder Character, с тем отличием, что делимое и делитель меняются ролями.
Real Add Register RR 18 FAR, R1 R2 GLE (Сложение вещественное)
Величина в регистре R1 складывается с вещественным числом по исполнительному адресу, и результат записывается в регистр R1. Для установки РПР сумма сравнивается с нулем. Могут иметь место особые случаи и неверной адресации слова, и некорректности вещественного представления [Мнемоническим обозначениям команд арифметических операций с вещественными числами предшествует буква "F" в силу исторически сложившегося названия представления вещественных чисел как чисел с плавающей точкой (floating point). Это отражается также в мнемонике кодов операций FLOATR, FLOAT и FLOATI]).
Real Add RS 38 FA, R1A, R2 GLE (Сложение вещественное)
Эта команда выполняется так же, как R1 Add Register, с тем отличием, что исполнительный адрес вычисляется по правилу адресации команд типа регистр-память.
Real Add Immediate IM 58 FAI, R1 I GLE (Сложение вещественное непосредственное)
В регистр R1 записывается сумма величины из регистра R1 и непосредственного операнда I в коротком вещественном формате. Может иметь место особый случай некорректности вещественного представления.
Real Subtract Register RR 19 FSR, R1 R2 GLE (Вычитание вещественное)
Из содержимого регистра R1 (уменьшаемое) вычитается вещественное число по исполнительному адресу (вычитаемое), и результат записывается в регистр R1. Для установки РПР разность сравнивается с нулем. Могут иметь место особые случаи неверной адресации слова и некорректности вещественного представления.
Real Subtract RS 39 FS, R1 A, R2 GLE (Вычитание вещественное)
Эта команда такая же, как Real Subtract Register, с тем отличием, что исполнительный адрес вычисляется по правилу адресации команд типа регистр-память.
Real Subtract Immediate IM 59 FSI, R1 I GLE (Вычитание вещественное непосредственное)
Из величины в регистре R1 (уменьшаемое) вычитается непосредственный короткий вещественный операнд I (вычитаемое), и результат записывается в регистр R1. Для установки РПР разность сравнивается с нулем. Может иметь место особый случай некорректности вещественного представления.
Reverse Real Subtract Register RR 1A RFSR, R1 R2 GLE (Вычитание вещественное обратное)
Эта команда такая же, как Real Subtract Register, с тем отличием, что уменьшаемое и вычитаемое меняются ролями.
Reverse Real Subtract RS 3A RFS, R1 A, R2 GLE (Вычитание вещественное обратное)
Эта команда такая же, как Real Subtract, с тем отличием, что уменьшаемое и вычитаемое меняются ролями.
Reverse Real Subtract Immediate IM 5A RFSI, R1 I GLE (Вычитание вещественное непосредственное обратное)
Эта команда такая же, как Real Subtract Immediate, с тем отличием, что уменьшаемое и вычитаемое меняются ролями.
Real Multiply Register RR 1B FMR, R1 R2 GLE (Умножение вещественное)
Величина в регистре R1 умножается на вещественное число по исполнительному адресу, и результат записывается в регистр R1. Для установки РПР произведение сравнивается с нулем. Могут иметь место особые случаи как неверной адресации слова, так и некорректности вещественного представления.
Real Multiply RS 3B FM, R1 A, R2 GLE (Умножение вещественное)
Эта команда такая же, как Real Multiply Register, с тем отличием, что исполнительный адрес вычисляется по правилу адресации команд типа регистр-память.
Real Multiply Immediate IM 5B FMI, R1 I GLE (Умножение вещественное непосредственное)
Величина в регистре R1 умножается на короткий вещественный непосредственный операнд I, и результат записывается в регистр R1. Для установки РПР произведение сравнивается с нулем. Может иметь место особый случай некорректности вещественного представления.
Real Divide Register RR 1C FDR, R1 R2 GLE (Деление вещественное)
Величина в регистре R1 (делимое) делится на вещественное число по исполнительному адресу (делитель), и результат записывается в регистр R1. Для установки РПР частное сравнивается с нулем. Могут иметь место особые случаи неверной адресации слова, некорректности вещественного представления и деления на нуль.
Real Divide RS 3C FD, R1 A, R2 GLE (Деление вещественное)
Эта команда такая же, как Real Divide Register, с тем отличием, что исполнительный адрес вычисляется по правилу адресации команд типа регистр-память.
Real Divide Immediate IM 5C FDI, R1 I GLE (Деление вещественное непосредственное)
Величина в регистре R1 (делимое) делится на короткий вещественный непосредственный операнд I (делитель), и результат записывается в регистр R1. Для установки РПР частное сравнивается с нулем. Могут иметь место особые случаи некорректности вещественного представления и деления на нуль.
Reverse Real Divide Register RR 1D RFDR, R1 R2 GLE (Деление вещественное обратное)
Эта команда такая же как Real Divide Register с тем отличием, что делимое и делитель меняются ролями.
Reverse Real Divide RS 3D RFD, R1 A, R2 GLE (Деление вещественное непосредственное обратное)
Эта команда такая же, как Real Divide, с тем отличием, что делимое и делитель меняются ролями.
Reverse Real Divide Immediate IM 5D RFDI, R1 I GLE (Деление вещественное непосредственное обратное)
Эта команда такая же, как Real Divide Immediate, с тем отлычием, что делимое и делитель меняются ролями.
Convert To Real Register RR 1E FLOATR, R1 R2 GLE (Преобразование в вещественное)
32-разрядное целое в дополнительном коде по исполнительному адресу преобразуется в формат вещественного числа и записывается в регистр R1. Для установки РПР результат преобразования сравнивается с нулем. Может иметь место особый случай неверной адресации слова.
Convert To Real RS 3E FLOAT, R1 A, R2 GLE (Преобразование в вещественное)
Эта команда такая же, как Convert To Real Register, с тем отличием, что исполнительный адрес вычисляется по правилу адресации команд типа регистр-память.
Convert To Real Immediate IM 5E FLOATI, R1 I GLE (Преобразование в вещественное непосредственное)
Непосредственный операнд, рассматриваемый как 20-разрядное целое в дополнительном коде, преобразуется в формат вещественного числа и записывается в регистр R1. Для установки РПР результат сравнивается с нулем.
Convert To Integer Register RR 1F FIXR, R1 R2 OGLE (Преобразование в целое)
Целая часть вещественного числа в слове по исполнительному адресу преобразуется в 32-разрядное целое в дополнительном коде и записывается в регистр R1. При переполнении результат обнуляется и в РПР устанавливается О-бит. Для установки в РПР других разрядов результат сравнивается с нулем. Может иметь место особый случай неверной адресации слова [Эти команды обозначены FIXR, FIX и FIXI, поскольку представление целых чисел исторически называется представлением с фиксированной точкой (fixed point)].
Convert To Integer RS 3F FIX, R1 A, R2 OGLE (Преобразование в целое)
Эта команда такая же, как Convert To Integer Register, если не считать того, что исполнительный адрес вычисляется по правилу адресации команд типа регистр-память.
Convert To Integer Immediate IM 5F FIXI, R1 I OGLE (Преобразование в целое непосредственное)
Короткий вещественный непосредственный операнд I преобразуется в 32-разрядное целое в дополнительном коде и записывается в регистр R1. При переполнении результат обнуляется и в РПР устанавливается О-бит. Для установки в РПР других разрядов результат сравнивается с нулем.
Real Floor RS 78 FLOOR, R1 A, R2 GLE (Вещественное округление с недостатком)
В регистр R1 записывается в вещественном формате ближайшее целое, не превосходящее вещественного числа по исполнительному адресу. Для установки РПР результат сравнивается с нулем. Может иметь место особый случай неверной адресации слова.
Real Ceiling RS 79 CEIL, R1 A, R2 GLE (Вещественное округление с избытком)
В регистр R1 записывается в вещественном формате ближайшее целое, не меньшее вещественного числа по исполнительному адресу. Для установки РПР результат сравнивается с нулем. Может иметь место особый случай неверной адресации слова.
Minimum RS 7A MIN, R1 A, R2 LE (Минимум)
В регистр R1 записывается минимальная из величин, содержащихся в регистре R1 и слове по исполнительному адресу. Установка РПР производится в результате сравнения исходного и конечного содержимого R1. Может иметь место особый случай неверной адресации слова.
Maximum RS 7B МАХ, R1 А, R2 GE (Максимум)
Эта команда такая же, как Minimum, с тем отличием, что минимум заменяется на максимум.
Shift Logical RS 7C SHIFTL, R1 A, R2 OGLE (Сдвиг логический)
Исполнительный адрес рассматривается как 16-разрядное число в дополнительном коде, называемое счетчиком сдвига. Содержимое регистра R1 сдвигается на число разрядов, равное значению счетчика сдвига, сдвиг происходит влево при положительном значении счетчика и вправо - при отрицательном. Разряды, выталкиваемые за границы регистра, теряются. При потере хотя бы одного единичного разряда в РПР устанавливается О-бит. Для установки в РПР остальных разрядов результат сравнивается с нулем [Счетчик сдвига, по абсолютной величине больший 32, определяет те же действия, что и соответствующий счетчик, по модулю равный или меньший 32. При выполнении команды сдвига большие значения счетчика заменяются меньшими]).
Shift Circular RS 7D SHIFTC, R1 A, R2 GLE (Сдвиг циклический)
Эта команда работает так же, как Shift Logical, с тем отличием, что разряды, выталкиваемые за пределы регистра, занимают освобождающиеся позиции с другой стороны. Переполнение произойти не может.
Shift Arithmetic RS 7E SHIFTA, R1 A, R2 OGLE (Сдвиг арифметический)
Эта команда работает аналогично команде Shift Logical при сдвигах влево, а при сдвигах вправо освободившимся разрядам присваивается значение нулевого разряда. Если при сдвиге влево бит, выдвинутый в знаковый разряд, отличается от последнего, происходит переполнение.
Shift Real RS 7F SHIFTR, R1 A, R2 GLE (Сдвиг вещественный)
Исполнительный адрес рассматривается как 16-разрядный счетчик сдвига в дополнительном коде. Мантисса абсолютного значения вещественного числа в регистре R1 сдвигается влево или вправо на 4 разряда, освободившиеся позиции заполняются нулями. Если в итоге мантисса равна нулю, значит, таков результат. В противном случае из порядка вычитается значение счетчика сдвига и полученная величина записывается с исходным знаком в регистр R1. Переполнение произойти не может, но возможен особый случай некорректности вещественного представления. Для установки РПР результат сравнивается с нулем.
Таблица 25.1. Сводка кодов операций

Номер строки определяет младшие столбца 4 разряда кода операции, номер столбца - 3 старших разряда.
...
Gudleifr- Admin
- Сообщения : 3252
Дата регистрации : 2017-03-29
Re: Уэзерелл. Этюды для программистов. 1982
автор Gudleifr Вс Фев 28, 2021 8:14 pm
...
ОСОБЫЕ СЛУЧАИ И ОБРАЩЕНИЯ К СУПЕРВИЗОРУ
В современных компьютерах организация ввода/вывода но крайней мере столь же сложна, как центральный процессор. Чтобы не увеличивать в два раза объем задачи, предположим, что СУПЕРВИЗОР управляет прохождением каждой задачи пользователя. Обращения к супервизору могут осуществляться как непосредственно при помощи команды вызова супервизора Supervisor Call, так и косвенным образом - при возникновении особых случаев. Различные поля команды Supervisor Call используется для задания требуемых действий и передачи параметров. Далее представлен минимальный набор действий супервизора в зависимости от содержимого указателя регистра R1.
R1=0 Завершить выполнение программы и произвести после нее "чистку мусора".
R1=1 Прочитать из входного потока целое число и записать его по исполнительному адресу команды SVC (адрес должен указывать на слово).
R1=2 Прочитать вещественное число и записать его по исполнительному адресу.
R1=3 Прочитать литеру и записать по исполнительному адресу.
R1=4 Перейти во входном потоке к новой записи.
R1=5 Слово по исполнительному адресу записать в выходной поток в виде целого числа.
R1=6 Слово по исполнительному адресу записать в выходной поток в виде вещественного числа.
R1=7 Байт по исполнительному адресу записать в выходной поток в виде литеры.
R1=8 Записать в выходной поток признак конца записи.
R1=9 и R2=0 Закончить трассировку выполнения команд.
R1=9 и R2=1 Начать трассировку выполнения команд. Печатать текущую информацию о каждой выполняемой команде.
R1=A Исполнительный адрес команды SVC должен быть адресом слова. Правое полуслово указывает адрес начала, а левое - адрес конца участка памяти для дампа. Программа дампа должна выдавать содержимое памяти в указанных пределах как в шестнадцатеричном, так и в текстовом формате. Возможно, окажется полезным выводить также мнемонику команд. Идущие подряд одинаковые строки программа дампа должна распознавать и печатать одну из них.
R1=F Данный вызов супервизора никогда не будет предназначаться для системного применения и может быть использован в имитаторе для любых целей.
Предполагается, что целые и вещественные числа во входном и выходном потоках заканчиваются пробелами.
Особые случаи: имеют место, когда в процессе выполнения команд возникают ошибки. При этом выполнение программы прерывается и супервизор извещается о причине прерывания и адресе команды, вызвавшей прерывание. Приведем вкратце перечень особых случаев.
ЗАПРЕЩЕННЫЙ АДРЕС КОМАНДЫ - на начало цикла выполнения команды адрес в САК - нечетный.
НЕКОРРЕКТНАЯ КОМАНДА - команда с данным кодом операции отсутствует.
НЕКОРРЕКТНАЯ КОСВЕННАЯ АДРЕСАЦИЯ - косвенный адрес - нечетный.
НЕВЕРНАЯ АДРЕСАЦИЯ СЛОВА - адрес слова, указанный в операнде команды, не делится на четыре.
НЕКОРРЕКТНОСТЬ ВЕЩЕСТВЕННОГО ПРЕДСТАВЛЕНИЯ - результат некоторой операции, определяющей вещественное значение, не может быть представлен в формате нормализованного вещественного числа.
НЕКОРРЕКТНОСТЬ КОМАНДЫ EXECUTE - исполнительный адрес команды Execute - нечетный.
ДЕЛЕНИЕ НА НУЛЬ - в операциях деления или нахождения остатка делитель равен нулю.
ЗАЦИКЛИВАНИЕ КОДА ОПЕРАЦИИ - четырехбайтовая команда начинается с FFFE.
Реакция супервизора на особый случай оставляется на усмотрение исполнителя, она должна лишь включать в себя сообщение пользователю о происшедшем событии.
ФАЙЛЫ АБСОЛЮТНОЙ ЗАГРУЗКИ
ФАЙЛ АБСОЛЮТНОЙ ЗАГРУЗКИ описывает содержимое памяти
УМ-1 перед выполнением программы. Обычно такие файлы получаются с помощью загрузчика УМ из перемещаемого языка загрузки, и в практически работающих системах такие файлы для экономии места в памяти, как правило, представляются в некотором двоичном формате. В нашем случае мы опишем формат, который можно отперфорировать, что облегчает процесс отладки. Каждая из записей физического файла состоит из 80 ВНЕШНИХ литер, при этом допустимыми являются цифры, буквы A, B, C, D, E, F, N и пробел. Чаще всего эти внешние литеры будут объединяться в группы, образуя шестнадцатеричные числа. Заметим, что для образования одного двухразрядного шестнадцатеричного числа требуются две внешние литеры, и это в свою очередь как раз обеспечивает заполнение позиции одной ВНУТРЕННЕЙ литеры (байта) УМ-1 [Такое многозначное употребление слова "литера" вновь возникнет при обсуждении загрузчика УМ. Постарайтесь четко уяснить разницу между литерами (байтами) в памяти и литерами во входном и выходном файлах. Во внутренней литере всегда содержится достаточно данных, чтобы представить одну внешнюю литеру, в то время как внешней литеры иногда недостаточно, чтобы закодировать одну внутреннюю литеру].
Любая запись, кроме последней, имеет стандартный формат. Литера 1 представляет собой КОНТРОЛЬНУЮ СУММУ всех остальных шестнадцатеричных цифр, получаемую путем их суммирования без учета переносимых знаков. Литеры со 2-й по 4-ю являются шестнадцатеричным порядковым номером, причем первая запись имеет номер 000. О выходе за пределы номеров записей следует сигнализировать как о нефатальной ошибке. Вслед за этой шапкой в записи располагаются триплеты: счетчик-адрес-данные. Поле счетчика содержит одну цифру и указывает, сколько байтов в памяти должна занять последующая информация. Поле адреса, состоящее из четырех цифр, дает шестнадцатеричный адрес начала информации в памяти УМ-1. И наконец, поле данных содержит по две цифры на каждую подлежащую загрузке литеру, и любая такая пара цифр считывается как целое шестнадцатеричное число, определяя, таким образом, восемь битов информации для записи в память. В одной записи может быть несколько таких триплетов, однако ни один из них не должен выходить за границы записи. Первый же пробел, появившийся в поле адреса, ограничивает полезную информацию в записи, и оставшуюся часть записи можно, если угодно, использовать для комментариев. Последняя запись содержит на месте символов 1-3 литеры END, а символы с 4-го по 7-й определяют четырехзначный шестнадцатеричный АДРЕС НАЧАЛА программы. Например, запись
E10241A2301020304207FF1BEC
имеет контрольную сумму E, порядковый номер 102 и помещает (достаточно бессмысленно) четыре литеры данных 01020304 с 1A23 адреса памяти, а две литеры 1BEC с адреса 07FF. Обратите внимание, что потребовалось ВОСЕМЬ шестнадцатеричных цифр, чтобы задать ЧЕТЫРЕ литеры во внутренней памяти.
ТЕМА. Напишите имитатор ЭВМ УМ-1. На вход имитатора должны поступать файл абсолютной загрузки и входной поток эмулируемой программы. Основное, что необходимо выдать,- это выходной поток программы. В виде приложения к имитатору напишите по крайней мере две программы для УМ-1, призванные проверить правильность эмуляции. Разумеется, эти программы надо будет вручную скомпоновать в формате файла абсолютной загрузки.
Кроме записи результата в память имитатор должен уметь выполнять трассировку и дамп эмулируемой программы. Трассировка должна продемонстрировать прокручиваемую команду, вычисление исполнительного адреса, а также операнды и результаты как в их естественном, так и в шестнадцатеричном формате. Дамп должен включать в себя печать содержимого памяти (возможно, под управлением вспомогательных средств) в шестнадцатеричном виде, в мнемонических обозначениях команд, а также в форматах - целом, вещественном и текстовом. Повторяющиеся группы данных должны печататься только один раз с указанием числа повторений. Управление трассировкой и дампом может выходить прямо на имитатор, возможно через пульт управления, или же может приводиться в действие путем обращений к супервизору в ходе выполнения программы.
УКАЗАНИЯ ИСПОЛНИТЕЛЮ. Имитаторы компьютеров бывают, как правило, простыми, если они основаны на заурядном цикле: ячейка-декодирование-выполнение. Как только выделен код операции, так определен один из очевидных 128 путей ветвления. Эти 128 независимых программ моделирования команд могут использовать целый ряд общих подпрограмм, выполняющих частные задачи, а именно подпрограмм вычисления исполнительного адреса, установки САК, проверки особых случаев, итогового состояния памяти и тому подобные. Четкая разбивка на подпрограммы поможет продемонстрировать правильность работы. В то же время важна эффективность выполнения командного цикла - в противном случае расход времени может оказаться недопустимо большим. Необходимо найти разумный компромисс. Для остальных частей имитатора не нужна столь же высокая эффективность, поскольку им предстоит выполняться во много раз реже.
Некоторые группы, выполнявшие в прошлом это задание, сообщали, что время, потраченное на конструирование простого ассемблера для получения тестовых вариантов, не прошло без пользы. Если в числе порученных вам работ окажется также и разработка загрузчика УМ, тщательно сконструированный ассемблер позволит применить его ко всему прочему и для проверки загрузчика.
ИНСТРУМЕНТОВКА. Перед нами вновь программа, в которой ясность и эффективность противоречат друг другу. Рассмотрите возможность применения любого языка достаточно высокого уровня, в котором наиболее важные программы можно после отладки эффективно переписать на языке ассемблера. Поскольку обычная связь между подпрограммами может оказаться дорогостоящей, эта задача представляет удобный случай поэкспериментировать с языками, позволяющими прямо вставлять небольшие заплатки на языке ассемблера. В какой-то степени среди прочих языков этими качествами обладают Фортран, Алгол и XPL.
ДЛИТЕЛЬНОСТЬ ИСПОЛНЕНИЯ. Одному исполнителю на шесть недель, двоим - на три недели. Если работа делается более чем одним исполнителем, каждый отчитывается за одну программу для УМ-1.
РАЗВИТИЕ ТЕМЫ. Самое очевидное дополнение к задаче состоит в получении временных характеристик (профиля) эмулируемой программы. Как часто работает каждая команда? Как часто используется каждая внутренняя подпрограмма? Какова картина обращений к памяти? К регистрам? И так далее, СКОЛЬКО ПОЖЕЛАЕТЕ. Эту информацию бывает чрезвычайно трудно получить в реальном компьютере, но она очень помогает при анализе сложных ситуаций.
ЛИТЕРАТУРА
Белл, Ньюэлл (Bell C.G., Newell A.). Computer Structures: Readings and Examples. McGraw-Hill, New York, NY, 1971.
Белл и Ньюэлл обсуждают общие принципы машинной архитектуры и приводят около 30 примеров. Значительное место уделяется разработке обозначений для описания машины. Многие примеры почерпнуты из существенно отредактированных документов проектов подлинных машин.
IBM Corporation. IBM System/360 Principles of Operation. IBM System Reference Library, GA22 6821-8, November 1970.
Xerox Data Systems. Xerox Sigma 7 Computer Reference Manual. Order #90 09 501, 1971.
УМ-1 весьма похожа как на Sigma 7, так и на IBM 360. Возможно, что сравнение этих машин с УМ-1 будет в чем-то полезно. С не меньшим успехом годятся другие выпуски указанных руководств.
* Кнут Д. Искусство программирования для
ЭВМ. Т.1. Основные алгоритмы.- М.: Мир, 1976, с.159. Кнут описывает гипотетическую машину MIX. В п.1.4.3.1 дается материал о MIX-имитаторе.
ОСОБЫЕ СЛУЧАИ И ОБРАЩЕНИЯ К СУПЕРВИЗОРУ
В современных компьютерах организация ввода/вывода но крайней мере столь же сложна, как центральный процессор. Чтобы не увеличивать в два раза объем задачи, предположим, что СУПЕРВИЗОР управляет прохождением каждой задачи пользователя. Обращения к супервизору могут осуществляться как непосредственно при помощи команды вызова супервизора Supervisor Call, так и косвенным образом - при возникновении особых случаев. Различные поля команды Supervisor Call используется для задания требуемых действий и передачи параметров. Далее представлен минимальный набор действий супервизора в зависимости от содержимого указателя регистра R1.
R1=0 Завершить выполнение программы и произвести после нее "чистку мусора".
R1=1 Прочитать из входного потока целое число и записать его по исполнительному адресу команды SVC (адрес должен указывать на слово).
R1=2 Прочитать вещественное число и записать его по исполнительному адресу.
R1=3 Прочитать литеру и записать по исполнительному адресу.
R1=4 Перейти во входном потоке к новой записи.
R1=5 Слово по исполнительному адресу записать в выходной поток в виде целого числа.
R1=6 Слово по исполнительному адресу записать в выходной поток в виде вещественного числа.
R1=7 Байт по исполнительному адресу записать в выходной поток в виде литеры.
R1=8 Записать в выходной поток признак конца записи.
R1=9 и R2=0 Закончить трассировку выполнения команд.
R1=9 и R2=1 Начать трассировку выполнения команд. Печатать текущую информацию о каждой выполняемой команде.
R1=A Исполнительный адрес команды SVC должен быть адресом слова. Правое полуслово указывает адрес начала, а левое - адрес конца участка памяти для дампа. Программа дампа должна выдавать содержимое памяти в указанных пределах как в шестнадцатеричном, так и в текстовом формате. Возможно, окажется полезным выводить также мнемонику команд. Идущие подряд одинаковые строки программа дампа должна распознавать и печатать одну из них.
R1=F Данный вызов супервизора никогда не будет предназначаться для системного применения и может быть использован в имитаторе для любых целей.
Предполагается, что целые и вещественные числа во входном и выходном потоках заканчиваются пробелами.
Особые случаи: имеют место, когда в процессе выполнения команд возникают ошибки. При этом выполнение программы прерывается и супервизор извещается о причине прерывания и адресе команды, вызвавшей прерывание. Приведем вкратце перечень особых случаев.
ЗАПРЕЩЕННЫЙ АДРЕС КОМАНДЫ - на начало цикла выполнения команды адрес в САК - нечетный.
НЕКОРРЕКТНАЯ КОМАНДА - команда с данным кодом операции отсутствует.
НЕКОРРЕКТНАЯ КОСВЕННАЯ АДРЕСАЦИЯ - косвенный адрес - нечетный.
НЕВЕРНАЯ АДРЕСАЦИЯ СЛОВА - адрес слова, указанный в операнде команды, не делится на четыре.
НЕКОРРЕКТНОСТЬ ВЕЩЕСТВЕННОГО ПРЕДСТАВЛЕНИЯ - результат некоторой операции, определяющей вещественное значение, не может быть представлен в формате нормализованного вещественного числа.
НЕКОРРЕКТНОСТЬ КОМАНДЫ EXECUTE - исполнительный адрес команды Execute - нечетный.
ДЕЛЕНИЕ НА НУЛЬ - в операциях деления или нахождения остатка делитель равен нулю.
ЗАЦИКЛИВАНИЕ КОДА ОПЕРАЦИИ - четырехбайтовая команда начинается с FFFE.
Реакция супервизора на особый случай оставляется на усмотрение исполнителя, она должна лишь включать в себя сообщение пользователю о происшедшем событии.
ФАЙЛЫ АБСОЛЮТНОЙ ЗАГРУЗКИ
ФАЙЛ АБСОЛЮТНОЙ ЗАГРУЗКИ описывает содержимое памяти
УМ-1 перед выполнением программы. Обычно такие файлы получаются с помощью загрузчика УМ из перемещаемого языка загрузки, и в практически работающих системах такие файлы для экономии места в памяти, как правило, представляются в некотором двоичном формате. В нашем случае мы опишем формат, который можно отперфорировать, что облегчает процесс отладки. Каждая из записей физического файла состоит из 80 ВНЕШНИХ литер, при этом допустимыми являются цифры, буквы A, B, C, D, E, F, N и пробел. Чаще всего эти внешние литеры будут объединяться в группы, образуя шестнадцатеричные числа. Заметим, что для образования одного двухразрядного шестнадцатеричного числа требуются две внешние литеры, и это в свою очередь как раз обеспечивает заполнение позиции одной ВНУТРЕННЕЙ литеры (байта) УМ-1 [Такое многозначное употребление слова "литера" вновь возникнет при обсуждении загрузчика УМ. Постарайтесь четко уяснить разницу между литерами (байтами) в памяти и литерами во входном и выходном файлах. Во внутренней литере всегда содержится достаточно данных, чтобы представить одну внешнюю литеру, в то время как внешней литеры иногда недостаточно, чтобы закодировать одну внутреннюю литеру].
Любая запись, кроме последней, имеет стандартный формат. Литера 1 представляет собой КОНТРОЛЬНУЮ СУММУ всех остальных шестнадцатеричных цифр, получаемую путем их суммирования без учета переносимых знаков. Литеры со 2-й по 4-ю являются шестнадцатеричным порядковым номером, причем первая запись имеет номер 000. О выходе за пределы номеров записей следует сигнализировать как о нефатальной ошибке. Вслед за этой шапкой в записи располагаются триплеты: счетчик-адрес-данные. Поле счетчика содержит одну цифру и указывает, сколько байтов в памяти должна занять последующая информация. Поле адреса, состоящее из четырех цифр, дает шестнадцатеричный адрес начала информации в памяти УМ-1. И наконец, поле данных содержит по две цифры на каждую подлежащую загрузке литеру, и любая такая пара цифр считывается как целое шестнадцатеричное число, определяя, таким образом, восемь битов информации для записи в память. В одной записи может быть несколько таких триплетов, однако ни один из них не должен выходить за границы записи. Первый же пробел, появившийся в поле адреса, ограничивает полезную информацию в записи, и оставшуюся часть записи можно, если угодно, использовать для комментариев. Последняя запись содержит на месте символов 1-3 литеры END, а символы с 4-го по 7-й определяют четырехзначный шестнадцатеричный АДРЕС НАЧАЛА программы. Например, запись
E10241A2301020304207FF1BEC
имеет контрольную сумму E, порядковый номер 102 и помещает (достаточно бессмысленно) четыре литеры данных 01020304 с 1A23 адреса памяти, а две литеры 1BEC с адреса 07FF. Обратите внимание, что потребовалось ВОСЕМЬ шестнадцатеричных цифр, чтобы задать ЧЕТЫРЕ литеры во внутренней памяти.
ТЕМА. Напишите имитатор ЭВМ УМ-1. На вход имитатора должны поступать файл абсолютной загрузки и входной поток эмулируемой программы. Основное, что необходимо выдать,- это выходной поток программы. В виде приложения к имитатору напишите по крайней мере две программы для УМ-1, призванные проверить правильность эмуляции. Разумеется, эти программы надо будет вручную скомпоновать в формате файла абсолютной загрузки.
Кроме записи результата в память имитатор должен уметь выполнять трассировку и дамп эмулируемой программы. Трассировка должна продемонстрировать прокручиваемую команду, вычисление исполнительного адреса, а также операнды и результаты как в их естественном, так и в шестнадцатеричном формате. Дамп должен включать в себя печать содержимого памяти (возможно, под управлением вспомогательных средств) в шестнадцатеричном виде, в мнемонических обозначениях команд, а также в форматах - целом, вещественном и текстовом. Повторяющиеся группы данных должны печататься только один раз с указанием числа повторений. Управление трассировкой и дампом может выходить прямо на имитатор, возможно через пульт управления, или же может приводиться в действие путем обращений к супервизору в ходе выполнения программы.
УКАЗАНИЯ ИСПОЛНИТЕЛЮ. Имитаторы компьютеров бывают, как правило, простыми, если они основаны на заурядном цикле: ячейка-декодирование-выполнение. Как только выделен код операции, так определен один из очевидных 128 путей ветвления. Эти 128 независимых программ моделирования команд могут использовать целый ряд общих подпрограмм, выполняющих частные задачи, а именно подпрограмм вычисления исполнительного адреса, установки САК, проверки особых случаев, итогового состояния памяти и тому подобные. Четкая разбивка на подпрограммы поможет продемонстрировать правильность работы. В то же время важна эффективность выполнения командного цикла - в противном случае расход времени может оказаться недопустимо большим. Необходимо найти разумный компромисс. Для остальных частей имитатора не нужна столь же высокая эффективность, поскольку им предстоит выполняться во много раз реже.
Некоторые группы, выполнявшие в прошлом это задание, сообщали, что время, потраченное на конструирование простого ассемблера для получения тестовых вариантов, не прошло без пользы. Если в числе порученных вам работ окажется также и разработка загрузчика УМ, тщательно сконструированный ассемблер позволит применить его ко всему прочему и для проверки загрузчика.
ИНСТРУМЕНТОВКА. Перед нами вновь программа, в которой ясность и эффективность противоречат друг другу. Рассмотрите возможность применения любого языка достаточно высокого уровня, в котором наиболее важные программы можно после отладки эффективно переписать на языке ассемблера. Поскольку обычная связь между подпрограммами может оказаться дорогостоящей, эта задача представляет удобный случай поэкспериментировать с языками, позволяющими прямо вставлять небольшие заплатки на языке ассемблера. В какой-то степени среди прочих языков этими качествами обладают Фортран, Алгол и XPL.
ДЛИТЕЛЬНОСТЬ ИСПОЛНЕНИЯ. Одному исполнителю на шесть недель, двоим - на три недели. Если работа делается более чем одним исполнителем, каждый отчитывается за одну программу для УМ-1.
РАЗВИТИЕ ТЕМЫ. Самое очевидное дополнение к задаче состоит в получении временных характеристик (профиля) эмулируемой программы. Как часто работает каждая команда? Как часто используется каждая внутренняя подпрограмма? Какова картина обращений к памяти? К регистрам? И так далее, СКОЛЬКО ПОЖЕЛАЕТЕ. Эту информацию бывает чрезвычайно трудно получить в реальном компьютере, но она очень помогает при анализе сложных ситуаций.
ЛИТЕРАТУРА
Белл, Ньюэлл (Bell C.G., Newell A.). Computer Structures: Readings and Examples. McGraw-Hill, New York, NY, 1971.
Белл и Ньюэлл обсуждают общие принципы машинной архитектуры и приводят около 30 примеров. Значительное место уделяется разработке обозначений для описания машины. Многие примеры почерпнуты из существенно отредактированных документов проектов подлинных машин.
IBM Corporation. IBM System/360 Principles of Operation. IBM System Reference Library, GA22 6821-8, November 1970.
Xerox Data Systems. Xerox Sigma 7 Computer Reference Manual. Order #90 09 501, 1971.
УМ-1 весьма похожа как на Sigma 7, так и на IBM 360. Возможно, что сравнение этих машин с УМ-1 будет в чем-то полезно. С не меньшим успехом годятся другие выпуски указанных руководств.
* Кнут Д. Искусство программирования для
ЭВМ. Т.1. Основные алгоритмы.- М.: Мир, 1976, с.159. Кнут описывает гипотетическую машину MIX. В п.1.4.3.1 дается материал о MIX-имитаторе.
Gudleifr- Admin
- Сообщения : 3252
Дата регистрации : 2017-03-29
Re: Уэзерелл. Этюды для программистов. 1982
автор Gudleifr Пн Мар 01, 2021 8:24 pm
26
ПИЩА ДЛЯ УМА,
ИЛИ...
СВЯЗЫВАЮЩИЙ ЗАГРУЗЧИК
В большинстве систем загрузчики находятся на положении пасынков. Их не любят пользователи, считая просто лишним препятствием на пути к вожделенному ответу. Они не нравятся и разработчикам компиляторов, поскольку являются составной частью системы (а вы считаете, что это не так?). Не по душе они и системным программистам, которые видят в них не более чем еще одно вспомогательное средство. Разве только коммерческие директора питают слабость к загрузчику за то, что он расходует так много машинного времени (и денег). Тем не менее, написав загрузчик для УМ-1, вы убедитесь, что его создание - очень стоящая задача.
Загрузчик УМ представляет собой довольно стандартный настраивающий загрузчик, предназначенный для работы с языком Мини (гл.27) и ЭВМ УМ-1 (гл.25). Основные функции загрузчика УМ связаны с интерпретацией перемещаемого языка загрузки, обработкой достаточно сложных таблиц символов и регистрацией ошибок в ходе загрузки. Программы на языке Мини могут состоять из независимо скомпилированных программных сегментов, и загрузчик УМ обеспечивает проверку соответствия типов величин, общих для нескольких сегментов, и библиотечный поиск для сборки полных программ. Кроме того, перемещаемый язык загрузки позволяет настолько просто генерировать команды перехода вперед, что компиляторы могут быть не двух-, а однопроходными. Многие находящиеся в эксплуатации загрузчики предусматривают еще более сложную обработку, однако такая обработка требует весьма развитой системы ввода/вывода и поэтому неприемлема для этюда. Не исключено, что вы не сможете до конца прочувствовать загрузчик УМ (как сильные, так и слабые его стороны), пока не сконструируете компилятор или же специально не изучите загрузчики по литературе.
ОБЩАЯ СХЕМА ЗАГРУЗЧИКА
На вход загрузчика УМ поступают ПРОГРАММНЫЙ ФАЙЛ и БИБЛИОТЕЧНЫЙ ФАЙЛ, причем каждый из них может состоять из некоторого числа модулей. Если же позволяет система, то программа или библиотека могут состоять более чем из одного файла. Загружены должны быть в первую очередь все модули программы, а модули из библиотечного файла загружаются, лишь если они соответствуют первичным ссылкам. К концу загрузки должен определиться ровно один начальный адрес программы, иначе фиксируется фатальная ошибка загрузки. В результате работы загрузчика получается ФАЙЛ АБСОЛЮТНОЙ ЗАГРУЗКИ, который описывался в гл.25. Загрузчик УМ содержит как счетчик абсолютного размещения (САР), так и счетчик относительного размещения (СОР). Перед началом загрузки САР устанавливается на адрес 40. Всякий раз, когда начинается очередной модуль, САР настраивается на ближайшую свободную границу слова, а СОР обнуляется [Вообще, если A есть начальный адрес текущего загружаемого модуля, то всегда выполняется соотношение САР-А = СОР. То есть САР и СОР при всех обстоятельствах изменяются согласованно, образуя тандем]). После того как загружен последний модуль, САР а последний раз продвигается к границе слова, следующего за верхней точкой модуля, и употребляется для определения значения абсолютного внешнего символа МАКСИМАЛЬНЫЙ АДРЕС.
ПЕРЕМЕЩАЕМЫЙ ЯЗЫК ЗАГРУЗКИ состоит из набора КОМАНД ЗАГРУЗКИ, длиной восемь битов каждая. Команды записываются с помощью КОДИРОВОК ПЕРЕМЕННОЙ ДЛИНЫ, при этом отдельные параметры могут оказаться запрятанными в самих командах. Остальные параметры могут быть переменной длины, а употребляемые в командах выражения допускаются любой сложности. Все имена должны быть декларированы до их использования; описанные однажды, они везде ниже заменяются на их порядковые номера с целью уменьшения размера загрузочного модуля. Поскольку модули должны генерироваться однопроходным компилятором Мини, их размер в явном виде не указан. Поэтому загрузчик УМ должен следить за МАРКЕРОМ КОНЦА, который позволит установить размер модуля. Внешние имена, встречающиеся в текущем модуле, должны быть описаны раньше всех других спецификаций загрузки. После того как все модули обработаны, из таблицы символов необходимо исключить все внутренние имена, глобальные символы сохранить и проделать соответствующие манипуляции с КАРТОЙ ЗАГРУЗКИ. Для целей диагностики можно ввести специальные символы, употребляемые только в карте загрузки. Загрузчик УМ в состоянии проверять типы внешних процедур и их аргументов.
СТРУКТУРА ФИЗИЧЕСКОЙ ЗАПИСИ
Записи в модуле загрузки представляют собой цепочки внешних литер переменной длины. В качестве литер используются либо шестнадцатеричные цифры, которые воспринимаются группами и образуют целые величины, либо литеры, почерпнутые из набора ASCII для УМ-1, которые представляют сами себя [Чтобы вспомнить различие между внутренними и внешними литерами, перечитайте раздел о файле абсолютной загрузки в гл.25.]. Первые шесть литер записи всегда связаны с ее физической структурой и неизменно располагаются в одном и том же формате. Позиция 1 содержит литеру 1, если данная запись - последняя в модуле, и 0 - во всех остальных случаях. В позициях 2-4 определяется трехзначный шестнадцатеричный порядковый номер записи в модуле - самая первая запись имеет номер 000. Нарушение порядка номеров записей является нефатальной ошибкой. Когда в модуле набирается 1000 записей, порядковый номер продолжается с 000. В позициях 5 и 6 указывается шестнадцатеричная длина записи. Эта длина включает в себя первые шесть литер и лежит, следовательно, между 07 и FF. Содержательная информация записи располагается во второй ее части, непосредственно примыкающей к постоянной шапке, и состоит из последовательности логических элементов загрузки. Логические элементы загрузки на границах физической записи могут произвольно прерываться.
Логический элемент загрузки начинается с двух шестнадцатеричных цифр, идентифицирующих операцию загрузки, за которой следуют, если необходимо, параметры. Числовые параметры передаются всегда цепочкой шестнадцатеричных цифр такой длины, которая необходима для представления числа. Имена начинаются с поля счетчика из двух шестнадцатеричных цифр, за которым следуют фактические литеры имени - в количестве, указанном в счетчике. Таким образом, элемент 682C04Fool представляет собой операцию 68 - описание внешней ссылки с коротким номером символа 2C и именем Fool, состоящим из четырех литер. Если параметром служит выражение, оно содержит собственные операции и может быть сколь угодно длинным. Заметим, что для задания одной внутренней литеры берутся две внешние шестнадцатеричные цифры.
ОПИСАНИЕ ЭЛЕМЕНТОВ ЗАГРУЗКИ
Каждый отдельно взятый элемент загрузки характеризуется 8-разрядным кодом операции, двоичный формат которого показан во второй графе заголовка соответствующего пункта описания. Параметры, если таковые имеются, располагаются после кода операции. В названиях параметров содержатся общие указания об их употреблении. Не всегда можно сказать, насколько длинным окажется параметр. Параметры переменной длины будут всегда снабжаться указанием длины или явными ограничителями, Некоторые параметры окажутся запрятанными в коде операции.
ЭЛЕМЕНТЫ ЗАГРУЗКИ ДАННЫХ
Загрузка абсолютная 0000cccc Данные
Поле счетчика cccc содержит уменьшенное на единицу количество внутренних литер данных, подлежащих загрузке. Остальная часть элемента состоит из числовых данных, которые требуется загрузить без смещения с текущим САР. К счетчикам САР и СОР прибавляется длина загруженного объекта.
Загрузка слова со смещением 00010000 Данные
Счетчики размещения сдвигаются к границе четного байта, если они уже на нее не установлены, загружаемый элемент данных, содержащий 8 цифр, помещается в очередные четыре байта, младшие два байта получают смещение относительно начала модуля, и к счетчикам размещения прибавляется длина загруженного объекта.
Загрузка выражения 000110ww Выражение
Поле параметра ww содержит уменьшенное на единицу количество байтов, загружаемых из аргумента-выражения. При вычислении выражения используется 32 двоичных разряда, но по назначению употребляются лишь младшие разряды результата. К счетчикам размещения прибавляется длина загруженного объекта.
Загрузка относительно символа 0001010l Символ Данные
Счетчики размещения настраиваются на ближайшую границу четного байта, если они уже на нее не установлены. Загружается восемь цифр данных. К двум младшим байтам данных в памяти прибавляется значение символа, номер которого указан в первом аргументе. Номер символа содержит две цифры, если l=0, и четыре цифры, если l=1. Смещение должно задаваться перемещаемым символом, но само значение его может быть еще не определено.
ВЫРАЖЕНИЯ ПРИ ЗАГРУЗКЕ
Выражения, которые должны во время загрузки получить численные значения, вычисляются с использованием 32-разрядного сумматора, снабженного признаком типа (или АБСОЛЮТНОГО, или ОТНОСИТЕЛЬНОГО). Цепочка элементов загрузки, определяющих загружаемое выражение, может быть произвольной длины и во всех случаях оканчивается признаком конца выражения. В выражении могут употребляться лишь те символы, значения которых уже определены, и только в допустимых сочетаниях типов в соответствии с табл. 26.1. Последняя приведенная в таблице комбинация возможна лишь при условии, что оба элемента располагаются в текущем модуле. В исходном состоянии сумматор, как правило, равен абсолютному нулю.
Таблица 26.1. Допустимые комбинации типов операндов
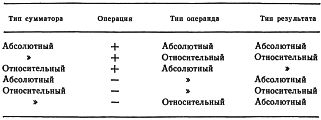
Арифметическая операция 0010lsot Операнд
Если бит o равен нулю, производится операция сложения; в противном случае - операция вычитания. Если бит s равен нулю, операнд представляет собой константу, и тогда бит t указывает на то, является ли константа абсолютной (t=0) или относительной (t=1). В противном случае (s=1) операнд представляет собой номер символа. Бит l указывает на то, содержит ли операнд две (l=0) или четыре (l=1) цифры. Операция выполняется, и значение соответствующего типа помещается на сумматор.
Установка СОР на сумматор 00110000 Нет
Текущее содержимое сумматора игнорируется, и в него помещается величина относительного типа, равная текущему значению СОР.
Конец выражения 00110001 Нет
Текущее выражение окончено, при этом на сумматоре находится его значение.
ОПРЕДЕЛЕНИЕ СИМВОЛОВ
Вообще говоря, символы должны декларироваться до их употребления, и именно описание связывает внутренний номер символа с его именем. Внутри любого данного модуля номера символов могут встречаться только один раз. Определения могут находиться в любом месте модуля. Имена символов допускаются любой длины от 0 до 255 литер. Имя любого символа состоит из поля длины (две цифры) и следующих за ним литер самого имени. В конце обработки модуля все имена, кроме внешних и имен в карте загрузки, надлежит из таблицы символов загрузчика исключить.
Определение внешнего символа 010lt000 Номер Выражение
Внешнему символу, номер которого задается первым аргументом, присваивается значение второго аргумента. Номер символа состоит из двух цифр при l=0 или четырех цифр в противном случае. Если бит t равен 0, то символ абсолютный, в противном случае - относительный. Типы определяющего выражения и уже занесенного в таблицу символа (тип символа задается параметром t) должны совпадать. Во время определения любые ссылки на символ должны быть заполнены.
Определение символа в карте 0100t001 Имя Выражение
Выражение, представленное вторым аргументом, вычисляется и приписывается символу, имя которого указано в первом аргументе, для последующего помещения в карту загрузки. Если t=0 то тип символа абсолютный, в противном случае - относительный.
Определение ссылки вперед 010lt01h Номер Выражение
Ссылке вперед, номер которой указан в первом аргументе, ставится в соответствие выражение, приведенное во втором аргументе. При l=0 номер ссылки состоит из двух цифр, в противном случае - из четырех. Символ является абсолютным, если t=0, и относительным в противном случае. Если h=0, то ссылка вперед сохраняется в таблице символов, в противном случае после данного определения ссылка исключается из таблицы.
Описание внешней ссылки 011lt00p Номер Имя
Символ с именем, указанным в аргументе, и номером, приведенным в первом аргументе, декларируется как ссылка на внешний символ другого модуля. Если l=0, номер символа состоит из двух цифр, в противном случае - из четырех. При t = 0 тип символа абсолютный, в противном случае - относительный. Равенство р=0 означает, что ссылка ПЕРВИЧНА и ее надлежит отыскать и заполнить; в противном случае ссылка ВТОРИЧНА, и ее необходимо заполнять, лишь если символ определяется по другой причине.
Описание ссылки вперед 011lt010 Номер
Декларируется ссылка вперед на символ, номер которого указан в аргументе. Если l=0, номер содержит две цифры, в противном случае - четыре. При t=0 символ абсолютный, в противном случае - относительный.
Описание внешнего имени 011lt011 Номер Имя
Символ с номером и именем, указанными соответственно в первом и втором аргументах, декларируется в качестве внешнего символа, который будет определен в данном модуле. Описания внешних имен должны располагаться в самом начале модуля. Если l=0, то номер символа содержит две цифры, в противном случае - четыре. При t=0 тип символа абсолютный, в противном случае - относительный.
Определение типов процедуры 011l0100 Номер N Тип1 ... ТипN
С символом, номер которого указан в первом аргументе, соотносится цепочка типов, длина которой задается двумя литерами второго аргумента. Если l=0, то номер символа состоит из двух цифр, в противном случае - из четырех. Каждый тип представляется одной литерой. Чтобы определить символ, он должен быть уже описан в этом разделе как внешний. Данная команда, как и последующая, может употребляться компилятором Мини для проверки правильности количества и типов аргументов внешних процедур. В компиляторе необходимо установить способ представления возможных типов аргументов в виде целых чисел, которого надо придерживаться при всех трансляциях.
Проверка типов процедуры 011l0101 Номер N Тип1 ... ТипN
Аргументы этой команды те же, что и в команде определения типов процедуры, с тем отличием, что символ должен быть внешней ссылкой текущего модуля. Перечисленные в команде типы сравниваются с типами указанного символа, и, если они в чем-то не совпадают, объявляется фатальная ошибка загрузки.
ПРОЧИЕ КОМАНДЫ
Установка начального адреса 10010000 Выражение
В качестве начального адреса загрузки устанавливается выражение, указанное в аргументе. Выражение должно быть относительным. Данная команда должна встретиться в загрузке ровно один раз. Нарушение этого условия приводит к фатальной ошибке загрузки. Начальный адрес должен присутствовать в карте загрузки в виде некоторого искусственного имени.
Установка на четный адрес 10100000
Оба счетчика размещения продвигаются до ближайшего четного адреса, если они уже на такой адрес не установлены.
Установка на адрес слова 10110000 Оба счетчика размещения продвигаются до адреса очередного слова, если они уже на такой адрес не установлены.
Установка счетчиков размещения 11000000 Выражение
Оба счетчика размещения принимают значение выражения, которое должно быть относительным и неотрицательным. Не забудьте, что САР-начало = СОР.
Пустая команда 11010000
Невыполняемая команда. Может встречаться в выражениях.
Конец модуля 11111111
Окончание текущего модуля. Если данная команда не встретится в физической записи, содержащей 1 в первом символе шапки, выдается сообщение о фатальной ошибке загрузки.
ПРИМЕР ПРОГРАММЫ
Для того чтобы разъяснить некоторые из введенных понятий, приведем образец программы на языке ассемблера УМ-1 и ее модуль загрузки, сгенерированный гипотетическим ассемблером. Что представляет собой сама программа, значения не имеет, важно лишь то, что она наглядно демонстрирует многие характерные черты загрузки. Вероятно, если бы присваивание именам номеров производилось реальным ассемблером, то оно было бы выполнено более логично. Загружаемая программа приведена БЕЗ разбивки по физическим записям и элементов управления ими, но с пояснениями, связывающими ее с языком ассемблера.

Теперь - язык загрузки. Все числа - шестнадцатеричные.


ТЕМА. Сконструируйте загрузчик УМ. На его вход должна поступать последовательность перемещаемых объектных файлов, а на выходе - как файл абсолютной загрузки, так и карта загрузки. Непременно сигнализируйте об ошибках загрузки. Необходимо, чтобы карта загрузки была отсортирована как по именам, так и по адресам. Содержащиеся в карте символы должны включать в себя внешние символы и ссылки, а также другие определенные символы. Кроме того, укажите размер каждого модуля.
УКАЗАНИЯ ИСПОЛНИТЕЛЮ. В большинстве загрузчиков время расходуется на два вида работ: организацию ввода/вывода и обработку таблицы символов. Очевидно, что коль скоро считывается и записывается большой объем информации, существует нижний предел времени, затрачиваемого на ввод/вывод. Тем не менее в данной работе упор должен делаться, во всяком случае, не на технику совершенствования ввода/вывода, да и язык высокого уровня, видимо, не очень-то способствует этому. А вот работу с таблицей символов, если ее тщательно продумать, улучшить можно. Поэтому надо так спланировать загрузчик, чтобы можно было легко подключать и отключать разные программы обработки таблиц символов. Напишите простую программу управления таблицами, отладьте загрузчик полностью, а потом попытайтесь совершенствовать операции с символами.
Накопленный опыт показывает, что работу по подготовке тестирующих программ надо начинать пораньше. Перевод языка ассемблера в модуль загрузки оказывается труднее, чем может показаться. Не исключено, что вам захочется применить ассемблер для УМ-1, предлагавшийся в гл.25 в качестве средства отладки. Постарайтесь воспользоваться каждой командой по крайней мере один раз.
ИНСТРУМЕНТОВКА. Используйте любой процедурный язык высокого уровня. Однако возможности выбора языка не безграничны, хотя в них и имеются средства работы с битами. Помните, что необходимо читать записи переменной длины.
ДЛИТЕЛЬНОСТЬ ИСПОЛНЕНИЯ. Одному исполнителю на шесть недель; двоим или троим - на 3 недели. Каждый участник должен сделать одну тестовую программу в перемещаемом объектном коде.
ЛИТЕРАТУРА
Баррон (Barron D.W.). Assemblers and Loaders. Macdonald, London, 1969. [Имеется перевод: Баррон Д. Ассемблеры и загрузчики.- М.: Мир, 1974.]
Прессер, Уайт (Presser L., White J.R.). Linkers and Loaders, Comput. Surveys, 4, 3, pp.149-167, 1972.
Книга Баррона представляет собой элементарное введение в ассемблеры и загрузчики. Описанный в ней загрузчик близок к нашему и вместе с тем рассмотрен более подробно. Прессер и Уайт описывают систему, применяемую на IBM 360. Поскольку в системе 360 исключено перемещение, чего нельзя сказать о других системах, основное внимание уделяется связыванию программ.
ПИЩА ДЛЯ УМА,
ИЛИ...
СВЯЗЫВАЮЩИЙ ЗАГРУЗЧИК
В большинстве систем загрузчики находятся на положении пасынков. Их не любят пользователи, считая просто лишним препятствием на пути к вожделенному ответу. Они не нравятся и разработчикам компиляторов, поскольку являются составной частью системы (а вы считаете, что это не так?). Не по душе они и системным программистам, которые видят в них не более чем еще одно вспомогательное средство. Разве только коммерческие директора питают слабость к загрузчику за то, что он расходует так много машинного времени (и денег). Тем не менее, написав загрузчик для УМ-1, вы убедитесь, что его создание - очень стоящая задача.
Загрузчик УМ представляет собой довольно стандартный настраивающий загрузчик, предназначенный для работы с языком Мини (гл.27) и ЭВМ УМ-1 (гл.25). Основные функции загрузчика УМ связаны с интерпретацией перемещаемого языка загрузки, обработкой достаточно сложных таблиц символов и регистрацией ошибок в ходе загрузки. Программы на языке Мини могут состоять из независимо скомпилированных программных сегментов, и загрузчик УМ обеспечивает проверку соответствия типов величин, общих для нескольких сегментов, и библиотечный поиск для сборки полных программ. Кроме того, перемещаемый язык загрузки позволяет настолько просто генерировать команды перехода вперед, что компиляторы могут быть не двух-, а однопроходными. Многие находящиеся в эксплуатации загрузчики предусматривают еще более сложную обработку, однако такая обработка требует весьма развитой системы ввода/вывода и поэтому неприемлема для этюда. Не исключено, что вы не сможете до конца прочувствовать загрузчик УМ (как сильные, так и слабые его стороны), пока не сконструируете компилятор или же специально не изучите загрузчики по литературе.
ОБЩАЯ СХЕМА ЗАГРУЗЧИКА
На вход загрузчика УМ поступают ПРОГРАММНЫЙ ФАЙЛ и БИБЛИОТЕЧНЫЙ ФАЙЛ, причем каждый из них может состоять из некоторого числа модулей. Если же позволяет система, то программа или библиотека могут состоять более чем из одного файла. Загружены должны быть в первую очередь все модули программы, а модули из библиотечного файла загружаются, лишь если они соответствуют первичным ссылкам. К концу загрузки должен определиться ровно один начальный адрес программы, иначе фиксируется фатальная ошибка загрузки. В результате работы загрузчика получается ФАЙЛ АБСОЛЮТНОЙ ЗАГРУЗКИ, который описывался в гл.25. Загрузчик УМ содержит как счетчик абсолютного размещения (САР), так и счетчик относительного размещения (СОР). Перед началом загрузки САР устанавливается на адрес 40. Всякий раз, когда начинается очередной модуль, САР настраивается на ближайшую свободную границу слова, а СОР обнуляется [Вообще, если A есть начальный адрес текущего загружаемого модуля, то всегда выполняется соотношение САР-А = СОР. То есть САР и СОР при всех обстоятельствах изменяются согласованно, образуя тандем]). После того как загружен последний модуль, САР а последний раз продвигается к границе слова, следующего за верхней точкой модуля, и употребляется для определения значения абсолютного внешнего символа МАКСИМАЛЬНЫЙ АДРЕС.
ПЕРЕМЕЩАЕМЫЙ ЯЗЫК ЗАГРУЗКИ состоит из набора КОМАНД ЗАГРУЗКИ, длиной восемь битов каждая. Команды записываются с помощью КОДИРОВОК ПЕРЕМЕННОЙ ДЛИНЫ, при этом отдельные параметры могут оказаться запрятанными в самих командах. Остальные параметры могут быть переменной длины, а употребляемые в командах выражения допускаются любой сложности. Все имена должны быть декларированы до их использования; описанные однажды, они везде ниже заменяются на их порядковые номера с целью уменьшения размера загрузочного модуля. Поскольку модули должны генерироваться однопроходным компилятором Мини, их размер в явном виде не указан. Поэтому загрузчик УМ должен следить за МАРКЕРОМ КОНЦА, который позволит установить размер модуля. Внешние имена, встречающиеся в текущем модуле, должны быть описаны раньше всех других спецификаций загрузки. После того как все модули обработаны, из таблицы символов необходимо исключить все внутренние имена, глобальные символы сохранить и проделать соответствующие манипуляции с КАРТОЙ ЗАГРУЗКИ. Для целей диагностики можно ввести специальные символы, употребляемые только в карте загрузки. Загрузчик УМ в состоянии проверять типы внешних процедур и их аргументов.
СТРУКТУРА ФИЗИЧЕСКОЙ ЗАПИСИ
Записи в модуле загрузки представляют собой цепочки внешних литер переменной длины. В качестве литер используются либо шестнадцатеричные цифры, которые воспринимаются группами и образуют целые величины, либо литеры, почерпнутые из набора ASCII для УМ-1, которые представляют сами себя [Чтобы вспомнить различие между внутренними и внешними литерами, перечитайте раздел о файле абсолютной загрузки в гл.25.]. Первые шесть литер записи всегда связаны с ее физической структурой и неизменно располагаются в одном и том же формате. Позиция 1 содержит литеру 1, если данная запись - последняя в модуле, и 0 - во всех остальных случаях. В позициях 2-4 определяется трехзначный шестнадцатеричный порядковый номер записи в модуле - самая первая запись имеет номер 000. Нарушение порядка номеров записей является нефатальной ошибкой. Когда в модуле набирается 1000 записей, порядковый номер продолжается с 000. В позициях 5 и 6 указывается шестнадцатеричная длина записи. Эта длина включает в себя первые шесть литер и лежит, следовательно, между 07 и FF. Содержательная информация записи располагается во второй ее части, непосредственно примыкающей к постоянной шапке, и состоит из последовательности логических элементов загрузки. Логические элементы загрузки на границах физической записи могут произвольно прерываться.
Логический элемент загрузки начинается с двух шестнадцатеричных цифр, идентифицирующих операцию загрузки, за которой следуют, если необходимо, параметры. Числовые параметры передаются всегда цепочкой шестнадцатеричных цифр такой длины, которая необходима для представления числа. Имена начинаются с поля счетчика из двух шестнадцатеричных цифр, за которым следуют фактические литеры имени - в количестве, указанном в счетчике. Таким образом, элемент 682C04Fool представляет собой операцию 68 - описание внешней ссылки с коротким номером символа 2C и именем Fool, состоящим из четырех литер. Если параметром служит выражение, оно содержит собственные операции и может быть сколь угодно длинным. Заметим, что для задания одной внутренней литеры берутся две внешние шестнадцатеричные цифры.
ОПИСАНИЕ ЭЛЕМЕНТОВ ЗАГРУЗКИ
Каждый отдельно взятый элемент загрузки характеризуется 8-разрядным кодом операции, двоичный формат которого показан во второй графе заголовка соответствующего пункта описания. Параметры, если таковые имеются, располагаются после кода операции. В названиях параметров содержатся общие указания об их употреблении. Не всегда можно сказать, насколько длинным окажется параметр. Параметры переменной длины будут всегда снабжаться указанием длины или явными ограничителями, Некоторые параметры окажутся запрятанными в коде операции.
ЭЛЕМЕНТЫ ЗАГРУЗКИ ДАННЫХ
Загрузка абсолютная 0000cccc Данные
Поле счетчика cccc содержит уменьшенное на единицу количество внутренних литер данных, подлежащих загрузке. Остальная часть элемента состоит из числовых данных, которые требуется загрузить без смещения с текущим САР. К счетчикам САР и СОР прибавляется длина загруженного объекта.
Загрузка слова со смещением 00010000 Данные
Счетчики размещения сдвигаются к границе четного байта, если они уже на нее не установлены, загружаемый элемент данных, содержащий 8 цифр, помещается в очередные четыре байта, младшие два байта получают смещение относительно начала модуля, и к счетчикам размещения прибавляется длина загруженного объекта.
Загрузка выражения 000110ww Выражение
Поле параметра ww содержит уменьшенное на единицу количество байтов, загружаемых из аргумента-выражения. При вычислении выражения используется 32 двоичных разряда, но по назначению употребляются лишь младшие разряды результата. К счетчикам размещения прибавляется длина загруженного объекта.
Загрузка относительно символа 0001010l Символ Данные
Счетчики размещения настраиваются на ближайшую границу четного байта, если они уже на нее не установлены. Загружается восемь цифр данных. К двум младшим байтам данных в памяти прибавляется значение символа, номер которого указан в первом аргументе. Номер символа содержит две цифры, если l=0, и четыре цифры, если l=1. Смещение должно задаваться перемещаемым символом, но само значение его может быть еще не определено.
ВЫРАЖЕНИЯ ПРИ ЗАГРУЗКЕ
Выражения, которые должны во время загрузки получить численные значения, вычисляются с использованием 32-разрядного сумматора, снабженного признаком типа (или АБСОЛЮТНОГО, или ОТНОСИТЕЛЬНОГО). Цепочка элементов загрузки, определяющих загружаемое выражение, может быть произвольной длины и во всех случаях оканчивается признаком конца выражения. В выражении могут употребляться лишь те символы, значения которых уже определены, и только в допустимых сочетаниях типов в соответствии с табл. 26.1. Последняя приведенная в таблице комбинация возможна лишь при условии, что оба элемента располагаются в текущем модуле. В исходном состоянии сумматор, как правило, равен абсолютному нулю.
Таблица 26.1. Допустимые комбинации типов операндов

Арифметическая операция 0010lsot Операнд
Если бит o равен нулю, производится операция сложения; в противном случае - операция вычитания. Если бит s равен нулю, операнд представляет собой константу, и тогда бит t указывает на то, является ли константа абсолютной (t=0) или относительной (t=1). В противном случае (s=1) операнд представляет собой номер символа. Бит l указывает на то, содержит ли операнд две (l=0) или четыре (l=1) цифры. Операция выполняется, и значение соответствующего типа помещается на сумматор.
Установка СОР на сумматор 00110000 Нет
Текущее содержимое сумматора игнорируется, и в него помещается величина относительного типа, равная текущему значению СОР.
Конец выражения 00110001 Нет
Текущее выражение окончено, при этом на сумматоре находится его значение.
ОПРЕДЕЛЕНИЕ СИМВОЛОВ
Вообще говоря, символы должны декларироваться до их употребления, и именно описание связывает внутренний номер символа с его именем. Внутри любого данного модуля номера символов могут встречаться только один раз. Определения могут находиться в любом месте модуля. Имена символов допускаются любой длины от 0 до 255 литер. Имя любого символа состоит из поля длины (две цифры) и следующих за ним литер самого имени. В конце обработки модуля все имена, кроме внешних и имен в карте загрузки, надлежит из таблицы символов загрузчика исключить.
Определение внешнего символа 010lt000 Номер Выражение
Внешнему символу, номер которого задается первым аргументом, присваивается значение второго аргумента. Номер символа состоит из двух цифр при l=0 или четырех цифр в противном случае. Если бит t равен 0, то символ абсолютный, в противном случае - относительный. Типы определяющего выражения и уже занесенного в таблицу символа (тип символа задается параметром t) должны совпадать. Во время определения любые ссылки на символ должны быть заполнены.
Определение символа в карте 0100t001 Имя Выражение
Выражение, представленное вторым аргументом, вычисляется и приписывается символу, имя которого указано в первом аргументе, для последующего помещения в карту загрузки. Если t=0 то тип символа абсолютный, в противном случае - относительный.
Определение ссылки вперед 010lt01h Номер Выражение
Ссылке вперед, номер которой указан в первом аргументе, ставится в соответствие выражение, приведенное во втором аргументе. При l=0 номер ссылки состоит из двух цифр, в противном случае - из четырех. Символ является абсолютным, если t=0, и относительным в противном случае. Если h=0, то ссылка вперед сохраняется в таблице символов, в противном случае после данного определения ссылка исключается из таблицы.
Описание внешней ссылки 011lt00p Номер Имя
Символ с именем, указанным в аргументе, и номером, приведенным в первом аргументе, декларируется как ссылка на внешний символ другого модуля. Если l=0, номер символа состоит из двух цифр, в противном случае - из четырех. При t = 0 тип символа абсолютный, в противном случае - относительный. Равенство р=0 означает, что ссылка ПЕРВИЧНА и ее надлежит отыскать и заполнить; в противном случае ссылка ВТОРИЧНА, и ее необходимо заполнять, лишь если символ определяется по другой причине.
Описание ссылки вперед 011lt010 Номер
Декларируется ссылка вперед на символ, номер которого указан в аргументе. Если l=0, номер содержит две цифры, в противном случае - четыре. При t=0 символ абсолютный, в противном случае - относительный.
Описание внешнего имени 011lt011 Номер Имя
Символ с номером и именем, указанными соответственно в первом и втором аргументах, декларируется в качестве внешнего символа, который будет определен в данном модуле. Описания внешних имен должны располагаться в самом начале модуля. Если l=0, то номер символа содержит две цифры, в противном случае - четыре. При t=0 тип символа абсолютный, в противном случае - относительный.
Определение типов процедуры 011l0100 Номер N Тип1 ... ТипN
С символом, номер которого указан в первом аргументе, соотносится цепочка типов, длина которой задается двумя литерами второго аргумента. Если l=0, то номер символа состоит из двух цифр, в противном случае - из четырех. Каждый тип представляется одной литерой. Чтобы определить символ, он должен быть уже описан в этом разделе как внешний. Данная команда, как и последующая, может употребляться компилятором Мини для проверки правильности количества и типов аргументов внешних процедур. В компиляторе необходимо установить способ представления возможных типов аргументов в виде целых чисел, которого надо придерживаться при всех трансляциях.
Проверка типов процедуры 011l0101 Номер N Тип1 ... ТипN
Аргументы этой команды те же, что и в команде определения типов процедуры, с тем отличием, что символ должен быть внешней ссылкой текущего модуля. Перечисленные в команде типы сравниваются с типами указанного символа, и, если они в чем-то не совпадают, объявляется фатальная ошибка загрузки.
ПРОЧИЕ КОМАНДЫ
Установка начального адреса 10010000 Выражение
В качестве начального адреса загрузки устанавливается выражение, указанное в аргументе. Выражение должно быть относительным. Данная команда должна встретиться в загрузке ровно один раз. Нарушение этого условия приводит к фатальной ошибке загрузки. Начальный адрес должен присутствовать в карте загрузки в виде некоторого искусственного имени.
Установка на четный адрес 10100000
Оба счетчика размещения продвигаются до ближайшего четного адреса, если они уже на такой адрес не установлены.
Установка на адрес слова 10110000 Оба счетчика размещения продвигаются до адреса очередного слова, если они уже на такой адрес не установлены.
Установка счетчиков размещения 11000000 Выражение
Оба счетчика размещения принимают значение выражения, которое должно быть относительным и неотрицательным. Не забудьте, что САР-начало = СОР.
Пустая команда 11010000
Невыполняемая команда. Может встречаться в выражениях.
Конец модуля 11111111
Окончание текущего модуля. Если данная команда не встретится в физической записи, содержащей 1 в первом символе шапки, выдается сообщение о фатальной ошибке загрузки.
ПРИМЕР ПРОГРАММЫ
Для того чтобы разъяснить некоторые из введенных понятий, приведем образец программы на языке ассемблера УМ-1 и ее модуль загрузки, сгенерированный гипотетическим ассемблером. Что представляет собой сама программа, значения не имеет, важно лишь то, что она наглядно демонстрирует многие характерные черты загрузки. Вероятно, если бы присваивание именам номеров производилось реальным ассемблером, то оно было бы выполнено более логично. Загружаемая программа приведена БЕЗ разбивки по физическим записям и элементов управления ими, но с пояснениями, связывающими ее с языком ассемблера.

Теперь - язык загрузки. Все числа - шестнадцатеричные.


ТЕМА. Сконструируйте загрузчик УМ. На его вход должна поступать последовательность перемещаемых объектных файлов, а на выходе - как файл абсолютной загрузки, так и карта загрузки. Непременно сигнализируйте об ошибках загрузки. Необходимо, чтобы карта загрузки была отсортирована как по именам, так и по адресам. Содержащиеся в карте символы должны включать в себя внешние символы и ссылки, а также другие определенные символы. Кроме того, укажите размер каждого модуля.
УКАЗАНИЯ ИСПОЛНИТЕЛЮ. В большинстве загрузчиков время расходуется на два вида работ: организацию ввода/вывода и обработку таблицы символов. Очевидно, что коль скоро считывается и записывается большой объем информации, существует нижний предел времени, затрачиваемого на ввод/вывод. Тем не менее в данной работе упор должен делаться, во всяком случае, не на технику совершенствования ввода/вывода, да и язык высокого уровня, видимо, не очень-то способствует этому. А вот работу с таблицей символов, если ее тщательно продумать, улучшить можно. Поэтому надо так спланировать загрузчик, чтобы можно было легко подключать и отключать разные программы обработки таблиц символов. Напишите простую программу управления таблицами, отладьте загрузчик полностью, а потом попытайтесь совершенствовать операции с символами.
Накопленный опыт показывает, что работу по подготовке тестирующих программ надо начинать пораньше. Перевод языка ассемблера в модуль загрузки оказывается труднее, чем может показаться. Не исключено, что вам захочется применить ассемблер для УМ-1, предлагавшийся в гл.25 в качестве средства отладки. Постарайтесь воспользоваться каждой командой по крайней мере один раз.
ИНСТРУМЕНТОВКА. Используйте любой процедурный язык высокого уровня. Однако возможности выбора языка не безграничны, хотя в них и имеются средства работы с битами. Помните, что необходимо читать записи переменной длины.
ДЛИТЕЛЬНОСТЬ ИСПОЛНЕНИЯ. Одному исполнителю на шесть недель; двоим или троим - на 3 недели. Каждый участник должен сделать одну тестовую программу в перемещаемом объектном коде.
ЛИТЕРАТУРА
Баррон (Barron D.W.). Assemblers and Loaders. Macdonald, London, 1969. [Имеется перевод: Баррон Д. Ассемблеры и загрузчики.- М.: Мир, 1974.]
Прессер, Уайт (Presser L., White J.R.). Linkers and Loaders, Comput. Surveys, 4, 3, pp.149-167, 1972.
Книга Баррона представляет собой элементарное введение в ассемблеры и загрузчики. Описанный в ней загрузчик близок к нашему и вместе с тем рассмотрен более подробно. Прессер и Уайт описывают систему, применяемую на IBM 360. Поскольку в системе 360 исключено перемещение, чего нельзя сказать о других системах, основное внимание уделяется связыванию программ.
Gudleifr- Admin
- Сообщения : 3252
Дата регистрации : 2017-03-29
Re: Уэзерелл. Этюды для программистов. 1982
автор Gudleifr Вт Мар 02, 2021 12:32 pm
27
МАЛ ЗОЛОТНИК...
ИЛИ...
КОМПИЛЯТОР ДЛЯ АЛГЕБРАИЧЕСКОГО ЯЗЫКА
Компилятор - это всегда большая программа. Написать его, практически на пустом месте, даже под опекой преподавателей вовсе не просто. И хотя при создании Мини ставилась цель свести все муки к минимуму, во всяком случае в той мере, в какой это позволяло его просветительское назначение, предлагаемая задача все же оказалась самой трудной в книге. Если вы (и ваши верные друзья) не обладаете достаточной энергией и временем, то не стоит за нее и браться.
ЯЗЫК МИНИ
Мини - универсальный, процедурный, алгебраический язык программирования. Он уходит своими корнями в Алгол, Алгол 68 и Паскаль. Подобно этим языкам, Мини предназначен для компиляции, загрузки и выполнения на обычных ЭВМ (хорошим примером такой машины служит УМ-1, см. гл.25). Синтаксис задается контекстно-свободной грамматикой, пригодной для разбора методами LR(1). Семантика аналогична алгольной и паскалевой, и нам кажется достаточным ее неформальное описание. Квалификация читателя позволит ему домыслить все недосказанное [Стиль последующего изложения показывает, сколь высоко оценивает автор квалификацию своих читателей.- Прим. перев.]. Ниже приведены логически связанные части грамматики и их семантика.
ЕДИНИЦЫ КОМПИЛЯЦИИ
<единица компиляции> ::= <программный сегмент> | <единица компиляции> <программный сегмент>
<программный сегмент> ::= <главная программа> | <внешняя процедура>
<Единица компиляции> - это цепочка замкнутых <программных сегментов> [В русском переводе приходится склонять нетерминальные символы грамматики.- Прим. перев.]. Каждый (программный сегмент) есть либо <главная программа>, либо <внешняя процедура>. Все сегменты (единицы компиляции) свяжет друг с другом загрузчик, однако не обязательно, чтобы все сегменты, нужные для полной загрузки, компилировались вместе. При загрузке должна присутствовать ровно одна <главная программа>.
ПРОГРАММЫ
<главная программа> ::= <заголовок программы> <тело программы> <конец программы>
<заголовок программы> ::= PROGRAM <идентификатор>:
<тело программы> ::= <тело сегмента>
<конец программы> ::= END PROGRAM <идентификатор>;
Каждая <главная программа> именована, и закрывающее имя должно совпадать с открывающим. <Тело программы>, подобно большинству других сгруппированных инструкций, есть <тело сегмента> и может содержать все, что обычно свойственно программам. Заметим также, что резервированные слова, идентификаторы и константы не должны разрываться на границах записей. Их следует отделять друг от друга пробелами, знаками операций, комментариями или границами записей.
ВНЕШНИЕ ПРОЦЕДУРЫ
<внешняя процедура> ::= <внешняя подпрограмма> | <внешняя функция>
<внешняя подпрограмма> ::= <заголовок внешней подпрограммы>: <тело внешней подпрограммы> <конец внешней подпрограммы>
<внешняя функция> ::= <заголовок внешней функции>: <тело внешней функции> <конец внешней функции>
<заголовок внешней подпрограммы> ::= EXTERNAL PROCEDURE <имя внешней процедуры>
<заголовок внешней функции> ::= EXTERNAL FUNCTION <имя внешней процедуры> <внешний тип>
<имя внешней процедуры> ::= <идентификатор> | <идентификатор> <список внешних параметров>
<список внешних параметров> ::= <заголовок внешних параметров>)
<заголовок внешних параметров> ::= (<внешний параметр> | <заголовок внешних параметров>, <внешний параметр>
<внешний параметр> ::= <идентификатор> <внешний тип> | <идентификатор> <внешний тип> NAME
<внешний тип> ::= <базовый тип>
<тело внешней подпрограммы> ::= <тело сегмента>
<тело внешней функции> ::= <тело сегмента>
<конец внешней подпрограммы> ::= END EXTERNAL PROCEDURE <идентификатор>;
<конец внешней функции> ::= END EXTERNAL FUNCTION <идентификатор>;
<Внешние процедуры> позволяют компилировать модули раздельно и собирать их вместе во время загрузки. При загрузке допускается лишь одна (внешняя процедура> с данным именем. <Внешние параметры> и возвращаемые <внешними функциями> значения должны иметь <базовый тип>. <Внешние параметры> передаются по значению, если они не помечены резервированным словом NAME; при наличии этого слова параметры передаются по имени. Перед <концом внешней подпрограммы> неявно располагается <инструкция возврата>, однако <внешние функции> должны завершать работу явной <инструкцией возврата> с возвращаемым значением; попытка выхода из <внешней функции> через <конец внешней функции> является семантической ошибкой, которую иногда можно обнаружить при компиляции. Единственной связью между переменными <внешней процедуры> и переменными вызывающей процедуры служит механизм передачи параметров. Однако во время сборки сегментов (например, с помощью загрузчика, подобного описанному в гл.26) будет проверено совпадение типов формальных и фактических параметров, функций и возвращаемых значений.
Из описания <внешних процедур> усматривается несколько важных различий между Мини и современными языками. В коммерческом языке целесообразно обеспечивать средства для разделения деклараций всех видов между <программными сегментами>. На наш взгляд, усложнения, вносимые в язык такой возможностью, слишком велики по сравнению с педагогическим эффектом от их реализации: это же справедливо по отношению к расширению диапазона возможных типов параметров <внешних процедур>. С другой стороны, коммерческие языки в своем большинстве не допускают передачу параметров по имени (из соображений эффективности), в то время как студента, овладевшего механизмом передачи по имени, не смутить уже, кажется, ничем. Мини многословнее аналогичных языков, поскольку современные исследования показали важность умело распределенной избыточности для исправления синтаксических ошибок. Кроме того, программист, пишущий на Мини, должен явно различать декларации подпрограмм и функций. Хотя компилятор и может самостоятельно выявить различие, язык заставляет программиста явно демонстрировать свои намерения [Одной из главных трудностей при доказательстве правильности программ является выделение смысла программы из написанных программистом императивов. Поскольку правильность зависит отображений желаемого в действительное, ценно все, что помогает вскрыть намерения. Вводимое в Мини разграничение функций и подпрограмм - шажок в этом направлении. Заметим также, что хороший программист никогда не использует процедуру и как функцию, и как подпрограмму, ну а Мини просто придает этому правилу силу закона]. Наконец, Мини позволяет полностью проверить совпадение типов во время компиляции и загрузки, следуя неписаному закону: во время выполнения нужно делать как можно меньше.
СЕГМЕНТЫ
<тело сегмента> ::= <раздел определения типов>
<раздел декларации переменных> <раздел определения процедур> <раздел выполняемых инструкций>
<раздел определения типов> ::= | <раздел определения типов> <определение типа>
<раздел декларации переменных> ::= | <раздел декларации переменных> <декларация переменных>
<раздел определения процедур> ::= | <раздел определения процедур> <определение процедуры>
<раздел выполняемых инструкций> ::= <выполняемая инструкция> | <раздел выполняемых инструкций> <выполняемая инструкция>
<Тело сегмента> состоит не менее чем из одной <выполняемой инструкции>, которой, возможно, предшествуют <определения типов>, <декларации переменных> и <определения процедур>. Область действия любого имени - вся оставшаяся часть тела данного сегмента; это имя можно использовать в следующих определениях и декларациях. Одно и то же имя нельзя декларировать или определять дважды в <теле сегмента>. Как и в Алголе, имя можно переопределить или передекларировать во внутреннем <теле сегмента>.
ТИПЫ
<определение типа> ::= TYPE <идентификатор> IS <тип>
<тип> ::== <базовый тип> | <массивный тип> | <структурный тип> | <идентификатор типа>
<базовый тип> ::= INTEGER | REAL | BOOLEAN | STRING
<массивный тип> ::= ARRAY <границы> OF <тип>
<границы> ::= [<граничное выражение>] | [<граничное выражение>: <граничное выражение>]
<граничное выражение> ::= <выражение>
<структурный тип> ::= STRUCTURE <список полей> END STRUCTURE
<список полей> ::= <поле> | <список полей>, <поле>
<поле> ::== FIELD <идентификатор> IS <тип>
<идентификатор типа> ::= <идентификатор>
<Определение типа> вводит для <типа> сокращение-<идентификатор>. В дальнейшем это сокращение можно использовать везде, где мог бы стоять <тип>. В набор типов входят встроенные <базовые типы>, однородные <массивные типы>, разнородные <структурные типы> и сокращения - <идентификаторы типов>. <Базовые типы> INTEGER и REAL могут отображаться на соответствующие аппаратные типы и подчиняться обычным правилам. <Базовый тип> BOOLEAN состоит всего из двух констант TRUE и FALSE. Элементами типа STRING являются цепочки литер произвольной длины, ("степень произвола" может зависеть от реализации), но не менее нескольких тысяч.
Массивы имеют одно измерение, однако их компоненты могут иметь произвольный тип, так что допускается декларация массива массивов... Если нижняя граница массива не задана явно, она полагается равной единице. <Граничные выражения> могут быть сколь угодно сложными, лишь бы их значение сводилось к типу INTEGER. В эти выражения могут входить только переменные, декларированные в объемлющих <телах сегментов> (но не в текущем <теле сегмента>) или в списке параметров объемлющей процедуры. Верхняя граница должна быть не меньше нижней. Там, где возможно, компилятор должен проверять это условие, однако в общем случае требуется проверка во время выполнения. Разные вхождения одинаковых <массивных типов> не рассматриваются компилятором как один и тот же <тип> при проверках совпадения типов. Чтобы допустить неоднократное использование, <массивный тип> нужно обозначить <идентификатором типа>.
<Структурный тип> аналогичен записям в Паскале. <Идентификаторы> полей используются для именования элементов с <типами> полей. Поскольку определение рекурсивно, структуры могут иметь подструктуры. Конкретный <идентификатор> может именовать только одно <поле> <структурного типа>, однако допускается его использование и как имени переменной, и как имени поля другого (даже вложенного) <структурного типа>.
ДЕКЛАРАЦИИ
<декларация переменных> ::= DECLARE <декларируемые имена> <тип>;
<декларируемые имена> ::== <идентификатор> | <список декларируемых имен>)
<список декларируемых имен> ::= (<идентификатор> | <список декларируемых имен>, <идентификатор>
<Декларация переменных> наделяет <типом> <идентификаторы>, употребленные среди <декларируемых имен>. <Идентификаторы> не получают начальных значений. Имя (кроме имени поля) в <теле сегмента> может определяться или декларироваться не более одного раза.
ВНУТРЕННИЕ ПРОЦЕДУРЫ
<определение процедуры> ::= <определение подпрограммы> | <определение функции> | <определение внешней подпрограммы> | <определение внешней функции>
<определение подпрограммы> ::= <заголовок подпрограммы>: <тело подпрограммы> <конец подпрограммы>
<определение функции> ::= <заголовок функции>: <тело функции> <конец функции>
<определение внешней подпрограммы> ::= <заголовок внешней подпрограммы>;
<определение внешней функции> ::= <заголовок внешней функции>;
<заголовок подпрограммы> ::= PROCEDURE <имя процедуры>
<заголовок функции> ::= FUNCTION <имя процедуры><тип>
<тело подпрограммы> ::= <тело сегмента>
<тело функции> ::= <тело сегмента>
<конец подпрограммы> ::= END PROCEDURE <идентификатор>;
<конец функции> ::= END FUNCTION <идентификатор>;
<имя процедуры> ::= <идентификатор> | <идентификатор> <список внутренних параметров>
<список внутренних параметров> ::= <заголовок внутренних параметров>)
<заголовок внутренних параметров> ::= (<внутренний параметр | <заголовок внутренних параметров>, <внутренний параметр>
<внутренний параметр> ::= <идентификатор> <тип> | <идентификатор> <тип> NAME
Непосредственно в <теле сегмента> можно определить лишь одну процедуру с данным именем. Определение <внешней подпрограммы> или <внешней функции> дается только заголовком, поскольку тело <внешней процедуры> доставит та же или другая <единица компиляции>. В локальном и окончательном определении процедуры должны совпадать имя процедуры, порядок, тип и способ передачи формальных параметров; это соответствие проверит загрузчик. Напомним, что параметры <внешней процедуры> должны иметь <базовый тип>.
Определение локальных процедур дается аналогично. <Внутренние параметры>, так же как и возвращаемые функциями значения, могут иметь любой <тип>. Перед <концом подпрограммы> располагается неявная <инструкция возврата>. Выход из функции должен осуществляться посредством явной <инструкции возврата>, снабженной значением. Параметры с пометкой NAME передаются по имени, остальные - по значению. Сами по себе процедуры напоминают алгольные. Рекурсия допускается в полном объеме. <Имя процедуры> нельзя использовать до его декларации.
ВЫПОЛНЯЕМЫЕ ИНСТРУКЦИИ
<выполняемая инструкция> ::= <инструкция присваивания> | <инструкция вызова> | <инструкция возврата> | <инструкция завершения> | <условная инструкция> | <составная инструкция> | <инструкция цикла> | <инструкция выбора> | <инструкция возобновления> | <инструкция выхода>| <инструкция ввода> | <инструкция вывода> | <пустая инструкция>
Поскольку используются принятые в Алголе 68 условные инструкции и инструкции цикла, нет нужды разбивать их на несколько отдельных синтаксических классов. Все инструкции должны завершаться точкой с запятой.
ПРИСВАИВАНИЯ
<инструкция присваивания> ::= SET <список целей> <выражение>;
<список целей> ::= <цель> | <список целей> <цель>
<цель> ::= <переменная> <заменить на>
<заменить на> ::= :=
В <инструкции присваивания> <тип> всех <целей> и <тип> присваиваемого <выражения> должен быть одним и тем же. <Цели> обрабатываются слева направо, чтобы определить адреса в памяти, и только затем вычисляется выражение, чтобы найти запоминаемое значение. Структуры и массивы можно присваивать в случае совпадения <типов>. Использование ключевого слова SET служит примером многословности Мини. Данная избыточность помогает исправлению, когда неправильно записано другое ключевое слово (распространенная ошибка).
ВЫЗОВЫ ПРОЦЕДУР
<инструкция вызова> ::= CALL <обращение к процедуре>;
<обращение к процедуре> ::= <идентификатор процедуры> | <идентификатор процедуры> <список фактических параметров>
<идентификатор процедуры> ::= <идентификатор>
<список фактических параметров> ::= <заголовок фактических параметров>)
<заголовок фактических параметров> ::= (<выражение> | <заголовок фактических параметров>, <выражение>
Можно вызывать только процедуры, получившие определения а областью действия, содержащей <инструкцию вызова>. Количество, порядок и типы фактических и формальных параметров должны совпадать. После того как в вызываемой процедуре выполнится <инструкция возврата>, управление будет передано на следующую за вызовом инструкцию. Ключевое слово CALL используется по тем же соображениям, что и SET в <инструкции присваивания>.
ВОЗВРАТЫ
<инструкция возврата> ::= RETURN; | RETURN <выражение>;
<Инструкция возврата> может употребляться только в процедуре. Она возвращает управление в вызывающую инструкцию, В конце подпрограммы имеется неявная <инструкция возврата>. При возврате из подпрограммы значение указывать нельзя. При возврате из функции значение указывать обязательно. Оно должно иметь тот же тип, что и функция.
ИНСТРУКЦИИ ЗАВЕРШЕНИЯ
<инструкция завершения> ::= EXIT;
Данная инструкция вызывает нормальное завершение всей программы и возврат в супервизор. Она должна быть последней выполненной <не обязательно последней написанной> инструкцией <программы>.
УСЛОВНЫЕ ИНСТРУКЦИИ
<условная инструкция> ::= <простая условная инструкция> | <метка> <простая условная инструкция>
<простая условная инструкция> ::= <спецификация условия> <истинная ветвь> FI; | <спецификация условия> <истинная ветвь> <ложная ветвь> FI;
<спецификация условия> ::= IF <выражение>
<истинная ветвь> ::= THEN <тело условной инструкции>
<ложная ветвь> ::= <иначе> <тело условной инструкции>
<иначе> ::= ELSE
<тело условной инструкции> ::= <тело сегмента>
В <условной инструкции> выбирается и выполняется <истинная ветвь> или <ложная ветвь> в зависимости от истинности <выражения> типа BOOLEAN. Каждая ветвь представляет собой <тело сегмента> и может содержать все необходимые определения, декларации и инструкции без дополнительных скобок. После выполнения выбранной ветви управление передается на инструкцию, следующую за условной.
СОСТАВНЫЕ ИНСТРУКЦИИ
<составная инструкция> ::= <простая составная инструкция> | <метка> <простая составная инструкция>
<простая составная инструкция> ::= <заголовок составной инструкции> <тело составной инструкции> <конец составной инструкции>
<заголовок составной инструкции> ::= BEGIN
<тело составной инструкции> ::= <тело сегмента>
<конец составной инструкции> ::= END; | END <идентификатор>;
Другие возможности, заложенные в синтаксисе Мини, делают <составные инструкции> не особенно необходимыми. Однако <составные инструкции> полезны в сочетании с инструкциями REPEAT и REPENT. В начало составной инструкции можно поместить декларации и определения. Если после END записан <идентификатор>, он должен быть <меткой>, причем <метка> и <идентификатор> обязаны совпадать.
ИНСТРУКЦИИ ЦИКЛА
<инструкция цикла> ::= <простая инструкция цикла> | <метка> <простая инструкция цикла>
<простая инструкция цикла> ::= <заголовок цикла> <тело цикла> <конец цикла>
<заголовок цикла> ::= <для> <цель цикла> <управление> DO
<тело цикла> ::= <тело сегмента>
<конец цикла> ::= END FOR; | END FOR <идентификатор>;
<для> ::= FOR
<цель цикла> ::= <переменная> <заменить на>
<управление> ::= <шаговое управление> | <шаговое управление> <условное управление>
<шаговое управление> ::= <начальное значение> <шаг> | <начальное значение> <предел> | <начальное значение> <шаг> <предел>
<начальное значение> ::= <выражение>
<шаг> ::= BY <выражение>
<предел> ::= ТО <выражение>
<условное управление> ::= WHILE <выражение>
Проще всего объяснить поведение <инструкции цикла>, написав на "метаМини" небольшой фрагмент, заменяющий эту инструкцию. Чтобы найти результат работы <инструкции цикла>, нужно применить к ней "определение", данное на рис.27.1. Подчеркнем, что, согласно этому определению, <цель цикла>, <предел> и <шаг> перевычисляются при каждом повторении. Предикат "существует" позволяет метаМини узнать, присутствуют ли соответствующие необязательные части в конкретной <инструкции цикла>. Если употреблен закрывающий <идентификатор>, он должен совпадать с <обязательно присутствующей><меткой>.

Рисунок 27.1. Определение на метаМини, позволяющее понять действие <инструкции цикла>. Это "определение" влечет за собой обязательное перевычисление <цели цикла>.
В данном определении <инструкции цикла> педагог вновь победил практика. Динамическое переопределение управляющих значений унаследовано из Алгола; большинство других языков отказалось от этого по соображениям эффективности. Однако, если вы сможете реализовать динамическое определение, полученных знаний с избытком хватит на построение более простых статических циклов. Шаговый и условный циклы соединены в одной инструкции, чтобы сделать Мини поменьше; в реальном языке их можно разделить. Соблюдайте осторожность при повторной обработке <цели цикла>; если цель - это формальный параметр или элемент массива, при каждом повторении за целью могут скрываться различные переменные.
Выбор
<инструкция выбора> ::= <простая инструкция выбора> | <метка> <простая инструкция выбора>
<простая инструкция выбора> ::= <заголовок инструкции выбора> <тело инструкции выбора> <конец инструкции выбора>
<заголовок инструкции выбора> ::= SELECT <выражение> OF
<тело инструкции выбора> ::= <список случаев> | <список случаев> <прочие случаи>
<конец инструкции выбора> ::= END SELECT; | END SELECT <идентификатор>;
<список случаев> ::= <случай> | <список случаев> <случай>
<случай> ::= <заголовок случая> <тело случая>
<заголовок случая> ::= CASE <селектор>:
<селектор> ::= <заголовок селектора>)
<заголовок селектора> ::= (<выражение> | <заголовок селектора>, <выражение>
<прочие случаи> ::= <заголовок прочих случаев> <тело случая>
<заголовок прочих случаев> ::= OTHERWISE:
<тело случая> ::= <тело сегмента>
<Инструкция выбора> работает следующим образом.
- Вычисляется <выражение> в <заголовке инструкции выбора>.
- Обрабатываются все <случаи>, от первого до последнего, в <списке случаев>.
- Для каждого <случая>, слева направо, одно за другим вычисляются <выражения> в <селекторе>. Как только <выражение> вычислено, его значение сравнивается со значением первоначального <выражения> из <заголовка инструкции выбора>. Если они равны, выполняется соответствующее <тело случая>; на этом <инструкция выбора> завершает свою работу, и управление передается на следующую <инструкцию>.
- Если ни один из случаев не выбран и если имеются <прочие случаи>, выполняется <тело случая> и <инструкция выбора> завершает работу. Иначе <инструкция выбора> ни на что не влияет, если не считать побочных эффектов от вычисления выражений.
Типы всех выражений, используемых для выбора <случая>, должны быть одинаковы. Если в конце <инструкции выбора> употреблен <идентификатор>, он должен совпадать с (обязательно присутствующей) <меткой> <инструкции выбора>.
ВОЗОБНОВЛЕНИЕ И ВЫХОД
<инструкция возобновления> ::= REPEAT <идентификатор>;
<инструкция выхода> ::= REPENT <идентификатор>;
<Инструкция возобновления> вызывает возврат управления на начало ОБЪЕМЛЮЩЕГО тела инструкции, помеченной <идентификатором>. Выполнение всех промежуточных объемлющих тел сегментов и инструкций, частями которых эти тела являются, завершается, как если бы произошел нормальный выход из них. Вся связанная с ними память разрушается. <Метка>, на которую выполняется переход, должна принадлежать той же процедуре, что и <инструкция возобновления>. Если не существует объемлющей инструкции с указанной меткой, <инструкция возобновления> рассматривается как семантически ошибочная. Семантика <инструкции выхода> аналогична, с той лишь разницей, что управление передается не на начало помеченной инструкции, а в точку, непосредственно следующую за помеченной объемлющей инструкцией. Заметим, что <инструкция возобновления> вызывает повторное выполнение инструкции, на начало которой передается управление.
ВВОД И ВЫВОД
<инструкция ввода> ::= INPUT <список ввода>;
<список ввода> ::= <переменная> | <список ввода>, переменная>
<инструкция вывода> ::== OUTPUT <список вывода>;
<список вывода> ::= <выражение> | <список вывода>, <выражение>
<Инструкция ввода> вызывает передачу элементов данных из входного потока в <переменные> <списка ввода>. Вводимые элементы должны иметь базовый тип, совпадающий с типом соответствующей переменной. Вводимый элемент представляется так же, как константа этого типа. Элементы входного потока необходимо разделять литерами пробела или конца записи.
Аналогично <инструкция вывода> вызывает передачу <выражений> из <списка вывода> в выходной поток. <Выражения> должны иметь базовый тип. Точный формат выходного потока определяется при реализации; требуется лишь, чтобы выводимая информация годилась для последующего ввода. Каждая <инструкция вывода> в конце своей работы выдает литеру конца записи.
ПУСТЫЕ ИНСТРУКЦИИ И МЕТКИ
<пустая инструкция> ::= ;
<метка> ::= <идентификатор>:
<Пустая инструкция> не вызывает никаких действий. <Метка> - это <идентификатор>, который декларируется своим использованием и в данном <теле сегмента> не может декларироваться или определяться иначе, как имя поля.
Выражения <выражение> ::= <выражение один> | <выражение> "|" <выражение один> | <выражение> XOR <выражение один>
<выражение один> ::= <выражение два> | <выражение один> & <выражение два>
<выражение два> ::== <выражение три> | NOT <выражение три>
<выражение три> ::= <выражение четыре> | <выражение три> <отношение> <выражение четыре>
<выражение четыре> ::= <выражение пять> | <выражение четыре> "||" <выражение пять>
<выражение пять> ::= <выражение шесть> | <выражение пять> <аддитивный оператор> <выражение шесть> | <аддитивный оператор> <выражение шесть>
<выражение шесть> ::= <выражение семь> | <выражение шесть> <мультипликативный оператор> <выражение семь>
<выражение семь> ::= FLOOR(<выражение>) | LENGTH(<выражение>) | SUBSTR(<выражение>, <выражение>, <выражение>) | CHARACTER(<выражение>) | NUMBER(<выражение>) | FLOAT(<выражение>) | FIX(<выражение>) | <выражение восемь>
<выражение восемь> ::= <переменная> | <константа> | <вызов функции> | (<выражение>)
Выражения трактуются совершенно стандартным образом. Операнды операторов |, XOR (исключающее или), & и NOT должны иметь тип BOOLEAN. Два произвольных элемента одного типа можно сравнить посредством <отношения> равенства и неравенства. Цепочки литер можно сравнить посредством любого <отношения>. Две цепочки равны тогда и только тогда, когда они в точности одинаковы. Цепочка A меньше цепочки B, если начало A равно началу B и в A больше нет литер или очередная литера A предшествует очередной литере B в алфавитной упорядоченности. Два любых целых или вещественных числа можно сравнивать посредством любого <отношения>; если целое сравнивается с вещественным, оно неявно преобразуется в вещественное. Результат любого сравнения имеет тип BOOLEAN.
Операндами <аддитивных операторов> и <мультипликативных операторов> могут быть только целые и вещественные значения. Если целые операнды сочетаются с вещественными, перед выполнением операции целые преобразуются в вещественные. В операции MOD нельзя использовать вещественные числа; при выполнении операций MOD и деления целых чисел частное выбирается так, чтобы остаток был неотрицательным. Операндами оператора конкатенации || обычно служат цепочки литер; результат также является цепочкой. Операнды других базовых типов перед выполнением конкатенации преобразуются в цепочки, соответствующие их представлению при выводе.
Функция FLOOR преобразует вещественный параметр в вещественное число, равное целому, не превосходящему параметр. Результатом функции LENGTH является целое число, равное длине цепочки-параметра. Первый параметр функции SUBSTR - цепочка; результатом служит подцепочка, начальная литера которой обозначена вторым целочисленным параметром <счет идет от нуля>, а длина задана третьим целочисленным параметром. Функция CHARACTER преобразует целочисленный параметр в цепочку из одной литеры, имеющей в алфавите данный номер. Функция NUMBER выдает в качестве целочисленного результата номер, который имеет в алфавите первая литера цепочки-параметра. Функция FLOAT преобразует целочисленный параметр в вещественный результат, a FIX преобразует вещественный параметр в целочисленный результат. Выполнение функций SUBSTR, FIX и CHARACTER может закончиться ошибкой.
ПЕРЕМЕННЫЕ
<переменная> ::= <идентификатор> | <переменная>. <идентификатор> | <переменная> [<выражение>]
<Переменная> - это либо просто <идентификатор>, либо <переменная> с последующим именем поля, либо <переменная > с индексом. Разумеется, все <переменные> должны быть декларированы. <Идентификатор> - терминальный элемент синтаксиса. Он обязан начинаться с большой или малой буквы, за которой может следовать произвольное число букв или десятичных цифр. Резервированные слова нельзя использовать в качестве <идентификаторов>. Как резервированные слова, так и <идентификаторы> должны отделяться от других неоператорных лексем по крайней мере одним пробелом, комментарием или литерой перевода строки. Лексемы не могут пересекать границ записей.
КОНСТАНТЫ
<константа> ::= <целая константа> | <вещественния константа> | <булева константа> | <цепочечная константа>
<булева константа> ::= TRUE | FALSE
<Целая константа> - это непрерывная цепочка десятичных цифр. Она должна отделяться от других неоператорных лексем по крайней мере одним пробелом, комментарием или литерой перевода строки. <Вещественная константа> - это непрерывная цепочка десятичных цифр, за которой вплотную следует точка и, возможно, еще одна цепочка десятичных цифр. В остальном <вещественные константы> подчиняются тем же правилам, что и <целые константы>. <Цепочечная константа> начинается и кончается двойной кавычкой "; между ними могут стоять любые литеры, кроме двойной кавычки. Чтобы включить в цепочку двойную кавычку, ее следует записать дважды. Например, """" - цепочка ровно из одной двойной кавычки. В остальном <цепочечная константа> ведет себя аналогично <идентификаторам>. В частности, она не может содержать литер перевода строки.
ВЫЗОВЫ ФУНКЦИЙ
<вызов функции> ::= <идентификатор функции>() | <идентификатор функции><список фактических параметров>
<идентификатор функции> ::= <идентификатор>
<Идентификатор функции> - это обычный <идентификатор>, употребленный в некотором определении функции. При вызове функций без параметров следует пользоваться первой альтернативой в <вызове функции>.
ЛЕКСЕМЫ
<отношение> ::= < | > | = | <= | >= | <>
<аддитивный оператор> ::= + | -
<мультипликативный оператор> ::= * | / | MOD
С точки зрения разделения лексем операторами также считаются :, ;, (, ), ",", [, ], &, |, ||, := и не считаются XOR, NOT и MOD. Комментарии начинаются с сочетания литер /*, продолжаются любой цепочкой, не содержащей */, и заканчиваются литерами */. Комментарии могут располагаться везде, где допускаются разделяющие пробелы. Комментарии выполняют роль разделителей.
...
МАЛ ЗОЛОТНИК...
ИЛИ...
КОМПИЛЯТОР ДЛЯ АЛГЕБРАИЧЕСКОГО ЯЗЫКА
Компилятор - это всегда большая программа. Написать его, практически на пустом месте, даже под опекой преподавателей вовсе не просто. И хотя при создании Мини ставилась цель свести все муки к минимуму, во всяком случае в той мере, в какой это позволяло его просветительское назначение, предлагаемая задача все же оказалась самой трудной в книге. Если вы (и ваши верные друзья) не обладаете достаточной энергией и временем, то не стоит за нее и браться.
ЯЗЫК МИНИ
Мини - универсальный, процедурный, алгебраический язык программирования. Он уходит своими корнями в Алгол, Алгол 68 и Паскаль. Подобно этим языкам, Мини предназначен для компиляции, загрузки и выполнения на обычных ЭВМ (хорошим примером такой машины служит УМ-1, см. гл.25). Синтаксис задается контекстно-свободной грамматикой, пригодной для разбора методами LR(1). Семантика аналогична алгольной и паскалевой, и нам кажется достаточным ее неформальное описание. Квалификация читателя позволит ему домыслить все недосказанное [Стиль последующего изложения показывает, сколь высоко оценивает автор квалификацию своих читателей.- Прим. перев.]. Ниже приведены логически связанные части грамматики и их семантика.
ЕДИНИЦЫ КОМПИЛЯЦИИ
<единица компиляции> ::= <программный сегмент> | <единица компиляции> <программный сегмент>
<программный сегмент> ::= <главная программа> | <внешняя процедура>
<Единица компиляции> - это цепочка замкнутых <программных сегментов> [В русском переводе приходится склонять нетерминальные символы грамматики.- Прим. перев.]. Каждый (программный сегмент) есть либо <главная программа>, либо <внешняя процедура>. Все сегменты (единицы компиляции) свяжет друг с другом загрузчик, однако не обязательно, чтобы все сегменты, нужные для полной загрузки, компилировались вместе. При загрузке должна присутствовать ровно одна <главная программа>.
ПРОГРАММЫ
<главная программа> ::= <заголовок программы> <тело программы> <конец программы>
<заголовок программы> ::= PROGRAM <идентификатор>:
<тело программы> ::= <тело сегмента>
<конец программы> ::= END PROGRAM <идентификатор>;
Каждая <главная программа> именована, и закрывающее имя должно совпадать с открывающим. <Тело программы>, подобно большинству других сгруппированных инструкций, есть <тело сегмента> и может содержать все, что обычно свойственно программам. Заметим также, что резервированные слова, идентификаторы и константы не должны разрываться на границах записей. Их следует отделять друг от друга пробелами, знаками операций, комментариями или границами записей.
ВНЕШНИЕ ПРОЦЕДУРЫ
<внешняя процедура> ::= <внешняя подпрограмма> | <внешняя функция>
<внешняя подпрограмма> ::= <заголовок внешней подпрограммы>: <тело внешней подпрограммы> <конец внешней подпрограммы>
<внешняя функция> ::= <заголовок внешней функции>: <тело внешней функции> <конец внешней функции>
<заголовок внешней подпрограммы> ::= EXTERNAL PROCEDURE <имя внешней процедуры>
<заголовок внешней функции> ::= EXTERNAL FUNCTION <имя внешней процедуры> <внешний тип>
<имя внешней процедуры> ::= <идентификатор> | <идентификатор> <список внешних параметров>
<список внешних параметров> ::= <заголовок внешних параметров>)
<заголовок внешних параметров> ::= (<внешний параметр> | <заголовок внешних параметров>, <внешний параметр>
<внешний параметр> ::= <идентификатор> <внешний тип> | <идентификатор> <внешний тип> NAME
<внешний тип> ::= <базовый тип>
<тело внешней подпрограммы> ::= <тело сегмента>
<тело внешней функции> ::= <тело сегмента>
<конец внешней подпрограммы> ::= END EXTERNAL PROCEDURE <идентификатор>;
<конец внешней функции> ::= END EXTERNAL FUNCTION <идентификатор>;
<Внешние процедуры> позволяют компилировать модули раздельно и собирать их вместе во время загрузки. При загрузке допускается лишь одна (внешняя процедура> с данным именем. <Внешние параметры> и возвращаемые <внешними функциями> значения должны иметь <базовый тип>. <Внешние параметры> передаются по значению, если они не помечены резервированным словом NAME; при наличии этого слова параметры передаются по имени. Перед <концом внешней подпрограммы> неявно располагается <инструкция возврата>, однако <внешние функции> должны завершать работу явной <инструкцией возврата> с возвращаемым значением; попытка выхода из <внешней функции> через <конец внешней функции> является семантической ошибкой, которую иногда можно обнаружить при компиляции. Единственной связью между переменными <внешней процедуры> и переменными вызывающей процедуры служит механизм передачи параметров. Однако во время сборки сегментов (например, с помощью загрузчика, подобного описанному в гл.26) будет проверено совпадение типов формальных и фактических параметров, функций и возвращаемых значений.
Из описания <внешних процедур> усматривается несколько важных различий между Мини и современными языками. В коммерческом языке целесообразно обеспечивать средства для разделения деклараций всех видов между <программными сегментами>. На наш взгляд, усложнения, вносимые в язык такой возможностью, слишком велики по сравнению с педагогическим эффектом от их реализации: это же справедливо по отношению к расширению диапазона возможных типов параметров <внешних процедур>. С другой стороны, коммерческие языки в своем большинстве не допускают передачу параметров по имени (из соображений эффективности), в то время как студента, овладевшего механизмом передачи по имени, не смутить уже, кажется, ничем. Мини многословнее аналогичных языков, поскольку современные исследования показали важность умело распределенной избыточности для исправления синтаксических ошибок. Кроме того, программист, пишущий на Мини, должен явно различать декларации подпрограмм и функций. Хотя компилятор и может самостоятельно выявить различие, язык заставляет программиста явно демонстрировать свои намерения [Одной из главных трудностей при доказательстве правильности программ является выделение смысла программы из написанных программистом императивов. Поскольку правильность зависит отображений желаемого в действительное, ценно все, что помогает вскрыть намерения. Вводимое в Мини разграничение функций и подпрограмм - шажок в этом направлении. Заметим также, что хороший программист никогда не использует процедуру и как функцию, и как подпрограмму, ну а Мини просто придает этому правилу силу закона]. Наконец, Мини позволяет полностью проверить совпадение типов во время компиляции и загрузки, следуя неписаному закону: во время выполнения нужно делать как можно меньше.
СЕГМЕНТЫ
<тело сегмента> ::= <раздел определения типов>
<раздел декларации переменных> <раздел определения процедур> <раздел выполняемых инструкций>
<раздел определения типов> ::= | <раздел определения типов> <определение типа>
<раздел декларации переменных> ::= | <раздел декларации переменных> <декларация переменных>
<раздел определения процедур> ::= | <раздел определения процедур> <определение процедуры>
<раздел выполняемых инструкций> ::= <выполняемая инструкция> | <раздел выполняемых инструкций> <выполняемая инструкция>
<Тело сегмента> состоит не менее чем из одной <выполняемой инструкции>, которой, возможно, предшествуют <определения типов>, <декларации переменных> и <определения процедур>. Область действия любого имени - вся оставшаяся часть тела данного сегмента; это имя можно использовать в следующих определениях и декларациях. Одно и то же имя нельзя декларировать или определять дважды в <теле сегмента>. Как и в Алголе, имя можно переопределить или передекларировать во внутреннем <теле сегмента>.
ТИПЫ
<определение типа> ::= TYPE <идентификатор> IS <тип>
<тип> ::== <базовый тип> | <массивный тип> | <структурный тип> | <идентификатор типа>
<базовый тип> ::= INTEGER | REAL | BOOLEAN | STRING
<массивный тип> ::= ARRAY <границы> OF <тип>
<границы> ::= [<граничное выражение>] | [<граничное выражение>: <граничное выражение>]
<граничное выражение> ::= <выражение>
<структурный тип> ::= STRUCTURE <список полей> END STRUCTURE
<список полей> ::= <поле> | <список полей>, <поле>
<поле> ::== FIELD <идентификатор> IS <тип>
<идентификатор типа> ::= <идентификатор>
<Определение типа> вводит для <типа> сокращение-<идентификатор>. В дальнейшем это сокращение можно использовать везде, где мог бы стоять <тип>. В набор типов входят встроенные <базовые типы>, однородные <массивные типы>, разнородные <структурные типы> и сокращения - <идентификаторы типов>. <Базовые типы> INTEGER и REAL могут отображаться на соответствующие аппаратные типы и подчиняться обычным правилам. <Базовый тип> BOOLEAN состоит всего из двух констант TRUE и FALSE. Элементами типа STRING являются цепочки литер произвольной длины, ("степень произвола" может зависеть от реализации), но не менее нескольких тысяч.
Массивы имеют одно измерение, однако их компоненты могут иметь произвольный тип, так что допускается декларация массива массивов... Если нижняя граница массива не задана явно, она полагается равной единице. <Граничные выражения> могут быть сколь угодно сложными, лишь бы их значение сводилось к типу INTEGER. В эти выражения могут входить только переменные, декларированные в объемлющих <телах сегментов> (но не в текущем <теле сегмента>) или в списке параметров объемлющей процедуры. Верхняя граница должна быть не меньше нижней. Там, где возможно, компилятор должен проверять это условие, однако в общем случае требуется проверка во время выполнения. Разные вхождения одинаковых <массивных типов> не рассматриваются компилятором как один и тот же <тип> при проверках совпадения типов. Чтобы допустить неоднократное использование, <массивный тип> нужно обозначить <идентификатором типа>.
<Структурный тип> аналогичен записям в Паскале. <Идентификаторы> полей используются для именования элементов с <типами> полей. Поскольку определение рекурсивно, структуры могут иметь подструктуры. Конкретный <идентификатор> может именовать только одно <поле> <структурного типа>, однако допускается его использование и как имени переменной, и как имени поля другого (даже вложенного) <структурного типа>.
ДЕКЛАРАЦИИ
<декларация переменных> ::= DECLARE <декларируемые имена> <тип>;
<декларируемые имена> ::== <идентификатор> | <список декларируемых имен>)
<список декларируемых имен> ::= (<идентификатор> | <список декларируемых имен>, <идентификатор>
<Декларация переменных> наделяет <типом> <идентификаторы>, употребленные среди <декларируемых имен>. <Идентификаторы> не получают начальных значений. Имя (кроме имени поля) в <теле сегмента> может определяться или декларироваться не более одного раза.
ВНУТРЕННИЕ ПРОЦЕДУРЫ
<определение процедуры> ::= <определение подпрограммы> | <определение функции> | <определение внешней подпрограммы> | <определение внешней функции>
<определение подпрограммы> ::= <заголовок подпрограммы>: <тело подпрограммы> <конец подпрограммы>
<определение функции> ::= <заголовок функции>: <тело функции> <конец функции>
<определение внешней подпрограммы> ::= <заголовок внешней подпрограммы>;
<определение внешней функции> ::= <заголовок внешней функции>;
<заголовок подпрограммы> ::= PROCEDURE <имя процедуры>
<заголовок функции> ::= FUNCTION <имя процедуры><тип>
<тело подпрограммы> ::= <тело сегмента>
<тело функции> ::= <тело сегмента>
<конец подпрограммы> ::= END PROCEDURE <идентификатор>;
<конец функции> ::= END FUNCTION <идентификатор>;
<имя процедуры> ::= <идентификатор> | <идентификатор> <список внутренних параметров>
<список внутренних параметров> ::= <заголовок внутренних параметров>)
<заголовок внутренних параметров> ::= (<внутренний параметр | <заголовок внутренних параметров>, <внутренний параметр>
<внутренний параметр> ::= <идентификатор> <тип> | <идентификатор> <тип> NAME
Непосредственно в <теле сегмента> можно определить лишь одну процедуру с данным именем. Определение <внешней подпрограммы> или <внешней функции> дается только заголовком, поскольку тело <внешней процедуры> доставит та же или другая <единица компиляции>. В локальном и окончательном определении процедуры должны совпадать имя процедуры, порядок, тип и способ передачи формальных параметров; это соответствие проверит загрузчик. Напомним, что параметры <внешней процедуры> должны иметь <базовый тип>.
Определение локальных процедур дается аналогично. <Внутренние параметры>, так же как и возвращаемые функциями значения, могут иметь любой <тип>. Перед <концом подпрограммы> располагается неявная <инструкция возврата>. Выход из функции должен осуществляться посредством явной <инструкции возврата>, снабженной значением. Параметры с пометкой NAME передаются по имени, остальные - по значению. Сами по себе процедуры напоминают алгольные. Рекурсия допускается в полном объеме. <Имя процедуры> нельзя использовать до его декларации.
ВЫПОЛНЯЕМЫЕ ИНСТРУКЦИИ
<выполняемая инструкция> ::= <инструкция присваивания> | <инструкция вызова> | <инструкция возврата> | <инструкция завершения> | <условная инструкция> | <составная инструкция> | <инструкция цикла> | <инструкция выбора> | <инструкция возобновления> | <инструкция выхода>| <инструкция ввода> | <инструкция вывода> | <пустая инструкция>
Поскольку используются принятые в Алголе 68 условные инструкции и инструкции цикла, нет нужды разбивать их на несколько отдельных синтаксических классов. Все инструкции должны завершаться точкой с запятой.
ПРИСВАИВАНИЯ
<инструкция присваивания> ::= SET <список целей> <выражение>;
<список целей> ::= <цель> | <список целей> <цель>
<цель> ::= <переменная> <заменить на>
<заменить на> ::= :=
В <инструкции присваивания> <тип> всех <целей> и <тип> присваиваемого <выражения> должен быть одним и тем же. <Цели> обрабатываются слева направо, чтобы определить адреса в памяти, и только затем вычисляется выражение, чтобы найти запоминаемое значение. Структуры и массивы можно присваивать в случае совпадения <типов>. Использование ключевого слова SET служит примером многословности Мини. Данная избыточность помогает исправлению, когда неправильно записано другое ключевое слово (распространенная ошибка).
ВЫЗОВЫ ПРОЦЕДУР
<инструкция вызова> ::= CALL <обращение к процедуре>;
<обращение к процедуре> ::= <идентификатор процедуры> | <идентификатор процедуры> <список фактических параметров>
<идентификатор процедуры> ::= <идентификатор>
<список фактических параметров> ::= <заголовок фактических параметров>)
<заголовок фактических параметров> ::= (<выражение> | <заголовок фактических параметров>, <выражение>
Можно вызывать только процедуры, получившие определения а областью действия, содержащей <инструкцию вызова>. Количество, порядок и типы фактических и формальных параметров должны совпадать. После того как в вызываемой процедуре выполнится <инструкция возврата>, управление будет передано на следующую за вызовом инструкцию. Ключевое слово CALL используется по тем же соображениям, что и SET в <инструкции присваивания>.
ВОЗВРАТЫ
<инструкция возврата> ::= RETURN; | RETURN <выражение>;
<Инструкция возврата> может употребляться только в процедуре. Она возвращает управление в вызывающую инструкцию, В конце подпрограммы имеется неявная <инструкция возврата>. При возврате из подпрограммы значение указывать нельзя. При возврате из функции значение указывать обязательно. Оно должно иметь тот же тип, что и функция.
ИНСТРУКЦИИ ЗАВЕРШЕНИЯ
<инструкция завершения> ::= EXIT;
Данная инструкция вызывает нормальное завершение всей программы и возврат в супервизор. Она должна быть последней выполненной <не обязательно последней написанной> инструкцией <программы>.
УСЛОВНЫЕ ИНСТРУКЦИИ
<условная инструкция> ::= <простая условная инструкция> | <метка> <простая условная инструкция>
<простая условная инструкция> ::= <спецификация условия> <истинная ветвь> FI; | <спецификация условия> <истинная ветвь> <ложная ветвь> FI;
<спецификация условия> ::= IF <выражение>
<истинная ветвь> ::= THEN <тело условной инструкции>
<ложная ветвь> ::= <иначе> <тело условной инструкции>
<иначе> ::= ELSE
<тело условной инструкции> ::= <тело сегмента>
В <условной инструкции> выбирается и выполняется <истинная ветвь> или <ложная ветвь> в зависимости от истинности <выражения> типа BOOLEAN. Каждая ветвь представляет собой <тело сегмента> и может содержать все необходимые определения, декларации и инструкции без дополнительных скобок. После выполнения выбранной ветви управление передается на инструкцию, следующую за условной.
СОСТАВНЫЕ ИНСТРУКЦИИ
<составная инструкция> ::= <простая составная инструкция> | <метка> <простая составная инструкция>
<простая составная инструкция> ::= <заголовок составной инструкции> <тело составной инструкции> <конец составной инструкции>
<заголовок составной инструкции> ::= BEGIN
<тело составной инструкции> ::= <тело сегмента>
<конец составной инструкции> ::= END; | END <идентификатор>;
Другие возможности, заложенные в синтаксисе Мини, делают <составные инструкции> не особенно необходимыми. Однако <составные инструкции> полезны в сочетании с инструкциями REPEAT и REPENT. В начало составной инструкции можно поместить декларации и определения. Если после END записан <идентификатор>, он должен быть <меткой>, причем <метка> и <идентификатор> обязаны совпадать.
ИНСТРУКЦИИ ЦИКЛА
<инструкция цикла> ::= <простая инструкция цикла> | <метка> <простая инструкция цикла>
<простая инструкция цикла> ::= <заголовок цикла> <тело цикла> <конец цикла>
<заголовок цикла> ::= <для> <цель цикла> <управление> DO
<тело цикла> ::= <тело сегмента>
<конец цикла> ::= END FOR; | END FOR <идентификатор>;
<для> ::= FOR
<цель цикла> ::= <переменная> <заменить на>
<управление> ::= <шаговое управление> | <шаговое управление> <условное управление>
<шаговое управление> ::= <начальное значение> <шаг> | <начальное значение> <предел> | <начальное значение> <шаг> <предел>
<начальное значение> ::= <выражение>
<шаг> ::= BY <выражение>
<предел> ::= ТО <выражение>
<условное управление> ::= WHILE <выражение>
Проще всего объяснить поведение <инструкции цикла>, написав на "метаМини" небольшой фрагмент, заменяющий эту инструкцию. Чтобы найти результат работы <инструкции цикла>, нужно применить к ней "определение", данное на рис.27.1. Подчеркнем, что, согласно этому определению, <цель цикла>, <предел> и <шаг> перевычисляются при каждом повторении. Предикат "существует" позволяет метаМини узнать, присутствуют ли соответствующие необязательные части в конкретной <инструкции цикла>. Если употреблен закрывающий <идентификатор>, он должен совпадать с <обязательно присутствующей><меткой>.

Рисунок 27.1. Определение на метаМини, позволяющее понять действие <инструкции цикла>. Это "определение" влечет за собой обязательное перевычисление <цели цикла>.
В данном определении <инструкции цикла> педагог вновь победил практика. Динамическое переопределение управляющих значений унаследовано из Алгола; большинство других языков отказалось от этого по соображениям эффективности. Однако, если вы сможете реализовать динамическое определение, полученных знаний с избытком хватит на построение более простых статических циклов. Шаговый и условный циклы соединены в одной инструкции, чтобы сделать Мини поменьше; в реальном языке их можно разделить. Соблюдайте осторожность при повторной обработке <цели цикла>; если цель - это формальный параметр или элемент массива, при каждом повторении за целью могут скрываться различные переменные.
Выбор
<инструкция выбора> ::= <простая инструкция выбора> | <метка> <простая инструкция выбора>
<простая инструкция выбора> ::= <заголовок инструкции выбора> <тело инструкции выбора> <конец инструкции выбора>
<заголовок инструкции выбора> ::= SELECT <выражение> OF
<тело инструкции выбора> ::= <список случаев> | <список случаев> <прочие случаи>
<конец инструкции выбора> ::= END SELECT; | END SELECT <идентификатор>;
<список случаев> ::= <случай> | <список случаев> <случай>
<случай> ::= <заголовок случая> <тело случая>
<заголовок случая> ::= CASE <селектор>:
<селектор> ::= <заголовок селектора>)
<заголовок селектора> ::= (<выражение> | <заголовок селектора>, <выражение>
<прочие случаи> ::= <заголовок прочих случаев> <тело случая>
<заголовок прочих случаев> ::= OTHERWISE:
<тело случая> ::= <тело сегмента>
<Инструкция выбора> работает следующим образом.
- Вычисляется <выражение> в <заголовке инструкции выбора>.
- Обрабатываются все <случаи>, от первого до последнего, в <списке случаев>.
- Для каждого <случая>, слева направо, одно за другим вычисляются <выражения> в <селекторе>. Как только <выражение> вычислено, его значение сравнивается со значением первоначального <выражения> из <заголовка инструкции выбора>. Если они равны, выполняется соответствующее <тело случая>; на этом <инструкция выбора> завершает свою работу, и управление передается на следующую <инструкцию>.
- Если ни один из случаев не выбран и если имеются <прочие случаи>, выполняется <тело случая> и <инструкция выбора> завершает работу. Иначе <инструкция выбора> ни на что не влияет, если не считать побочных эффектов от вычисления выражений.
Типы всех выражений, используемых для выбора <случая>, должны быть одинаковы. Если в конце <инструкции выбора> употреблен <идентификатор>, он должен совпадать с (обязательно присутствующей) <меткой> <инструкции выбора>.
ВОЗОБНОВЛЕНИЕ И ВЫХОД
<инструкция возобновления> ::= REPEAT <идентификатор>;
<инструкция выхода> ::= REPENT <идентификатор>;
<Инструкция возобновления> вызывает возврат управления на начало ОБЪЕМЛЮЩЕГО тела инструкции, помеченной <идентификатором>. Выполнение всех промежуточных объемлющих тел сегментов и инструкций, частями которых эти тела являются, завершается, как если бы произошел нормальный выход из них. Вся связанная с ними память разрушается. <Метка>, на которую выполняется переход, должна принадлежать той же процедуре, что и <инструкция возобновления>. Если не существует объемлющей инструкции с указанной меткой, <инструкция возобновления> рассматривается как семантически ошибочная. Семантика <инструкции выхода> аналогична, с той лишь разницей, что управление передается не на начало помеченной инструкции, а в точку, непосредственно следующую за помеченной объемлющей инструкцией. Заметим, что <инструкция возобновления> вызывает повторное выполнение инструкции, на начало которой передается управление.
ВВОД И ВЫВОД
<инструкция ввода> ::= INPUT <список ввода>;
<список ввода> ::= <переменная> | <список ввода>, переменная>
<инструкция вывода> ::== OUTPUT <список вывода>;
<список вывода> ::= <выражение> | <список вывода>, <выражение>
<Инструкция ввода> вызывает передачу элементов данных из входного потока в <переменные> <списка ввода>. Вводимые элементы должны иметь базовый тип, совпадающий с типом соответствующей переменной. Вводимый элемент представляется так же, как константа этого типа. Элементы входного потока необходимо разделять литерами пробела или конца записи.
Аналогично <инструкция вывода> вызывает передачу <выражений> из <списка вывода> в выходной поток. <Выражения> должны иметь базовый тип. Точный формат выходного потока определяется при реализации; требуется лишь, чтобы выводимая информация годилась для последующего ввода. Каждая <инструкция вывода> в конце своей работы выдает литеру конца записи.
ПУСТЫЕ ИНСТРУКЦИИ И МЕТКИ
<пустая инструкция> ::= ;
<метка> ::= <идентификатор>:
<Пустая инструкция> не вызывает никаких действий. <Метка> - это <идентификатор>, который декларируется своим использованием и в данном <теле сегмента> не может декларироваться или определяться иначе, как имя поля.
Выражения <выражение> ::= <выражение один> | <выражение> "|" <выражение один> | <выражение> XOR <выражение один>
<выражение один> ::= <выражение два> | <выражение один> & <выражение два>
<выражение два> ::== <выражение три> | NOT <выражение три>
<выражение три> ::= <выражение четыре> | <выражение три> <отношение> <выражение четыре>
<выражение четыре> ::= <выражение пять> | <выражение четыре> "||" <выражение пять>
<выражение пять> ::= <выражение шесть> | <выражение пять> <аддитивный оператор> <выражение шесть> | <аддитивный оператор> <выражение шесть>
<выражение шесть> ::= <выражение семь> | <выражение шесть> <мультипликативный оператор> <выражение семь>
<выражение семь> ::= FLOOR(<выражение>) | LENGTH(<выражение>) | SUBSTR(<выражение>, <выражение>, <выражение>) | CHARACTER(<выражение>) | NUMBER(<выражение>) | FLOAT(<выражение>) | FIX(<выражение>) | <выражение восемь>
<выражение восемь> ::= <переменная> | <константа> | <вызов функции> | (<выражение>)
Выражения трактуются совершенно стандартным образом. Операнды операторов |, XOR (исключающее или), & и NOT должны иметь тип BOOLEAN. Два произвольных элемента одного типа можно сравнить посредством <отношения> равенства и неравенства. Цепочки литер можно сравнить посредством любого <отношения>. Две цепочки равны тогда и только тогда, когда они в точности одинаковы. Цепочка A меньше цепочки B, если начало A равно началу B и в A больше нет литер или очередная литера A предшествует очередной литере B в алфавитной упорядоченности. Два любых целых или вещественных числа можно сравнивать посредством любого <отношения>; если целое сравнивается с вещественным, оно неявно преобразуется в вещественное. Результат любого сравнения имеет тип BOOLEAN.
Операндами <аддитивных операторов> и <мультипликативных операторов> могут быть только целые и вещественные значения. Если целые операнды сочетаются с вещественными, перед выполнением операции целые преобразуются в вещественные. В операции MOD нельзя использовать вещественные числа; при выполнении операций MOD и деления целых чисел частное выбирается так, чтобы остаток был неотрицательным. Операндами оператора конкатенации || обычно служат цепочки литер; результат также является цепочкой. Операнды других базовых типов перед выполнением конкатенации преобразуются в цепочки, соответствующие их представлению при выводе.
Функция FLOOR преобразует вещественный параметр в вещественное число, равное целому, не превосходящему параметр. Результатом функции LENGTH является целое число, равное длине цепочки-параметра. Первый параметр функции SUBSTR - цепочка; результатом служит подцепочка, начальная литера которой обозначена вторым целочисленным параметром <счет идет от нуля>, а длина задана третьим целочисленным параметром. Функция CHARACTER преобразует целочисленный параметр в цепочку из одной литеры, имеющей в алфавите данный номер. Функция NUMBER выдает в качестве целочисленного результата номер, который имеет в алфавите первая литера цепочки-параметра. Функция FLOAT преобразует целочисленный параметр в вещественный результат, a FIX преобразует вещественный параметр в целочисленный результат. Выполнение функций SUBSTR, FIX и CHARACTER может закончиться ошибкой.
ПЕРЕМЕННЫЕ
<переменная> ::= <идентификатор> | <переменная>. <идентификатор> | <переменная> [<выражение>]
<Переменная> - это либо просто <идентификатор>, либо <переменная> с последующим именем поля, либо <переменная > с индексом. Разумеется, все <переменные> должны быть декларированы. <Идентификатор> - терминальный элемент синтаксиса. Он обязан начинаться с большой или малой буквы, за которой может следовать произвольное число букв или десятичных цифр. Резервированные слова нельзя использовать в качестве <идентификаторов>. Как резервированные слова, так и <идентификаторы> должны отделяться от других неоператорных лексем по крайней мере одним пробелом, комментарием или литерой перевода строки. Лексемы не могут пересекать границ записей.
КОНСТАНТЫ
<константа> ::= <целая константа> | <вещественния константа> | <булева константа> | <цепочечная константа>
<булева константа> ::= TRUE | FALSE
<Целая константа> - это непрерывная цепочка десятичных цифр. Она должна отделяться от других неоператорных лексем по крайней мере одним пробелом, комментарием или литерой перевода строки. <Вещественная константа> - это непрерывная цепочка десятичных цифр, за которой вплотную следует точка и, возможно, еще одна цепочка десятичных цифр. В остальном <вещественные константы> подчиняются тем же правилам, что и <целые константы>. <Цепочечная константа> начинается и кончается двойной кавычкой "; между ними могут стоять любые литеры, кроме двойной кавычки. Чтобы включить в цепочку двойную кавычку, ее следует записать дважды. Например, """" - цепочка ровно из одной двойной кавычки. В остальном <цепочечная константа> ведет себя аналогично <идентификаторам>. В частности, она не может содержать литер перевода строки.
ВЫЗОВЫ ФУНКЦИЙ
<вызов функции> ::= <идентификатор функции>() | <идентификатор функции><список фактических параметров>
<идентификатор функции> ::= <идентификатор>
<Идентификатор функции> - это обычный <идентификатор>, употребленный в некотором определении функции. При вызове функций без параметров следует пользоваться первой альтернативой в <вызове функции>.
ЛЕКСЕМЫ
<отношение> ::= < | > | = | <= | >= | <>
<аддитивный оператор> ::= + | -
<мультипликативный оператор> ::= * | / | MOD
С точки зрения разделения лексем операторами также считаются :, ;, (, ), ",", [, ], &, |, ||, := и не считаются XOR, NOT и MOD. Комментарии начинаются с сочетания литер /*, продолжаются любой цепочкой, не содержащей */, и заканчиваются литерами */. Комментарии могут располагаться везде, где допускаются разделяющие пробелы. Комментарии выполняют роль разделителей.
...
Gudleifr- Admin
- Сообщения : 3252
Дата регистрации : 2017-03-29
Re: Уэзерелл. Этюды для программистов. 1982
автор Gudleifr Вт Мар 02, 2021 12:34 pm
...
ПРИМЕР ПРОГРАММЫ
Приводимая ниже программа иллюстрирует некоторые черты языка Мини. Чрезвычайно трудно в нескольких строках воспользоваться всеми возможностями, однако программа Эратосфен позволяет ощутить дух Мини. Ее можно использовать и как тест для компиляторов, поскольку выводимая информация очевидна, а вычисления нетривиальны. Пожалуй, единственным трюком (заимствованным из Алгола) является использование управляющих значений цикла для проведения вычислений в функции integersqrt. Вот текст программы [Возможно, читателя заинтересуют следующие вопросы:
1. При какой точности выполнения операций с плавающей точкой можно гарантировать конечность первого цикла в функции integersqrt?
2. Не может ли получиться так, что после завершения этого цикла будет выполнено неравенство x >= Корень из a + 2?
3. Нельзя ли избавиться от второго цикла в функции integersqrt, выполнив все операции первого в целочисленной арифметике? Как следует выбрать начальное приближение и условие завершения цикла?
4. Действительно ли нужно прибавлять 1 при вычислении значения limit?
5. Можно ли в заголовке цикла маркировки составных чисел заменить 2*i на i*i?- Прим. перев.].


ОПЕРАЦИОННАЯ СРЕДА
Для выполнения написанных на Мини программ требуется довольно развитая поддерживающая система. Рекурсивные процедуры требуют наличия активационного стека. Для работы с цепочками нужна КУЧА. Ввод/вывод нуждается в связи с супервизором. Вероятно, в крупных реализациях можно воспользоваться поддержкой БИБЛИОТЕЧНЫХ ПРОГРАММ, однако они делают больше того, что нужно для наших целей. Предпочтительнее обеспечить обслуживание посредством супервизорных вызовов управляющей программы, которую можно написать на вашем любимом языке.
ТЕМА. Напишите компилятор с Мини, порождающий перемещаемый объектный код для ЭВМ УМ-1 или другой вычислительной машины (см. гл.25). Проверьте ваш компилятор, написав на Мини несколько программ, скомпилировав их, загрузив с помощью загрузчика УМ (см. гл.26) и выполнив на ЭВМ УМ-1. Удостоверьтесь, что компилятор допускает все синтаксически и лексически правильные программы и отбраковывает все неправильные (семантические ошибки могут прервать компиляцию программы, правильной в других отношениях). При обработке ошибок не требуется исправлять ошибки или продолжать компиляцию, но необходимо точно указать причину и место ошибки. Листинг можно печатать без всяких хитростей - вам хватит других забот. Тщательно документируйте ход выполнения работы и встретившиеся трудности.
УКАЗАНИЯ ИСПОЛНИТЕЛЮ. Перед вами самый крупный проект книги. Его полное осуществление потребует от вас мобилизации всех ресурсов. Обычно проекты подбирались так, что для их решения писалась, начиная с нуля, законченная программа. В данном случае постарайтесь использовать все доступные инструменты конструирования компиляторов. В частности, сейчас широко распространены программы синтаксического анализа, управляемые описанием грамматики. Они помогут вам сэкономить много времени. Программировать следует на языке высокого уровня (помните, что за эффективностью мы не гонимся). Язык с встроенными операциями над цепочками значительно ускорит разработку компилятора.
Конкретные методы конструирования компиляторов описаны в книгах, перечисленных в списке литературы. Не будем повторяться, а предложим лишь порядок реализации методов: сначала лексический анализатор, затем синтаксический анализатор и наконец семантический синтезатор и генератор кода. Подобный подход позволит проводить тестирование по мере продвижения вперед, а не уповать на то, что, когда все будет сделано, оно сразу заработает правильно.
Вполне вероятно, что проект останется незавершенным. Поэтому целесообразно наметить очередность реализации различных возможностей языка. Если порядок выбран правильно, конечный продукт станет подмножеством Мини. Начните с реализации отдельных <программных сегментов>. Внутри них попытайтесь реализовать <выражения>, основные типы инструкций, внутренние процедуры, декларации переменных с <базовыми типами>. Пожалуй, труднее всего сгенерировать код для <инструкции цикла>; оставьте это напоследок. На начальной стадии вам придется написать подпрограммы для вывода перемещаемого объектного кода; постарайтесь, чтобы ими было легко воспользоваться в дальнейшем.
Несомненно, в операционную среду Мини войдет стековая дисциплина выделения памяти для процедур. Когда остальные инструкции достаточно обкатаются, принимайтесь за структурные типы данных. Размещение цепочек во время выполнения требует кучи, которая, вероятно, будет разделять память со стеком. Указанные механизмы выделения памяти вызовут изменения в супервизоре УМ-1. Ранние версии не должны включать сбор мусора для утилизации освободившихся частей. Параллельно с распределением памяти можно работать над компиляцией раздельных сегментов. Не забудьте с самого начала вставить в объектные модули код для отладки.
ИНСТРУМЕНТОВКА. Пишите компилятор на каком-либо процедурном языке высокого уровня. Язык XPL как раз и предназначен для конструирования компиляторов. Сноболом пользоваться не следует, поскольку на этом языке компиляторы реализуются слишком легко и вы не получите необходимой подготовки.
ДЛИТЕЛЬНОСТЬ ИСПОЛНЕНИЯ. Двоим, троим или четверым на 10 недель. Каждый участник независимо отвечает за одну тестовую программу на Мини.
ЛИТЕРАТУРА
Грис (Gries D.). Compiler Construction for Digital Computers. Wiley, New York, NY, 1971. [Имеется перевод: Грис Д. Конструирование компиляторов для цифровых вычислительных машин.- М.: Мир, 1975.] Выдающаяся книга по реализации компиляторов. В ней написано все о простых компиляторах и даны указания по сложным. Правда, остались недостаточно освещенными таблично-управляемые методы разбора LR(k), но этот пробел с избытком покрывают другие упоминаемые здесь книги. Если вы уже выбрали язык для компиляции, Грис покажет, как ее провести.
Мак-Киман, Хорнинг, Уортмен (McKeeman W.M., Horning J.J., Wortman D.В.), A Compiler Generator. Printice-Hall, Englewood Cliffs, NJ, 1970.
В книге описывается язык XPL и его использование для конструирования компиляторов, В качестве иллюстрации метода приведен компилятор с XPL, написанный на XPL. В первых изданиях использовался ныне устаревший таблично-управляемый метод разбора SMSP, однако в следующих изданиях подробно обсуждается разбор LR(k). К сожалению, опубликованный листинг не претерпел изменений в сторону LR(k). He вошел и табличный генератор Де Ремера SLR(k). Книга может служить руководством по XPL.
Николс (Nikholls J.E.). Тhe Structure and Design of Programming Languages. Addison-Wesley, Reading, MA, 1975.
Пратт (Pratt T.W.) Programming Languages Design and Implementatioia. Prentice Hall, Englewood Cliffs, NJ, 1975. [Имеется перевод: Пратт Т. Языки программирования: разработка и реализация.- М.: Мир, 1979]
Обе книги нужно читать до проектирования языка и реализации компилятора. В них внимание сконцентрировано не на конкретных методах компиляции, а на изучении влияния языковых структур на программиста, поддерживаемую систему, конечного пользователя и разработчика компилятора. Авторы тщательно взвешивают все "за" и "против" различных решений при создании языка программирования.
* Ахо А., Ульман Дж. Теория синтаксического анализа, перевода и компиляции. Т.1, 2.- Пер. с англ.- М.: Мир, 1978.
ПРИМЕР ПРОГРАММЫ
Приводимая ниже программа иллюстрирует некоторые черты языка Мини. Чрезвычайно трудно в нескольких строках воспользоваться всеми возможностями, однако программа Эратосфен позволяет ощутить дух Мини. Ее можно использовать и как тест для компиляторов, поскольку выводимая информация очевидна, а вычисления нетривиальны. Пожалуй, единственным трюком (заимствованным из Алгола) является использование управляющих значений цикла для проведения вычислений в функции integersqrt. Вот текст программы [Возможно, читателя заинтересуют следующие вопросы:
1. При какой точности выполнения операций с плавающей точкой можно гарантировать конечность первого цикла в функции integersqrt?
2. Не может ли получиться так, что после завершения этого цикла будет выполнено неравенство x >= Корень из a + 2?
3. Нельзя ли избавиться от второго цикла в функции integersqrt, выполнив все операции первого в целочисленной арифметике? Как следует выбрать начальное приближение и условие завершения цикла?
4. Действительно ли нужно прибавлять 1 при вычислении значения limit?
5. Можно ли в заголовке цикла маркировки составных чисел заменить 2*i на i*i?- Прим. перев.].


ОПЕРАЦИОННАЯ СРЕДА
Для выполнения написанных на Мини программ требуется довольно развитая поддерживающая система. Рекурсивные процедуры требуют наличия активационного стека. Для работы с цепочками нужна КУЧА. Ввод/вывод нуждается в связи с супервизором. Вероятно, в крупных реализациях можно воспользоваться поддержкой БИБЛИОТЕЧНЫХ ПРОГРАММ, однако они делают больше того, что нужно для наших целей. Предпочтительнее обеспечить обслуживание посредством супервизорных вызовов управляющей программы, которую можно написать на вашем любимом языке.
ТЕМА. Напишите компилятор с Мини, порождающий перемещаемый объектный код для ЭВМ УМ-1 или другой вычислительной машины (см. гл.25). Проверьте ваш компилятор, написав на Мини несколько программ, скомпилировав их, загрузив с помощью загрузчика УМ (см. гл.26) и выполнив на ЭВМ УМ-1. Удостоверьтесь, что компилятор допускает все синтаксически и лексически правильные программы и отбраковывает все неправильные (семантические ошибки могут прервать компиляцию программы, правильной в других отношениях). При обработке ошибок не требуется исправлять ошибки или продолжать компиляцию, но необходимо точно указать причину и место ошибки. Листинг можно печатать без всяких хитростей - вам хватит других забот. Тщательно документируйте ход выполнения работы и встретившиеся трудности.
УКАЗАНИЯ ИСПОЛНИТЕЛЮ. Перед вами самый крупный проект книги. Его полное осуществление потребует от вас мобилизации всех ресурсов. Обычно проекты подбирались так, что для их решения писалась, начиная с нуля, законченная программа. В данном случае постарайтесь использовать все доступные инструменты конструирования компиляторов. В частности, сейчас широко распространены программы синтаксического анализа, управляемые описанием грамматики. Они помогут вам сэкономить много времени. Программировать следует на языке высокого уровня (помните, что за эффективностью мы не гонимся). Язык с встроенными операциями над цепочками значительно ускорит разработку компилятора.
Конкретные методы конструирования компиляторов описаны в книгах, перечисленных в списке литературы. Не будем повторяться, а предложим лишь порядок реализации методов: сначала лексический анализатор, затем синтаксический анализатор и наконец семантический синтезатор и генератор кода. Подобный подход позволит проводить тестирование по мере продвижения вперед, а не уповать на то, что, когда все будет сделано, оно сразу заработает правильно.
Вполне вероятно, что проект останется незавершенным. Поэтому целесообразно наметить очередность реализации различных возможностей языка. Если порядок выбран правильно, конечный продукт станет подмножеством Мини. Начните с реализации отдельных <программных сегментов>. Внутри них попытайтесь реализовать <выражения>, основные типы инструкций, внутренние процедуры, декларации переменных с <базовыми типами>. Пожалуй, труднее всего сгенерировать код для <инструкции цикла>; оставьте это напоследок. На начальной стадии вам придется написать подпрограммы для вывода перемещаемого объектного кода; постарайтесь, чтобы ими было легко воспользоваться в дальнейшем.
Несомненно, в операционную среду Мини войдет стековая дисциплина выделения памяти для процедур. Когда остальные инструкции достаточно обкатаются, принимайтесь за структурные типы данных. Размещение цепочек во время выполнения требует кучи, которая, вероятно, будет разделять память со стеком. Указанные механизмы выделения памяти вызовут изменения в супервизоре УМ-1. Ранние версии не должны включать сбор мусора для утилизации освободившихся частей. Параллельно с распределением памяти можно работать над компиляцией раздельных сегментов. Не забудьте с самого начала вставить в объектные модули код для отладки.
ИНСТРУМЕНТОВКА. Пишите компилятор на каком-либо процедурном языке высокого уровня. Язык XPL как раз и предназначен для конструирования компиляторов. Сноболом пользоваться не следует, поскольку на этом языке компиляторы реализуются слишком легко и вы не получите необходимой подготовки.
ДЛИТЕЛЬНОСТЬ ИСПОЛНЕНИЯ. Двоим, троим или четверым на 10 недель. Каждый участник независимо отвечает за одну тестовую программу на Мини.
ЛИТЕРАТУРА
Грис (Gries D.). Compiler Construction for Digital Computers. Wiley, New York, NY, 1971. [Имеется перевод: Грис Д. Конструирование компиляторов для цифровых вычислительных машин.- М.: Мир, 1975.] Выдающаяся книга по реализации компиляторов. В ней написано все о простых компиляторах и даны указания по сложным. Правда, остались недостаточно освещенными таблично-управляемые методы разбора LR(k), но этот пробел с избытком покрывают другие упоминаемые здесь книги. Если вы уже выбрали язык для компиляции, Грис покажет, как ее провести.
Мак-Киман, Хорнинг, Уортмен (McKeeman W.M., Horning J.J., Wortman D.В.), A Compiler Generator. Printice-Hall, Englewood Cliffs, NJ, 1970.
В книге описывается язык XPL и его использование для конструирования компиляторов, В качестве иллюстрации метода приведен компилятор с XPL, написанный на XPL. В первых изданиях использовался ныне устаревший таблично-управляемый метод разбора SMSP, однако в следующих изданиях подробно обсуждается разбор LR(k). К сожалению, опубликованный листинг не претерпел изменений в сторону LR(k). He вошел и табличный генератор Де Ремера SLR(k). Книга может служить руководством по XPL.
Николс (Nikholls J.E.). Тhe Structure and Design of Programming Languages. Addison-Wesley, Reading, MA, 1975.
Пратт (Pratt T.W.) Programming Languages Design and Implementatioia. Prentice Hall, Englewood Cliffs, NJ, 1975. [Имеется перевод: Пратт Т. Языки программирования: разработка и реализация.- М.: Мир, 1979]
Обе книги нужно читать до проектирования языка и реализации компилятора. В них внимание сконцентрировано не на конкретных методах компиляции, а на изучении влияния языковых структур на программиста, поддерживаемую систему, конечного пользователя и разработчика компилятора. Авторы тщательно взвешивают все "за" и "против" различных решений при создании языка программирования.
* Ахо А., Ульман Дж. Теория синтаксического анализа, перевода и компиляции. Т.1, 2.- Пер. с англ.- М.: Мир, 1978.
Gudleifr- Admin
- Сообщения : 3252
Дата регистрации : 2017-03-29
Re: Уэзерелл. Этюды для программистов. 1982
автор Gudleifr Ср Мар 03, 2021 8:44 pm
28
НОВЫЙ АТ-ТРАК-ЦИОН,
ИЛИ...
ПОСТРОЕНИЕ ИНТЕРПРЕТАТОРА ЯЗЫКА ТРАК
Немного найдется языков программирования, которые начинающий программист мог бы реализовать в одиночку всего за несколько недель, но Трак (TRAC [TRAC - это фирменный знак Rockford Research Institute, Cambridge, MA]) - как раз такой язык. Целью разработчика Трака Калвина Муэрса было создание простого, элегантного, мощного и к тому же интерактивного языка. Он ухитрился на основе старой идеи макро сделать язык, который удовлетворяет всем этим требованиям, может использоваться также в пакетном режиме и вдобавок ко всему необычайно прост для реализации (для написания первого процессора хватило двух выходных дней). Для набора и редактирования рукописи английского оригинала книги использовался некоторый диалект языка Трак.
ЯЗЫК ТРАК
Представьте, что перед вами интерактивный терминал, который позволяет работать с процессором Трака. Вы набираете свои программы на клавиатуре, переходя, если нужно, с одной строки на другую и заканчивая каждую программу специальной заключительной МЕТАЛИТЕРОЙ (первоначально это апостроф '); эти программы сразу же выполняются. Как только процессор встречает металитеру, он интерпретирует вашу программу и выдает результаты работы на терминал. После этого вы можете набрать новую программу, вызывая тем самым повторение этого цикла. Сама программа может представлять собой любую цепочку литер, но некоторые специальные подцепочки служат для вызова встроенных функций Трака. Функции можно использовать для самых обычных действий с числами или с текстами, но они могут также записывать или извлекать результаты других функций, так что из их значений можно сложить огромные пирамиды.
Вызов функции выглядит как #(...) или ##(...), причем внутри скобок снова стоит произвольная цепочка. Тело функции разбито запятыми на аргументы (отсутствие запятых означает, что имеется один аргумент), вычисляемые слева направо по тем же правилам, что и вся программа. Предполагается, что первым аргументом является имя встроенной функции, остальные аргументы передаются этой функции для вычисления значения. Если вызов функции записан с одним диезом в виде #(...), то результат функции повторно сканируется, в противном случае результат передается дальше без обработки. Запись (...), где в цепочке внутри скобок соблюдается баланс скобок, ЗАЩИЩАЕТ эту цепочку от вычисления. Процессор просто удаляет внешние скобки и оставляет внутренность без внимания. Так, если ум означает функцию умножения, а сл - функцию сложения, то результатом вычисления входной цепочки
((3+4))*9=#(ум,#(сл,3,4),9)'
будет цепочка
(3+4)*9=63
Обратите внимание на вторую пару скобок вокруг 3+4; они необходимы, чтобы в выходной цепочке 3+4 осталось заключенным в скобки.
Все действия процессора подчиняются точно сформулированной процедуре, называемой АЛГОРИТМОМ ТРАК. Процессор содержит три структуры: АКТИВНУЮ ЦЕПОЧКУ, НЕЙТРАЛЬНУЮ ЦЕПОЧКУ и УКАЗАТЕЛЬ СКАНИРОВАНИЯ. Для наглядности обычно считают, что нейтральная цепочка располагается слева, указатель сканирования - посередине и активная цепочка - справа. Указатель сканирования всегда указывает на левый конец активной цепочки, обозревая первую литеру. Литеры, как правило, переходят из активной в нейтральную цепочку; там литеры накапливаются до тех пор, пока их не станет достаточно для построения всех аргументов некоторой функции. Тогда эта функция выполняется и ее результат помещается в активную или нейтральную цепочку в соответствии с типом функции.
АЛГОРИТМ ТРАК
Алгоритм состоит из 10 пронумерованных шагов. Работа процессора начинается с шага 1. В алгоритме кое-где говорится о различных отметках литер нейтральной цепочки. Представляйте себе эти отметки как флажки, поставленные у отмеченных литер (конечно, в реализации отметки будут представлены, вероятно, указателями). В любой практической реализации существует специальная клавиша "прерывание" для прекращения бесконечного цикла, предписанного алгоритмом.
1. Очистить процессор; для этого опустошить нейтральную цепочку, удалить содержимое активной цепочки, если оно есть, поместить туда цепочку #(пц,#(чц)) и установить указатель сканирования на первую литеру активной цепочки [Сейчас Муэрс использует холостую цепочку #(пц,(CR-LF))#(пц,#(чц)), где CR - литера "возврат каретки", a LF - "перевод строки"]. Перейти к следующему шагу.
2. Проанализировать литеру, на которую указывает указатель сканирования. Если ее нет, т.е. активная цепочка пуста, вернуться к шагу 1.
3. Если под указателем сканирования - литера табуляции, перевода строки, конца записи или возврата каретки, то удалить ее, продвинуть указатель к следующей литере и вернуться к шагу 2.
4. Если под указателем сканирования - левая скобка, то удалить ее и просмотреть активную цепочку вперед, пока не будет найдена СООТВЕТСТВУЮЩАЯ ей правая скобка. Переместить в неизменном виде все расположенные между этими скобками литеры в нейтральную цепочку, удалить правую скобку, продвинуть указатель сканирования вперед к следующей за ней литере и после этого вернуться к шагу 2. Если соответствующую правую скобку не удается найти, то вернуться к шагу 1.
5. Если литера, находящаяся под указателем сканирования,- запятая, то удалить ее, пометить самую правую литеру нейтральной цепочки как конец одного аргумента, а следующую литеру - как начало нового аргумента, продвинуть вперед указатель сканирования и вернуться к шагу 2.
6. Если под указателем сканирования - знак диез, а следующая литера - левая скобка, то это означает, что перед нами - начало активной функции. Удалить диез и скобку, продвинуть указатель сканирования после них, отметить самую правую литеру нейтральной цепочки одновременно как начало аргумента и начало АКТИВНОЙ функции и вернуться к шагу 2.
7. Если под указателем сканирования - знак диез и вслед за ним стоят еще один диез и левая скобка, то это значит, что начинается нейтральная функция. Удалить три литеры ##(, продвинуть указатель после них, отметить самую правую литеру нейтральной цепочки одновременно как начало аргумента и начало НЕЙТРАЛЬНОЙ функции и вернуться к шагу 2.
8. Если под указателем сканирования находится знак диез, но условия шагов 6, 7 не выполняются, то переместить диез в правый конец нейтральной цепочки, передвинуть указатель и вернуться к шагу 2.
9. Если под указателем сканирования оказалась правая скобка, это говорит об окончании функции. Удалить эту скобку, передвинуть указатель сканирования и отметить самую правую литеру нейтральной цепочки как конец аргумента и конец функции. Теперь нейтральная цепочка от самой правой отметки начала функции до только что поставленной отметки конца функции составляет вызов функции Трака. (Если в нейтральной цепочке нет отметки начала функции, то вернуться к шагу 1.) Удалить из нейтральной цепочки аргументы функции (все те аргументы, отметки которых стоят после отметки начала функции) вместе с отметками функции и аргументов. (Ввиду способа нанесения отметок все отметки начала стоят в действительности у литер, непосредственно предшествующих отмечаемым элементам). Предполагается, что первым аргументом является имя встроенной функции Трака. Вычислить функцию с данными аргументами; лишние аргументы игнорируются, недостающие аргументы автоматически добавляются со значением "пустая цепочка". Значение функции присоединяется справа к нейтральной цепочке, если функция была отмечена как нейтральная, и слева к активной цепочке, если функция была отмечена как активная; в последнем случае указатель сканирования устанавливается на левый конец новой активной цепочки. Если первый аргумент не является именем никакой встроенной функции, то просто поместить в качестве результата функции пустую цепочку. Вернуться к шагу 2.
10. Если литера под указателем сканирования не удовлетворяет ни одному из условий шагов с 3-го по 9-й, то присоединить ее к правому концу нейтральной цепочки, удалить ее из активной цепочки, передвинуть указатель сканирования и вернуться к шагу 2.
...
НОВЫЙ АТ-ТРАК-ЦИОН,
ИЛИ...
ПОСТРОЕНИЕ ИНТЕРПРЕТАТОРА ЯЗЫКА ТРАК
Немного найдется языков программирования, которые начинающий программист мог бы реализовать в одиночку всего за несколько недель, но Трак (TRAC [TRAC - это фирменный знак Rockford Research Institute, Cambridge, MA]) - как раз такой язык. Целью разработчика Трака Калвина Муэрса было создание простого, элегантного, мощного и к тому же интерактивного языка. Он ухитрился на основе старой идеи макро сделать язык, который удовлетворяет всем этим требованиям, может использоваться также в пакетном режиме и вдобавок ко всему необычайно прост для реализации (для написания первого процессора хватило двух выходных дней). Для набора и редактирования рукописи английского оригинала книги использовался некоторый диалект языка Трак.
ЯЗЫК ТРАК
Представьте, что перед вами интерактивный терминал, который позволяет работать с процессором Трака. Вы набираете свои программы на клавиатуре, переходя, если нужно, с одной строки на другую и заканчивая каждую программу специальной заключительной МЕТАЛИТЕРОЙ (первоначально это апостроф '); эти программы сразу же выполняются. Как только процессор встречает металитеру, он интерпретирует вашу программу и выдает результаты работы на терминал. После этого вы можете набрать новую программу, вызывая тем самым повторение этого цикла. Сама программа может представлять собой любую цепочку литер, но некоторые специальные подцепочки служат для вызова встроенных функций Трака. Функции можно использовать для самых обычных действий с числами или с текстами, но они могут также записывать или извлекать результаты других функций, так что из их значений можно сложить огромные пирамиды.
Вызов функции выглядит как #(...) или ##(...), причем внутри скобок снова стоит произвольная цепочка. Тело функции разбито запятыми на аргументы (отсутствие запятых означает, что имеется один аргумент), вычисляемые слева направо по тем же правилам, что и вся программа. Предполагается, что первым аргументом является имя встроенной функции, остальные аргументы передаются этой функции для вычисления значения. Если вызов функции записан с одним диезом в виде #(...), то результат функции повторно сканируется, в противном случае результат передается дальше без обработки. Запись (...), где в цепочке внутри скобок соблюдается баланс скобок, ЗАЩИЩАЕТ эту цепочку от вычисления. Процессор просто удаляет внешние скобки и оставляет внутренность без внимания. Так, если ум означает функцию умножения, а сл - функцию сложения, то результатом вычисления входной цепочки
((3+4))*9=#(ум,#(сл,3,4),9)'
будет цепочка
(3+4)*9=63
Обратите внимание на вторую пару скобок вокруг 3+4; они необходимы, чтобы в выходной цепочке 3+4 осталось заключенным в скобки.
Все действия процессора подчиняются точно сформулированной процедуре, называемой АЛГОРИТМОМ ТРАК. Процессор содержит три структуры: АКТИВНУЮ ЦЕПОЧКУ, НЕЙТРАЛЬНУЮ ЦЕПОЧКУ и УКАЗАТЕЛЬ СКАНИРОВАНИЯ. Для наглядности обычно считают, что нейтральная цепочка располагается слева, указатель сканирования - посередине и активная цепочка - справа. Указатель сканирования всегда указывает на левый конец активной цепочки, обозревая первую литеру. Литеры, как правило, переходят из активной в нейтральную цепочку; там литеры накапливаются до тех пор, пока их не станет достаточно для построения всех аргументов некоторой функции. Тогда эта функция выполняется и ее результат помещается в активную или нейтральную цепочку в соответствии с типом функции.
АЛГОРИТМ ТРАК
Алгоритм состоит из 10 пронумерованных шагов. Работа процессора начинается с шага 1. В алгоритме кое-где говорится о различных отметках литер нейтральной цепочки. Представляйте себе эти отметки как флажки, поставленные у отмеченных литер (конечно, в реализации отметки будут представлены, вероятно, указателями). В любой практической реализации существует специальная клавиша "прерывание" для прекращения бесконечного цикла, предписанного алгоритмом.
1. Очистить процессор; для этого опустошить нейтральную цепочку, удалить содержимое активной цепочки, если оно есть, поместить туда цепочку #(пц,#(чц)) и установить указатель сканирования на первую литеру активной цепочки [Сейчас Муэрс использует холостую цепочку #(пц,(CR-LF))#(пц,#(чц)), где CR - литера "возврат каретки", a LF - "перевод строки"]. Перейти к следующему шагу.
2. Проанализировать литеру, на которую указывает указатель сканирования. Если ее нет, т.е. активная цепочка пуста, вернуться к шагу 1.
3. Если под указателем сканирования - литера табуляции, перевода строки, конца записи или возврата каретки, то удалить ее, продвинуть указатель к следующей литере и вернуться к шагу 2.
4. Если под указателем сканирования - левая скобка, то удалить ее и просмотреть активную цепочку вперед, пока не будет найдена СООТВЕТСТВУЮЩАЯ ей правая скобка. Переместить в неизменном виде все расположенные между этими скобками литеры в нейтральную цепочку, удалить правую скобку, продвинуть указатель сканирования вперед к следующей за ней литере и после этого вернуться к шагу 2. Если соответствующую правую скобку не удается найти, то вернуться к шагу 1.
5. Если литера, находящаяся под указателем сканирования,- запятая, то удалить ее, пометить самую правую литеру нейтральной цепочки как конец одного аргумента, а следующую литеру - как начало нового аргумента, продвинуть вперед указатель сканирования и вернуться к шагу 2.
6. Если под указателем сканирования - знак диез, а следующая литера - левая скобка, то это означает, что перед нами - начало активной функции. Удалить диез и скобку, продвинуть указатель сканирования после них, отметить самую правую литеру нейтральной цепочки одновременно как начало аргумента и начало АКТИВНОЙ функции и вернуться к шагу 2.
7. Если под указателем сканирования - знак диез и вслед за ним стоят еще один диез и левая скобка, то это значит, что начинается нейтральная функция. Удалить три литеры ##(, продвинуть указатель после них, отметить самую правую литеру нейтральной цепочки одновременно как начало аргумента и начало НЕЙТРАЛЬНОЙ функции и вернуться к шагу 2.
8. Если под указателем сканирования находится знак диез, но условия шагов 6, 7 не выполняются, то переместить диез в правый конец нейтральной цепочки, передвинуть указатель и вернуться к шагу 2.
9. Если под указателем сканирования оказалась правая скобка, это говорит об окончании функции. Удалить эту скобку, передвинуть указатель сканирования и отметить самую правую литеру нейтральной цепочки как конец аргумента и конец функции. Теперь нейтральная цепочка от самой правой отметки начала функции до только что поставленной отметки конца функции составляет вызов функции Трака. (Если в нейтральной цепочке нет отметки начала функции, то вернуться к шагу 1.) Удалить из нейтральной цепочки аргументы функции (все те аргументы, отметки которых стоят после отметки начала функции) вместе с отметками функции и аргументов. (Ввиду способа нанесения отметок все отметки начала стоят в действительности у литер, непосредственно предшествующих отмечаемым элементам). Предполагается, что первым аргументом является имя встроенной функции Трака. Вычислить функцию с данными аргументами; лишние аргументы игнорируются, недостающие аргументы автоматически добавляются со значением "пустая цепочка". Значение функции присоединяется справа к нейтральной цепочке, если функция была отмечена как нейтральная, и слева к активной цепочке, если функция была отмечена как активная; в последнем случае указатель сканирования устанавливается на левый конец новой активной цепочки. Если первый аргумент не является именем никакой встроенной функции, то просто поместить в качестве результата функции пустую цепочку. Вернуться к шагу 2.
10. Если литера под указателем сканирования не удовлетворяет ни одному из условий шагов с 3-го по 9-й, то присоединить ее к правому концу нейтральной цепочки, удалить ее из активной цепочки, передвинуть указатель сканирования и вернуться к шагу 2.
...
Gudleifr- Admin
- Сообщения : 3252
Дата регистрации : 2017-03-29
Re: Уэзерелл. Этюды для программистов. 1982
автор Gudleifr Ср Мар 03, 2021 8:45 pm
...
ФУНКЦИИ ТРАКА
Ниже перечислены функции Трака в активной записи, но все они могут вызываться также и в нейтральном режиме. У функции всегда есть значение в виде цепочки, однако функциям не возбраняется выдать в качестве значения пустую цепочку; в особенности это имеет смысл для тех функций, результат которых выражается в побочных эффектах. В дополнение к уже упомянутым структурам процессор может записывать цепочки в некоторой области памяти, называемой ПАМЯТЬЮ БЛАНКОВ. Каждый бланк состоит из трех частей: ИМЕНИ БЛАНКА, в качестве которого может выступать любая цепочка, ТЕЛА БЛАНКА, которое тоже может быть любой цепочкой, и УКАЗАТЕЛЯ БЛАНКА, первоначально указывающего на позицию непосредственно перед первой литерой тела бланка. Указатель бланка всегда указывает ка позицию непосредственно перед телом, непосредственно после него или между двумя литерами; иначе говоря, он всегда указывает на ПРОМЕЖУТОК между литерами. В телах бланков вперемежку с литерами могут находиться порядковые метки сегментов. С каждой такой меткой связано некоторое положительное целое число, причем эти числа у разных меток не обязаны различаться. Приведенные ниже описания функций слегка переработаны в сравнении с предложениями Муэрса:
#(чц) "Чтение цепочки" (один аргумент). Значением этой функции является входной поток литер до ближайшей металитеры (не включая ее). В результирующую цепочку входят все возвраты каретки, переводы строк, концы записей и литеры табуляции, которые система передает программе в обычных условиях. Металитера всегда отбрасывается, а в системах, ориентированных на использование записей, отбрасывается также и все после металитеры в той же записи.
#(чл) "Чтение литеры" (один аргумент). В качестве значения функции выдается следующая входная литера, какой бы она ни оказалась. Этим способом можно прочитать любую литеру, включая металитеру.
#(пц,X) "Печать цепочки" (два аргумента). Второй аргумент X печатается на устройстве вывода. Значением функции является пустая цепочка.
#(им,X) "Изменение металитеры" (два аргумента). Эта функция с пустым значением (со значением "пустая цепочка") делает металитерой первую литеру цепочки X. Первоначально роль металитеры играет апостроф.
#(оц,N,B) "Определение цепочки" (три аргумента). Эта функция с пустым значением создает бланк с именем N и телом B. Указатель этого бланка указывает на точку перед первой литерой B. Если бланк с именем N уже существовал, то его предыдущее тело и указатель теряются.
#(сц,N,P1,P2,...) "Сегментация цепочки" (не менее трех аргументов). Эта функция с пустым значением создает в бланке N порядковые метки сегментов. Непустые аргументы P1, P2, ... обрабатываются поочередно, слева направо (пустые аргументы игнорируются). Обработка одного аргумента Pi состоит в следующем. Тело бланка N просматривается слева направо, пока не будет найдена подцепочка, в точности равная Pi Эта подцепочка не должна содержать никаких ранее поставленных меток сегментов. Если это так, то подцепочка выбрасывается из тела бланка и на ее место ставится порядковая метка сегмента с номером i. Затем процесс поиска совпадающей подцепочки возобновляется с литеры, лежащей вслед за меткой. После окончания сегментации указатель бланка устанавливается на левый конец бланка. Можно несколько раз сегментировать один бланк.
#(вц,N,A1,A2,...) "Вызов цепочки" (два или больше аргументов). Значением этой функции является тело бланка N, в котором метки сегментов заменены на некоторые подцепочки. Все метки с номером 1 заменяются на аргумент A1, метки с номером 2 - на A2 и т.д. Функции вц требуется такое количество аргументов, каков наибольший номер сегмента в бланке N. Напомним, что лишние аргументы игнорируются, а недостающие считаются пустыми цепочками.
#(вс,N,Z) "Вызов сегмента" (три аргумента). Значением этой функции является подцепочка бланка N от текущего положения указателя бланка до ближайшей справа метки сегмента (в данной функции конец тела рассматривается как метка). Метка не входит в значение функции; указатель бланка помещается непосредственно перед литерой, ближайшей справа к найденной метке. Если перед выполнением функции указатель бланка уже указывал на правый край тела, то значением функции будет аргумент Z, возвращаемый в активном режиме, независимо от режима вызова функции.
#(вл,N,Z) "Вызов литеры" (три аргумента). Значением функции является литера, лежащая сразу вслед за указателем бланка в бланке N. Указатель передвигается в промежуток, следующий за выбранной литерой. Указатель бланка пропускает все метки сегментов, поскольку они - не литеры. Если указатель бланка уже указывает на правый край цепочки, то в качестве значения функции выдается аргумент Z в активном режиме независимо от режима вызова функции.
#(вн,N,D,Z) "Вызов нескольких литер" (четыре аргумента). Значением функции является подцепочка бланка N. Эта подцепочка начинается от текущего положения указателя бланка и содержит |D| литер вправо от него, если D положительно, или влево, если D отрицательно [Позднее мы рассмотрим, каким образом цепочка может представлять число]). Литеры в значении функции расположены в том же порядке, что и в теле бланка, т.е. при отрицательном D цепочка не обращается. Метки сегментов, конечно, игнорируются. Указатель бланка передвигается в точку между выбранной подцепочкой и первой непрочитанной литерой в заданном направлении. (Если D равно нулю, то значением будет пустая цепочка, а указатель останется на месте). Если указателю бланка приходится покинуть цепочку на любом из концов, то значением функции будет аргумент Z, помещаемый в активную цепочку, независимо от режима вызова функции.
#(пс,N,X,Z) "Первое совпадение" (четыре аргумента). Бланк N просматривается вправо от указателя бланка в поисках подцепочки, совпадающей с X и не содержащей меток сегментов. Если такое совпадение найдено, то значением функции будет подцепочка бланка от исходного положения указателя до литеры, находящейся непосредственно перед совпадающей подцепочкой (из значения удаляются метки сегментов), а указатель бланка будет переставлен так, чтобы указывать на позицию непосредственно перед литерой, находящейся непосредственно после совпавшей подцепочки. Если совпадения не найдено, то значением функции будет аргумент Z в активном режиме независимо от режима вызова функции, а указатель бланка останется на прежнем месте.
#(пу,N) "Переустановка указателя" (два аргумента). Эта функция с пустым значением возвращает указатель бланка N в его исходное положение перед первой литерой бланка.
#(уо,N1,N2,...) "Удалить определение" (два или более аргумента). Эта функция с пустым значением удаляет бланки с именами N1, N2, ... из памяти бланков.
#(ув) "Удалить все" (один аргумент). Эта функция с пустым значением удаляет из памяти бланков все бланки.
Трак выполняет арифметические действия над цепочками из "десятичных" литер. У каждой цепочки имеется арифметическое значение. Оно определяется наиболее длинной подцепочкой, примыкающей к правому краю цепочки и состоящей только из десятичных цифр, перед которыми стоит не более одного знака плюс или минус. Так, арифметическим значением 3 является три, значением a-4 является минус четыре, ++++200 имеет значение двести, а значением пустой цепочки и abc является пустая цепочка. В арифметических операциях пустая цепочка воспринимается как нуль. Точность арифметических действий не ограничена - мы не должны подстраиваться под ограничения какой-либо реальной аппаратуры. Результат арифметических операций также будет содержать десятичную цепочку того же вида без старших нулей и без плюса для положительных чисел; нуль будет представлен как 0.
#(сл,A,B) "Сложение" (три аргумента). Значением функции является сумма арифметических значений аргументов, перед которой помещена начальная нечисловая часть аргумента A. Начальная часть аргумента B теряется.
#(вч,A,B) "Вычитание" (три аргумента). Значением функции является результат вычитания арифметического значения аргумента B из арифметического значения A; начальная нечисловая часть A присоединяется спереди к полученной десятичной цепочке, а начальная часть B теряется.
#(ум,А,B) "Умножение" (три аргумента). Значением функций является произведение арифметических значений аргументов А и B, перед которым помещена начальная нечисловая часть B. Начальная часть B теряется.
#(дл,A,B,Z) "Деление" (четыре аргумента). Значением функции является частное от деления числового значения аргумента A на числовое значение B перед результатом помещается начальная часть A. Начальная часть B теряется. Выполняется целочисленное деление, у частного сохраняется только целая часть; остаток всегда неотрицателен. Если B имеет значение нуль, то значением функции будет аргумент Z в активном режиме независимо от режима вызова функции.
Аналогично арифметическим значениям в Траке функционируют логические значения. Логическим значением цепочки считается наиболее длинная ее правая часть, состоящая целиком из нулей и единиц, т.е. являющаяся двоичной цепочкой. Так, цепочка abcO0100 имеет логическое значение 0100, цепочка 1234567890 - значение 0, цепочка 43210 - 10, а логическим значением abc является, по определению, пустая цепочка.
#(ло,A,B) "Логическое объединение" (три аргумента). Значением этой функции является побитовое логическое объединение Логических значений аргументов А и B. Если они имеют разные длины, то более короткое дополняется СЛЕВА необходимым количеством нулей для уравнивания длин. Любые нелогические начальные части аргументов теряются.
#(лп,A,B) "Логическое пересечение" (три аргумента). Значением функции является побитовое логическое пересечение логических значений аргументов A и B. Если аргументы имеют неравные длины, то более длинный усекается слева для выравнивания длин. Любые нелогические начальные части аргументов теряются.
#(лд,A) "Логическое дополнение" (два аргумента). Значение этой функции - побитовое логическое дополнение аргумента A, имеющее ту же длину. Нелогическая начальная часть аргумента теряется.
#(лс,S,A) "Логический сдвиг" (три аргумента). Значением этой функции является сдвинутое логическое значение аргумента A. Величина сдвига дается арифметическим значением аргумента S. Если оно положительно, то происходит сгвиг влево, если отрицательно - то вправо. Значение функции имеет ту же длину, что логическое значение A; освобождающиеся позиции заполняются нулями. Нелогическая начальная часть A теряется.
#(лц,S,A) "Логический циклический сдвиг" (три аргумента). Значением функции является результат циклического сдвига (поворота) логического значения аргумента A. Величина сдвига задается арифметическим значением аргумента S; сдвиг происходит влево, если значение S положительно, и вправо, если оно отрицательно. Циклический сдвиг не меняет длины аргумента. Нелогическая начальная часть A теряется.
#(рв,A,B,T,F) "Равенство" (пять аргументов). Если аргумент A в точности совпадает как цепочка с аргументом B, то значением функции является аргумент T, в противном случае значение функции - аргумент F. Отметим, что Т и F могут быть любыми цепочками.
#(бл,A,B,T,F) "Больше" (пять аргументов). Значением этой функции является аргумент T, если арифметическое значение A больше арифметического значения B, и аргумент F в противном случае.
#(зб,A,F1,F2,...) "Запись блока" (три или больше аргументов). Функция записывает бланки с именами F1, F2, ... на некоторое внешнее запоминающее устройство. После записи всех бланков они удаляются из памяти бланков и создается новый бланк с именем A, тело которого есть адрес во внешней памяти записанного блока бланков. Если уже есть бланк с именем A, то его старое значение теряется. "Адресом" блока должна быть цепочка; доступ к бланкам во внешней памяти осуществляется при помощи любого бланка, имеющего значением цепочку-адрес. Значение этой функции - пустая цепочка.
#(иб,A) "Извлечь блок" (два аргумента). Эта функция с пустым значением извлекает из внешней памяти блок бланков, "адрес" которого находится в теле бланка с именем A. Бланки возвращаются в память бланков, и если какие-либо из них уже существуют, то прочитанные значения заменяют их старые значения. Внешний блок бланков по-прежнему остается доступным.
#(уб,A) "Удалить блок" (два аргумента). Эта, функция с пустым значением освобождает внешнюю память, в которой хранится блок по адресу, указанному в теле бланка A; этот блок становится недоступным. Одновременно удаляется бланк A.
#(си,S) "Список имен" (два аргумента). Значение этой функции - список имен всех бланков, присутствующих в данный момент в памяти бланков. Имена разделяются цепочкой S.
#(пб,N) "Печать бланка" (два аргумента). Эта функция с пустым значением печатает тело бланка N; на печать выдаются также указатель бланка и метки сегментов. Муэрс предлагает печатать указатель бланка в виде <^>, а метку сегмента- в виде <i>. Таким образом, результатом пб может быть нечто вроде aB<2>cdEE<1>f<^><1>hiJ; мы видим одно вхождение метки 2 и два вхождения метки 1.
#(вт) "Включение трассировки" (один аргумент). Эта функция с пустым значением заставляет процессор начать трассировку выполнения функций. Всякий раз, когда функция готова к выполнению, на устройство вывода выдаются все ее аргументы. Если процессор работает в интерактивной системе, то после печати каждого списка аргументов делается пауза, позволяющая пользователю ввести некоторую цепочку. Если это будет пустая цепочка, то процессор продолжает работу, вычисляя функцию; любая другая цепочка вызывает переход к шагу 1 алгоритма Трак.
#(кт) "Выключение (конец) трассировки" (один аргумент). Эта функция с пустым значением выключает трассировку; если трассировка не была включена, то выполнение функции не оказывает никакого воздействия.
...
ФУНКЦИИ ТРАКА
Ниже перечислены функции Трака в активной записи, но все они могут вызываться также и в нейтральном режиме. У функции всегда есть значение в виде цепочки, однако функциям не возбраняется выдать в качестве значения пустую цепочку; в особенности это имеет смысл для тех функций, результат которых выражается в побочных эффектах. В дополнение к уже упомянутым структурам процессор может записывать цепочки в некоторой области памяти, называемой ПАМЯТЬЮ БЛАНКОВ. Каждый бланк состоит из трех частей: ИМЕНИ БЛАНКА, в качестве которого может выступать любая цепочка, ТЕЛА БЛАНКА, которое тоже может быть любой цепочкой, и УКАЗАТЕЛЯ БЛАНКА, первоначально указывающего на позицию непосредственно перед первой литерой тела бланка. Указатель бланка всегда указывает ка позицию непосредственно перед телом, непосредственно после него или между двумя литерами; иначе говоря, он всегда указывает на ПРОМЕЖУТОК между литерами. В телах бланков вперемежку с литерами могут находиться порядковые метки сегментов. С каждой такой меткой связано некоторое положительное целое число, причем эти числа у разных меток не обязаны различаться. Приведенные ниже описания функций слегка переработаны в сравнении с предложениями Муэрса:
#(чц) "Чтение цепочки" (один аргумент). Значением этой функции является входной поток литер до ближайшей металитеры (не включая ее). В результирующую цепочку входят все возвраты каретки, переводы строк, концы записей и литеры табуляции, которые система передает программе в обычных условиях. Металитера всегда отбрасывается, а в системах, ориентированных на использование записей, отбрасывается также и все после металитеры в той же записи.
#(чл) "Чтение литеры" (один аргумент). В качестве значения функции выдается следующая входная литера, какой бы она ни оказалась. Этим способом можно прочитать любую литеру, включая металитеру.
#(пц,X) "Печать цепочки" (два аргумента). Второй аргумент X печатается на устройстве вывода. Значением функции является пустая цепочка.
#(им,X) "Изменение металитеры" (два аргумента). Эта функция с пустым значением (со значением "пустая цепочка") делает металитерой первую литеру цепочки X. Первоначально роль металитеры играет апостроф.
#(оц,N,B) "Определение цепочки" (три аргумента). Эта функция с пустым значением создает бланк с именем N и телом B. Указатель этого бланка указывает на точку перед первой литерой B. Если бланк с именем N уже существовал, то его предыдущее тело и указатель теряются.
#(сц,N,P1,P2,...) "Сегментация цепочки" (не менее трех аргументов). Эта функция с пустым значением создает в бланке N порядковые метки сегментов. Непустые аргументы P1, P2, ... обрабатываются поочередно, слева направо (пустые аргументы игнорируются). Обработка одного аргумента Pi состоит в следующем. Тело бланка N просматривается слева направо, пока не будет найдена подцепочка, в точности равная Pi Эта подцепочка не должна содержать никаких ранее поставленных меток сегментов. Если это так, то подцепочка выбрасывается из тела бланка и на ее место ставится порядковая метка сегмента с номером i. Затем процесс поиска совпадающей подцепочки возобновляется с литеры, лежащей вслед за меткой. После окончания сегментации указатель бланка устанавливается на левый конец бланка. Можно несколько раз сегментировать один бланк.
#(вц,N,A1,A2,...) "Вызов цепочки" (два или больше аргументов). Значением этой функции является тело бланка N, в котором метки сегментов заменены на некоторые подцепочки. Все метки с номером 1 заменяются на аргумент A1, метки с номером 2 - на A2 и т.д. Функции вц требуется такое количество аргументов, каков наибольший номер сегмента в бланке N. Напомним, что лишние аргументы игнорируются, а недостающие считаются пустыми цепочками.
#(вс,N,Z) "Вызов сегмента" (три аргумента). Значением этой функции является подцепочка бланка N от текущего положения указателя бланка до ближайшей справа метки сегмента (в данной функции конец тела рассматривается как метка). Метка не входит в значение функции; указатель бланка помещается непосредственно перед литерой, ближайшей справа к найденной метке. Если перед выполнением функции указатель бланка уже указывал на правый край тела, то значением функции будет аргумент Z, возвращаемый в активном режиме, независимо от режима вызова функции.
#(вл,N,Z) "Вызов литеры" (три аргумента). Значением функции является литера, лежащая сразу вслед за указателем бланка в бланке N. Указатель передвигается в промежуток, следующий за выбранной литерой. Указатель бланка пропускает все метки сегментов, поскольку они - не литеры. Если указатель бланка уже указывает на правый край цепочки, то в качестве значения функции выдается аргумент Z в активном режиме независимо от режима вызова функции.
#(вн,N,D,Z) "Вызов нескольких литер" (четыре аргумента). Значением функции является подцепочка бланка N. Эта подцепочка начинается от текущего положения указателя бланка и содержит |D| литер вправо от него, если D положительно, или влево, если D отрицательно [Позднее мы рассмотрим, каким образом цепочка может представлять число]). Литеры в значении функции расположены в том же порядке, что и в теле бланка, т.е. при отрицательном D цепочка не обращается. Метки сегментов, конечно, игнорируются. Указатель бланка передвигается в точку между выбранной подцепочкой и первой непрочитанной литерой в заданном направлении. (Если D равно нулю, то значением будет пустая цепочка, а указатель останется на месте). Если указателю бланка приходится покинуть цепочку на любом из концов, то значением функции будет аргумент Z, помещаемый в активную цепочку, независимо от режима вызова функции.
#(пс,N,X,Z) "Первое совпадение" (четыре аргумента). Бланк N просматривается вправо от указателя бланка в поисках подцепочки, совпадающей с X и не содержащей меток сегментов. Если такое совпадение найдено, то значением функции будет подцепочка бланка от исходного положения указателя до литеры, находящейся непосредственно перед совпадающей подцепочкой (из значения удаляются метки сегментов), а указатель бланка будет переставлен так, чтобы указывать на позицию непосредственно перед литерой, находящейся непосредственно после совпавшей подцепочки. Если совпадения не найдено, то значением функции будет аргумент Z в активном режиме независимо от режима вызова функции, а указатель бланка останется на прежнем месте.
#(пу,N) "Переустановка указателя" (два аргумента). Эта функция с пустым значением возвращает указатель бланка N в его исходное положение перед первой литерой бланка.
#(уо,N1,N2,...) "Удалить определение" (два или более аргумента). Эта функция с пустым значением удаляет бланки с именами N1, N2, ... из памяти бланков.
#(ув) "Удалить все" (один аргумент). Эта функция с пустым значением удаляет из памяти бланков все бланки.
Трак выполняет арифметические действия над цепочками из "десятичных" литер. У каждой цепочки имеется арифметическое значение. Оно определяется наиболее длинной подцепочкой, примыкающей к правому краю цепочки и состоящей только из десятичных цифр, перед которыми стоит не более одного знака плюс или минус. Так, арифметическим значением 3 является три, значением a-4 является минус четыре, ++++200 имеет значение двести, а значением пустой цепочки и abc является пустая цепочка. В арифметических операциях пустая цепочка воспринимается как нуль. Точность арифметических действий не ограничена - мы не должны подстраиваться под ограничения какой-либо реальной аппаратуры. Результат арифметических операций также будет содержать десятичную цепочку того же вида без старших нулей и без плюса для положительных чисел; нуль будет представлен как 0.
#(сл,A,B) "Сложение" (три аргумента). Значением функции является сумма арифметических значений аргументов, перед которой помещена начальная нечисловая часть аргумента A. Начальная часть аргумента B теряется.
#(вч,A,B) "Вычитание" (три аргумента). Значением функции является результат вычитания арифметического значения аргумента B из арифметического значения A; начальная нечисловая часть A присоединяется спереди к полученной десятичной цепочке, а начальная часть B теряется.
#(ум,А,B) "Умножение" (три аргумента). Значением функций является произведение арифметических значений аргументов А и B, перед которым помещена начальная нечисловая часть B. Начальная часть B теряется.
#(дл,A,B,Z) "Деление" (четыре аргумента). Значением функции является частное от деления числового значения аргумента A на числовое значение B перед результатом помещается начальная часть A. Начальная часть B теряется. Выполняется целочисленное деление, у частного сохраняется только целая часть; остаток всегда неотрицателен. Если B имеет значение нуль, то значением функции будет аргумент Z в активном режиме независимо от режима вызова функции.
Аналогично арифметическим значениям в Траке функционируют логические значения. Логическим значением цепочки считается наиболее длинная ее правая часть, состоящая целиком из нулей и единиц, т.е. являющаяся двоичной цепочкой. Так, цепочка abcO0100 имеет логическое значение 0100, цепочка 1234567890 - значение 0, цепочка 43210 - 10, а логическим значением abc является, по определению, пустая цепочка.
#(ло,A,B) "Логическое объединение" (три аргумента). Значением этой функции является побитовое логическое объединение Логических значений аргументов А и B. Если они имеют разные длины, то более короткое дополняется СЛЕВА необходимым количеством нулей для уравнивания длин. Любые нелогические начальные части аргументов теряются.
#(лп,A,B) "Логическое пересечение" (три аргумента). Значением функции является побитовое логическое пересечение логических значений аргументов A и B. Если аргументы имеют неравные длины, то более длинный усекается слева для выравнивания длин. Любые нелогические начальные части аргументов теряются.
#(лд,A) "Логическое дополнение" (два аргумента). Значение этой функции - побитовое логическое дополнение аргумента A, имеющее ту же длину. Нелогическая начальная часть аргумента теряется.
#(лс,S,A) "Логический сдвиг" (три аргумента). Значением этой функции является сдвинутое логическое значение аргумента A. Величина сдвига дается арифметическим значением аргумента S. Если оно положительно, то происходит сгвиг влево, если отрицательно - то вправо. Значение функции имеет ту же длину, что логическое значение A; освобождающиеся позиции заполняются нулями. Нелогическая начальная часть A теряется.
#(лц,S,A) "Логический циклический сдвиг" (три аргумента). Значением функции является результат циклического сдвига (поворота) логического значения аргумента A. Величина сдвига задается арифметическим значением аргумента S; сдвиг происходит влево, если значение S положительно, и вправо, если оно отрицательно. Циклический сдвиг не меняет длины аргумента. Нелогическая начальная часть A теряется.
#(рв,A,B,T,F) "Равенство" (пять аргументов). Если аргумент A в точности совпадает как цепочка с аргументом B, то значением функции является аргумент T, в противном случае значение функции - аргумент F. Отметим, что Т и F могут быть любыми цепочками.
#(бл,A,B,T,F) "Больше" (пять аргументов). Значением этой функции является аргумент T, если арифметическое значение A больше арифметического значения B, и аргумент F в противном случае.
#(зб,A,F1,F2,...) "Запись блока" (три или больше аргументов). Функция записывает бланки с именами F1, F2, ... на некоторое внешнее запоминающее устройство. После записи всех бланков они удаляются из памяти бланков и создается новый бланк с именем A, тело которого есть адрес во внешней памяти записанного блока бланков. Если уже есть бланк с именем A, то его старое значение теряется. "Адресом" блока должна быть цепочка; доступ к бланкам во внешней памяти осуществляется при помощи любого бланка, имеющего значением цепочку-адрес. Значение этой функции - пустая цепочка.
#(иб,A) "Извлечь блок" (два аргумента). Эта функция с пустым значением извлекает из внешней памяти блок бланков, "адрес" которого находится в теле бланка с именем A. Бланки возвращаются в память бланков, и если какие-либо из них уже существуют, то прочитанные значения заменяют их старые значения. Внешний блок бланков по-прежнему остается доступным.
#(уб,A) "Удалить блок" (два аргумента). Эта, функция с пустым значением освобождает внешнюю память, в которой хранится блок по адресу, указанному в теле бланка A; этот блок становится недоступным. Одновременно удаляется бланк A.
#(си,S) "Список имен" (два аргумента). Значение этой функции - список имен всех бланков, присутствующих в данный момент в памяти бланков. Имена разделяются цепочкой S.
#(пб,N) "Печать бланка" (два аргумента). Эта функция с пустым значением печатает тело бланка N; на печать выдаются также указатель бланка и метки сегментов. Муэрс предлагает печатать указатель бланка в виде <^>, а метку сегмента- в виде <i>. Таким образом, результатом пб может быть нечто вроде aB<2>cdEE<1>f<^><1>hiJ; мы видим одно вхождение метки 2 и два вхождения метки 1.
#(вт) "Включение трассировки" (один аргумент). Эта функция с пустым значением заставляет процессор начать трассировку выполнения функций. Всякий раз, когда функция готова к выполнению, на устройство вывода выдаются все ее аргументы. Если процессор работает в интерактивной системе, то после печати каждого списка аргументов делается пауза, позволяющая пользователю ввести некоторую цепочку. Если это будет пустая цепочка, то процессор продолжает работу, вычисляя функцию; любая другая цепочка вызывает переход к шагу 1 алгоритма Трак.
#(кт) "Выключение (конец) трассировки" (один аргумент). Эта функция с пустым значением выключает трассировку; если трассировка не была включена, то выполнение функции не оказывает никакого воздействия.
...
Gudleifr- Admin
- Сообщения : 3252
Дата регистрации : 2017-03-29
Re: Уэзерелл. Этюды для программистов. 1982
автор Gudleifr Ср Мар 03, 2021 8:47 pm
...
ПРИМЕРЫ
Следующие примеры помогут вам почувствовать некоторые возможности языка Трак. Не думайте, однако, что эти конкретные примеры иллюстрируют все возможности каких-либо функций.
#(оц,AA,Кот)'
#(оц,BB,(#(вц,AA)))'
#(пц,(#(вц,BB)))'
#(пц,##(вц,BB))'
#(пц,#(вц,ВВ))'
Выполнение первой строки из этого ряда программ (заметьте, что каждая строка оканчивается металитерой - апострофом) приводит к запоминанию бланка с именем AA и телом Кот и к печати пустой цепочки. Вторая строка аналогичным образом создает бланк с телом #(вц,AA) и именем BB и печатает пустую цепочку. Дальше начинается самое интересное. Функция пц в третьей строке печатает #(вц,BB), поскольку внутренняя функция защищена скобками; та же функция в четвертой строке печатает #(вц,AA), поскольку внутренняя функция - нейтральная и, наконец, при выполнении пятой строки печатается Кот.
#(уо,#(си,(,)))'
Эта программа делает точно то же, что и вызов #(ув). Аргументами уо должны быть имена бланков, и си генерирует список имен, разделенных запятыми.
#(оц,Факториал,(#(рв,X,1,1,(#(ум,X,#(вц,Факториал,#(вч,X,1)))))))'
#(сц,Факториал,X)'
#(вц,Факториал,5)'
В этих трех строках стандартным рекурсивным способом определяется функция факториал, цепочка Факториал сегментируется по аргументу X и затем вычисляется значение 5!. Необходимы обе пары защитных скобок; внешняя защищает рв от выполнения в момент создания бланка, а внутренняя позволяет избежать умножения в случае истинности условия. Попытайтесь удалить любую из этих пар скобок или заменить вызов рв на нейтральный.
#(вц,Факториал,5
#(оц,Факториал,(
#(рв,X,1,
1,
(#(ум,X,#(вц,Факториал,#(вч,X,1)))))))
#(сц,Факториал,X))'
Этот пример делает то же, что предыдущий - определяет функцию факториал и вычисляет 5!. Однако здесь используется то, что аргументы функции вычисляются до вычисления самой функции; это позволяет спрятать определение и сегментацию бланка Факториал внутрь его вызова. Отметим, что после аргумента 5 вызова Факториал не нужно ставить запятую, поскольку он всегда возвращает в качестве значения пустую цепочку.
ТЕМА. Напишите процессор Трака для вашей системы. Процессор должен реализовывать описанные выше алгоритм Трак и встроенные функции. Если в вашей системе имеется возможность хранения файлов, используйте ее для организации внешней памяти бланков. Блоки, записанные в каком-либо сеансе работы с процессором, должны быть доступны в последующих сеансах. Разумно будет включить в ваш процессор как можно больше внутренних средств отладки.
РЕКОМЕНДАЦИИ ИСПОЛНИТЕЛЮ. В каждой системе приняты свои соглашения относительно набора литер и способа завершения строки. Один из шагов алгоритма Трак выбрасывает из сканируемого текста незащищенные литеры возврата каретки, перевода строки и табуляции. Это позволяет спокойно вводить исходные данные, не думая о возможности случайного разбиения программы на несколько строк вследствие ограничений на длину строки физических устройств. Но выбрасывание этих литер означает также, что их следует явно указывать во входном потоке, чтобы мы могли при желании управлять форматом вывода программы. Так, например, если CR-LF обозначает последовательность литер "возврат каретки - перевод строки", то при вводе цепочки ОДИН CR-LF ДВА мы увидим на печати ОДИНДВА в одной строке, в то же время исходные данные ОДИН(CR-LF)ДВА приведут к печати слова ОДИН на одной строке, а ДВА - на следующей. Позаботьтесь о том, чтобы ваш процессор правильно работал в этой ситуации.
Описывая алгоритм, мы лихо проскочили вопрос об установке и поиске меток аргументов и функций в нейтральной цепочке. На самом деле весьма важно всегда иметь точный список функций и аргументов, в котором указан, в частности, порядок их появления. Проще всего добиться этого с помощью стека. Этим стеком распоряжается исключительно процессор. Каждый раз, когда алгоритм выполняет шаг 1, стек устанавливается в пустое состояние. При маркировке любого начала функции на стек помещается новый БЛОК ФУНКЦИИ. В блоке функции имеется основная часть постоянного вида, включающая, как минимум, положение в стеке ближайшего нижнего, блока функции, режим вызова данной функции, положение в нейтральной цепочке первой литеры функции, число аргументов функции, обработка которых начата, и число законченных аргументов и положение в нейтральной цепочке начала аргумента, который в данный момент сканируется. Выше постоянной части в стеке располагаются элементы, указывающие для каждого законченного аргумента его начало и конец. Часть этой информации может неявно присутствовать в других местах. Среди типичных ошибок реализации - неправильная работа с пустой цепочкой и потеря информации о функциях, расположенных в нижней части стека, при обработке вышележащих функций.
Память бланков точно так же требует большего внимания, чем ей уделялось в предшествующем изложении. Поскольку как имя, так и тело бланка представляют собой цепочки, имеет смысл хранить их вместе в некоторой разновидности памяти для цепочек. Необходимо также место, где хранились бы указатель бланка и метки сегментов; кроме того, нужно уметь находить бланки. В такой ситуации проще всего выделить достаточно большое ПРОСТРАНСТВО БЛАНКОВ и хранить бланки в виде связанного списка. У каждого бланка будет головная часть фиксированного размера; она будет включать указатель на следующий бланк, указатель бланка, начальную позицию и длину имени бланка, а также начало и длину тела. Имя и тело можно хранить сразу вслед за головной частью, а метку сегмента можно представлять некоторой парой литер, окружающих целое число (конечно, необходимо иметь какой-либо другой способ изобразить литеры метки как обычные литеры). Для выполнения поиска бланка можно пройти по списку бланков, а для исключения бланка можно удалить его из списка с помощью перестановки указателей, а затем передвинуть окружающие бланки, чтобы заполнить образовавшуюся дыру. Существуют и другие способы организации памяти бланков; каждому способу присущи свои достоинства и недостатки.
Распределение памяти для процессора также не простая задача. Потребность в памяти для любой из структур - нейтральной цепочки, активной цепочки, стека аргументов и памяти бланков - может превзойти любую заранее установленную границу. Если для этих структур выделяются фиксированные области памяти, то любая из них может переполниться, в то время как в остальных свободного пространства будет хоть отбавляй. Имеется стандартный путь решения этой проблемы. Рассмотрим сначала нейтральную и активную цепочки. Поскольку нейтральная цепочка естественно смотрится слева от активной, выделим им одну область памяти на двоих; в этой области нейтральная цепочка будет расти от левого края вправо, а активная цепочка, наоборот, от правого края влево. При таком способе действий переполнение памяти не наступит, пока активная и нейтральная цепочки не используют в сумме всю выделенную им память. Стек аргументов можно таким же образом объединить с памятью бланков; один из двух промежутков между объединенными парами можно использовать для временного хранения цепочек, переписываемых с одного места на другое.
Возможны дальнейшие усовершенствования. Выделим память для всех динамических структур в одной большой области, в которой разместим слева направо: нейтральную цепочку, растущую вправо, свободный промежуток, активную цепочку, растущую влево, без всякого промежутка стек аргументов, свободный промежуток и память бланков, растущую влево. Если теперь активная и нейтральная цепочки израсходуют все пространство, в то время как между стеком аргументов и памятью бланков еще что-то останется, то передвинем активную цепочку и стек аргументов как единое целое вправо на некоторое расстояние, передавая тем самым часть пространства из правого свободного промежутка в левый. Разумеется, тот же прием работает и в другую сторону, так что процессор не останется без памяти, пока ему будет откуда ее взять.
Обсуждая распределение памяти, мы считали, что нам удастся урвать большой аморфный кусок памяти, в котором можно хранить все, что нам будет угодно: литеры, указатели, целые числа, логические флажки и т.д. В языках программирования, по крайней мере в таких, как Паскаль или Алгол, это весьма затруднительно, если вообще возможно. Конечно, в языке ассемблера вся память аморфна, но платой за такую свободу обычно бывают ошибки в обращениях к памяти. Очень часто приходится выбирать между удобством и безопасностью; обычно находят какое-либо компромиссное решение. Вы неизбежно столкнетесь с этой проблемой при выборе языка программирования для реализации.
В вашем процессоре должен быть достаточный набор ИНСТРУМЕНТОВ АНАЛИЗА, так чтобы процессор вычислял, записывал и выдавал такие величины, как число выполнений каждого шага алгоритма и каждой встроенной функции, максимальная длина каждой внутренней области памяти, число переупаковок памяти из-за переполнений и число вызовов каждой внутренней подпрограммы. Такие инструменты решают три задачи. Во-первых, они служат средством отладки. Если между выдаваемыми числами существует какая-либо априорная зависимость и она не выполняется или если значения некоторых счетчиков не лезут ни в какие ворота, то, вероятно, это указывает на ошибку. Во-вторых, значения счетчиков помогут вам усовершенствовать именно те подпрограммы, которые затрачивают наибольшее время, и настроить параметры алгоритма распределения памяти. И наконец, значения счетчиков, оформленные подходящим образом и с необходимыми разъяснениями, помогут пользователю Трака в правильном и эффективном использовании процессора. Вероятно, значения счетчиков следует сообщать пользователю в конце каждого сеанса.
ИНСТРУМЕНТОВКА. На примере этой задачи можно еще раз изучить влияние языка на программирование. Если вы изберете язык высокого уровня типа Паскаля с его многочисленными мерами безопасности, то обнаружите, что большую часть процессора до абсурда легко закодировать, но за эту легкость, вероятно, придется заплатить потерей эффективности и трудностями при реализации распределения памяти. Если, напротив, остановитесь на языке ассемблера, то вполне может случиться, что ваша программа будет эффективной как по памяти, так и повремени, но она будет очень длинной и трудной для отладки, причем вам придется написать многие из тех подпрограмм, которые предоставляются другими языками программирования. Использование языков промежуточного уровня: XPL, BLISS или Фортрана - быть может, объединит преимущества (и, возможно, недостатки) двух крайних подходов. Не исключено также, что некоторые части программы придется написать на одном языке, а остальную программу - на другом. Как бы то ни было, в документации необходимо обосновать выбор языка и привести соображения, которые возникнут у вас по окончании работы.
ДЛИТЕЛЬНОСТЬ ИСПОЛНЕНИЯ. Для решения этой задачи в одиночку потребуется 7 недель, вдвоем - 4 недели, втроем - 3 недели.
РАЗВИТИЕ ТЕМЫ. Один очевидный способ расширить Трак - это допустить вызов бланка в виде функции с именем бланка а качестве первого аргумента, т.е. преобразовывать #(XYZ,...,... ...) в #(вц,XYZ,...,... ...). Если ввести правило, согласно которому телом неопределенного бланка считается пустая цепочка, то описанное выше преобразование автоматически обеспечивает пустое значение для неопределенной функции. Если, кроме того, просматривать бланки перед встроенными функциями, то пользователь сможет заменить какие-либо встроенные функции функциями, изготовленными специально для него.
Еще один очевидный способ расширения - добавление новых встроенных функций. Предлагаем два набора встроенных функций. Первый дает дополнительные удобства при работе с цепочками и литерами. Второй набор расширяет возможности ввода/вывода.
ОБРАБОТКА ЦЕПОЧЕК И ЛИТЕР
#(зм) "Запрос металитеры" (один аргумент). Значением этой функции является однолитерная цепочка, состоящая из текущей металитеры.
#(дц,A) "Длина цепочки" (два аргумента). Значением функции является длина цепочки A в виде десятичной цепочки. Длина пустой цепочки равняется нулю.
#(нл,C) "Номер литеры" (два аргумента). Значением функции является десятичная цепочка, дающая номер первой литеры аргумента C в наборе литер конкретной реализации. Если цепочка C пуста, то и значение функции пусто.
#(лн,D) "Литера по номеру" (два аргумента). Значением этой функции является цепочка из одной литеры, номер которой в наборе литер конкретной реализации задается арифметическим значением аргумента D. Если литеры, с таким номером не существует, то значение функции - пустая цепочка.
#(дс,N) "Диапазон сегментов" (два аргумента). Значение этой функции - десятичная цепочка, равная максимальному номеру метки сегмента в бланке, имя которого задано аргументом N. Если такого бланка нет или в нем нет меток сегментов, то значением функции будет нуль.
#(ио,Rl,R2,V) "Изменение основания" (четыре аргумента). Для вычисления значения этой функции находится арифметическое значение аргумента V в системе счисления с основанием R1, затем оно переводится в систему с основанием R2. Множество возможных цифр для всех оснований есть (в возрастающем порядке) 0, 1, ..., 9, A, B, ..., Z. Так, в двоичной системе используются цифры 0 и 1, в десятичной - от 0 до 9, в шестнадцатеричной - от 0 до F. Арифметическим значением цепочки в данной системе счисления считается наиболее длинная ее правая подцепочка, которая, возможно, начинается с + или -, а в остальном состоит только из цифр, допустимых в этой системе. Это такое же правило, как правило Трака для десятичных значений. Аргументы R1 и R2 задают систему счисления, указывая наибольшую допустимую цифру (например, 9 для десятичной системы, 1 для двоичной и F для шестнадцатеричной). Если любой из аргументов R1 или R2 не является одной литерой в диапазоне от 1 до Z, то значение функции пусто.
ВВОД/ВЫВОД
#(ст) "Стоп" (один аргумент). Эта функция с пустым значением вызывает немедленный выход из процессора Трака.
#(пв,F,Z) "Подключение ввода" (три аргумента). Эта функция с пустым значением подключает устройство ввода к файлу, имя которого задается аргументом F, и устанавливает указатель файла на первую запись файла. Если файл не может быть подключен, то значением функции является аргумент Z в активном режиме независимо от режима вызова функции. Любой последующий вызов функции чц приводит к тому, что устройство ввода читает цепочку из файла до ближайшей металитеры и передвигает указатель файла. Если аргумент F пуст, то вновь подключается стандартный файл ввода (ввод с клавиатуры в интерактивных системах).
#(пв,F,Z) "Подключение вывода" (два аргумента). Эта функция с пустым значение подключает устройство вывода к файлу F, и если такого файла еще нет, то создает его. Если аргумент F пуст, функция возвращает вывод на стандартное устройство вывода (на экран терминала в интерактивных системах).
#(уу, N) "Установка указателя" (два аргумента). Эта функция с пустым значением устанавливает указатель файла ввода на запись, расположенную после N-1 металитер. Если это условие не определяет запись в файле или если файлом служит ввод с клавиатуры, то выполнение функции ничего не меняет.
#(чу) "Чтение указателя" (один аргумент). Функция выдает в качестве значения десятичную цепочку, представляющую текущее состояние указателя файла ввода. Если файл ввода подключен к клавиатуре, то значение функции пусто.
#(чц,Z) "Чтение цепочки" (два аргумента). Эта функция есть видоизменение ранее определенной функции чц. Если из текущего файла ввода невозможен ввод, то значением этой функции является аргумент Z в активном режиме независимо от, режима вызова функции.
ЛИТЕРАТУРА
Муэрс (Mooers С.N.). Computer Software and Copyright, Computing Surveys, 7, I, pp.45-72, 1975.
Хотя эта статья не посвящена непосредственно Траку, ее тематика порождена, по крайней мере отчасти, опасениями за чистоту Трака. Муэрс сформулировал если не закон, то во всяком случае четкую позицию в отношении к вопросам защиты программ.
Муэрс (Mooers С.N.). How Some Fundamental Problems are Treated in the Design of the TRAC Language. In Symbol Manipulation Languages and Techniques, edited by D.G.Bobrow. North-Holland Publishing Co., Amsterdam, pp.178-190, 1968.
В этой работе Муэрс обсуждает некоторые решения, принятые при проектировании Трака. Трак сравнивается с другими языками для аналогичных целей, в частности с Лиспом. Общефилософские принципы, которые вы почерпнете из этой статьи, послужат отличными дрожжами для закваски познаний по основам Трака.
Нельсон (Nelson Т.Н.). Computer Lib or Dream Machines. Hugo's Book Service, Chicago, IL, 1974.
Всемирный каталог познаний по компьютерам. Эта книга - увлекательный сборник. Она даже имеет два разных названия, в зависимости от того, откуда вы начнете читать ее - с начала или с конца. Нельсон считает, чго Трак - предвестник будущих языков, и дает прекрасное введение в него.
Муэрс (Mooers С.N.). TRAC, A Procedure-Describing Language for the Reactive Typewriter. CACM, 9, 3, pp.215-219, 1966.
Стрейчи (Strachey С.). A General Purpose Macrogenerator. Comput. J. 8, 3, pp.225-241, 1966.
В статье Муэрса Трак описывается с точки зрения его использования. Изложение проблем во многом повторяет предыдущую статью, но во встроенные функции внесены некоторые очевидные усовершенствования. Стрейчи в своей статье описывает очень похожий язык, в котором вместо встроенных функций имеются более мощные, чем в Траке, средства определения функций, и приводит листинг модельного процессора. Две эти статьи были написаны независимо и представляют собой яркий образец проявления исторической необходимости.
Браун (Brown P.J.). Macro Processing and Techniques for Portable Software Wiley, New York, NY, 1975. [Имеется перевод: Браун П. Макропроцессоры и мобильность программного обеспечения.- М.: Мир, 1977]
Вегнер (Wegner P.). Programming Languages, Information Structures, and MaMachine Organization. McGraw-Hill, New York, NY, 1978.
И Браун, и Вегнер с позиций общей информатики обсуждают Трак наряду с другими макропроцессорами.
ПРИМЕРЫ
Следующие примеры помогут вам почувствовать некоторые возможности языка Трак. Не думайте, однако, что эти конкретные примеры иллюстрируют все возможности каких-либо функций.
#(оц,AA,Кот)'
#(оц,BB,(#(вц,AA)))'
#(пц,(#(вц,BB)))'
#(пц,##(вц,BB))'
#(пц,#(вц,ВВ))'
Выполнение первой строки из этого ряда программ (заметьте, что каждая строка оканчивается металитерой - апострофом) приводит к запоминанию бланка с именем AA и телом Кот и к печати пустой цепочки. Вторая строка аналогичным образом создает бланк с телом #(вц,AA) и именем BB и печатает пустую цепочку. Дальше начинается самое интересное. Функция пц в третьей строке печатает #(вц,BB), поскольку внутренняя функция защищена скобками; та же функция в четвертой строке печатает #(вц,AA), поскольку внутренняя функция - нейтральная и, наконец, при выполнении пятой строки печатается Кот.
#(уо,#(си,(,)))'
Эта программа делает точно то же, что и вызов #(ув). Аргументами уо должны быть имена бланков, и си генерирует список имен, разделенных запятыми.
#(оц,Факториал,(#(рв,X,1,1,(#(ум,X,#(вц,Факториал,#(вч,X,1)))))))'
#(сц,Факториал,X)'
#(вц,Факториал,5)'
В этих трех строках стандартным рекурсивным способом определяется функция факториал, цепочка Факториал сегментируется по аргументу X и затем вычисляется значение 5!. Необходимы обе пары защитных скобок; внешняя защищает рв от выполнения в момент создания бланка, а внутренняя позволяет избежать умножения в случае истинности условия. Попытайтесь удалить любую из этих пар скобок или заменить вызов рв на нейтральный.
#(вц,Факториал,5
#(оц,Факториал,(
#(рв,X,1,
1,
(#(ум,X,#(вц,Факториал,#(вч,X,1)))))))
#(сц,Факториал,X))'
Этот пример делает то же, что предыдущий - определяет функцию факториал и вычисляет 5!. Однако здесь используется то, что аргументы функции вычисляются до вычисления самой функции; это позволяет спрятать определение и сегментацию бланка Факториал внутрь его вызова. Отметим, что после аргумента 5 вызова Факториал не нужно ставить запятую, поскольку он всегда возвращает в качестве значения пустую цепочку.
ТЕМА. Напишите процессор Трака для вашей системы. Процессор должен реализовывать описанные выше алгоритм Трак и встроенные функции. Если в вашей системе имеется возможность хранения файлов, используйте ее для организации внешней памяти бланков. Блоки, записанные в каком-либо сеансе работы с процессором, должны быть доступны в последующих сеансах. Разумно будет включить в ваш процессор как можно больше внутренних средств отладки.
РЕКОМЕНДАЦИИ ИСПОЛНИТЕЛЮ. В каждой системе приняты свои соглашения относительно набора литер и способа завершения строки. Один из шагов алгоритма Трак выбрасывает из сканируемого текста незащищенные литеры возврата каретки, перевода строки и табуляции. Это позволяет спокойно вводить исходные данные, не думая о возможности случайного разбиения программы на несколько строк вследствие ограничений на длину строки физических устройств. Но выбрасывание этих литер означает также, что их следует явно указывать во входном потоке, чтобы мы могли при желании управлять форматом вывода программы. Так, например, если CR-LF обозначает последовательность литер "возврат каретки - перевод строки", то при вводе цепочки ОДИН CR-LF ДВА мы увидим на печати ОДИНДВА в одной строке, в то же время исходные данные ОДИН(CR-LF)ДВА приведут к печати слова ОДИН на одной строке, а ДВА - на следующей. Позаботьтесь о том, чтобы ваш процессор правильно работал в этой ситуации.
Описывая алгоритм, мы лихо проскочили вопрос об установке и поиске меток аргументов и функций в нейтральной цепочке. На самом деле весьма важно всегда иметь точный список функций и аргументов, в котором указан, в частности, порядок их появления. Проще всего добиться этого с помощью стека. Этим стеком распоряжается исключительно процессор. Каждый раз, когда алгоритм выполняет шаг 1, стек устанавливается в пустое состояние. При маркировке любого начала функции на стек помещается новый БЛОК ФУНКЦИИ. В блоке функции имеется основная часть постоянного вида, включающая, как минимум, положение в стеке ближайшего нижнего, блока функции, режим вызова данной функции, положение в нейтральной цепочке первой литеры функции, число аргументов функции, обработка которых начата, и число законченных аргументов и положение в нейтральной цепочке начала аргумента, который в данный момент сканируется. Выше постоянной части в стеке располагаются элементы, указывающие для каждого законченного аргумента его начало и конец. Часть этой информации может неявно присутствовать в других местах. Среди типичных ошибок реализации - неправильная работа с пустой цепочкой и потеря информации о функциях, расположенных в нижней части стека, при обработке вышележащих функций.
Память бланков точно так же требует большего внимания, чем ей уделялось в предшествующем изложении. Поскольку как имя, так и тело бланка представляют собой цепочки, имеет смысл хранить их вместе в некоторой разновидности памяти для цепочек. Необходимо также место, где хранились бы указатель бланка и метки сегментов; кроме того, нужно уметь находить бланки. В такой ситуации проще всего выделить достаточно большое ПРОСТРАНСТВО БЛАНКОВ и хранить бланки в виде связанного списка. У каждого бланка будет головная часть фиксированного размера; она будет включать указатель на следующий бланк, указатель бланка, начальную позицию и длину имени бланка, а также начало и длину тела. Имя и тело можно хранить сразу вслед за головной частью, а метку сегмента можно представлять некоторой парой литер, окружающих целое число (конечно, необходимо иметь какой-либо другой способ изобразить литеры метки как обычные литеры). Для выполнения поиска бланка можно пройти по списку бланков, а для исключения бланка можно удалить его из списка с помощью перестановки указателей, а затем передвинуть окружающие бланки, чтобы заполнить образовавшуюся дыру. Существуют и другие способы организации памяти бланков; каждому способу присущи свои достоинства и недостатки.
Распределение памяти для процессора также не простая задача. Потребность в памяти для любой из структур - нейтральной цепочки, активной цепочки, стека аргументов и памяти бланков - может превзойти любую заранее установленную границу. Если для этих структур выделяются фиксированные области памяти, то любая из них может переполниться, в то время как в остальных свободного пространства будет хоть отбавляй. Имеется стандартный путь решения этой проблемы. Рассмотрим сначала нейтральную и активную цепочки. Поскольку нейтральная цепочка естественно смотрится слева от активной, выделим им одну область памяти на двоих; в этой области нейтральная цепочка будет расти от левого края вправо, а активная цепочка, наоборот, от правого края влево. При таком способе действий переполнение памяти не наступит, пока активная и нейтральная цепочки не используют в сумме всю выделенную им память. Стек аргументов можно таким же образом объединить с памятью бланков; один из двух промежутков между объединенными парами можно использовать для временного хранения цепочек, переписываемых с одного места на другое.
Возможны дальнейшие усовершенствования. Выделим память для всех динамических структур в одной большой области, в которой разместим слева направо: нейтральную цепочку, растущую вправо, свободный промежуток, активную цепочку, растущую влево, без всякого промежутка стек аргументов, свободный промежуток и память бланков, растущую влево. Если теперь активная и нейтральная цепочки израсходуют все пространство, в то время как между стеком аргументов и памятью бланков еще что-то останется, то передвинем активную цепочку и стек аргументов как единое целое вправо на некоторое расстояние, передавая тем самым часть пространства из правого свободного промежутка в левый. Разумеется, тот же прием работает и в другую сторону, так что процессор не останется без памяти, пока ему будет откуда ее взять.
Обсуждая распределение памяти, мы считали, что нам удастся урвать большой аморфный кусок памяти, в котором можно хранить все, что нам будет угодно: литеры, указатели, целые числа, логические флажки и т.д. В языках программирования, по крайней мере в таких, как Паскаль или Алгол, это весьма затруднительно, если вообще возможно. Конечно, в языке ассемблера вся память аморфна, но платой за такую свободу обычно бывают ошибки в обращениях к памяти. Очень часто приходится выбирать между удобством и безопасностью; обычно находят какое-либо компромиссное решение. Вы неизбежно столкнетесь с этой проблемой при выборе языка программирования для реализации.
В вашем процессоре должен быть достаточный набор ИНСТРУМЕНТОВ АНАЛИЗА, так чтобы процессор вычислял, записывал и выдавал такие величины, как число выполнений каждого шага алгоритма и каждой встроенной функции, максимальная длина каждой внутренней области памяти, число переупаковок памяти из-за переполнений и число вызовов каждой внутренней подпрограммы. Такие инструменты решают три задачи. Во-первых, они служат средством отладки. Если между выдаваемыми числами существует какая-либо априорная зависимость и она не выполняется или если значения некоторых счетчиков не лезут ни в какие ворота, то, вероятно, это указывает на ошибку. Во-вторых, значения счетчиков помогут вам усовершенствовать именно те подпрограммы, которые затрачивают наибольшее время, и настроить параметры алгоритма распределения памяти. И наконец, значения счетчиков, оформленные подходящим образом и с необходимыми разъяснениями, помогут пользователю Трака в правильном и эффективном использовании процессора. Вероятно, значения счетчиков следует сообщать пользователю в конце каждого сеанса.
ИНСТРУМЕНТОВКА. На примере этой задачи можно еще раз изучить влияние языка на программирование. Если вы изберете язык высокого уровня типа Паскаля с его многочисленными мерами безопасности, то обнаружите, что большую часть процессора до абсурда легко закодировать, но за эту легкость, вероятно, придется заплатить потерей эффективности и трудностями при реализации распределения памяти. Если, напротив, остановитесь на языке ассемблера, то вполне может случиться, что ваша программа будет эффективной как по памяти, так и повремени, но она будет очень длинной и трудной для отладки, причем вам придется написать многие из тех подпрограмм, которые предоставляются другими языками программирования. Использование языков промежуточного уровня: XPL, BLISS или Фортрана - быть может, объединит преимущества (и, возможно, недостатки) двух крайних подходов. Не исключено также, что некоторые части программы придется написать на одном языке, а остальную программу - на другом. Как бы то ни было, в документации необходимо обосновать выбор языка и привести соображения, которые возникнут у вас по окончании работы.
ДЛИТЕЛЬНОСТЬ ИСПОЛНЕНИЯ. Для решения этой задачи в одиночку потребуется 7 недель, вдвоем - 4 недели, втроем - 3 недели.
РАЗВИТИЕ ТЕМЫ. Один очевидный способ расширить Трак - это допустить вызов бланка в виде функции с именем бланка а качестве первого аргумента, т.е. преобразовывать #(XYZ,...,... ...) в #(вц,XYZ,...,... ...). Если ввести правило, согласно которому телом неопределенного бланка считается пустая цепочка, то описанное выше преобразование автоматически обеспечивает пустое значение для неопределенной функции. Если, кроме того, просматривать бланки перед встроенными функциями, то пользователь сможет заменить какие-либо встроенные функции функциями, изготовленными специально для него.
Еще один очевидный способ расширения - добавление новых встроенных функций. Предлагаем два набора встроенных функций. Первый дает дополнительные удобства при работе с цепочками и литерами. Второй набор расширяет возможности ввода/вывода.
ОБРАБОТКА ЦЕПОЧЕК И ЛИТЕР
#(зм) "Запрос металитеры" (один аргумент). Значением этой функции является однолитерная цепочка, состоящая из текущей металитеры.
#(дц,A) "Длина цепочки" (два аргумента). Значением функции является длина цепочки A в виде десятичной цепочки. Длина пустой цепочки равняется нулю.
#(нл,C) "Номер литеры" (два аргумента). Значением функции является десятичная цепочка, дающая номер первой литеры аргумента C в наборе литер конкретной реализации. Если цепочка C пуста, то и значение функции пусто.
#(лн,D) "Литера по номеру" (два аргумента). Значением этой функции является цепочка из одной литеры, номер которой в наборе литер конкретной реализации задается арифметическим значением аргумента D. Если литеры, с таким номером не существует, то значение функции - пустая цепочка.
#(дс,N) "Диапазон сегментов" (два аргумента). Значение этой функции - десятичная цепочка, равная максимальному номеру метки сегмента в бланке, имя которого задано аргументом N. Если такого бланка нет или в нем нет меток сегментов, то значением функции будет нуль.
#(ио,Rl,R2,V) "Изменение основания" (четыре аргумента). Для вычисления значения этой функции находится арифметическое значение аргумента V в системе счисления с основанием R1, затем оно переводится в систему с основанием R2. Множество возможных цифр для всех оснований есть (в возрастающем порядке) 0, 1, ..., 9, A, B, ..., Z. Так, в двоичной системе используются цифры 0 и 1, в десятичной - от 0 до 9, в шестнадцатеричной - от 0 до F. Арифметическим значением цепочки в данной системе счисления считается наиболее длинная ее правая подцепочка, которая, возможно, начинается с + или -, а в остальном состоит только из цифр, допустимых в этой системе. Это такое же правило, как правило Трака для десятичных значений. Аргументы R1 и R2 задают систему счисления, указывая наибольшую допустимую цифру (например, 9 для десятичной системы, 1 для двоичной и F для шестнадцатеричной). Если любой из аргументов R1 или R2 не является одной литерой в диапазоне от 1 до Z, то значение функции пусто.
ВВОД/ВЫВОД
#(ст) "Стоп" (один аргумент). Эта функция с пустым значением вызывает немедленный выход из процессора Трака.
#(пв,F,Z) "Подключение ввода" (три аргумента). Эта функция с пустым значением подключает устройство ввода к файлу, имя которого задается аргументом F, и устанавливает указатель файла на первую запись файла. Если файл не может быть подключен, то значением функции является аргумент Z в активном режиме независимо от режима вызова функции. Любой последующий вызов функции чц приводит к тому, что устройство ввода читает цепочку из файла до ближайшей металитеры и передвигает указатель файла. Если аргумент F пуст, то вновь подключается стандартный файл ввода (ввод с клавиатуры в интерактивных системах).
#(пв,F,Z) "Подключение вывода" (два аргумента). Эта функция с пустым значение подключает устройство вывода к файлу F, и если такого файла еще нет, то создает его. Если аргумент F пуст, функция возвращает вывод на стандартное устройство вывода (на экран терминала в интерактивных системах).
#(уу, N) "Установка указателя" (два аргумента). Эта функция с пустым значением устанавливает указатель файла ввода на запись, расположенную после N-1 металитер. Если это условие не определяет запись в файле или если файлом служит ввод с клавиатуры, то выполнение функции ничего не меняет.
#(чу) "Чтение указателя" (один аргумент). Функция выдает в качестве значения десятичную цепочку, представляющую текущее состояние указателя файла ввода. Если файл ввода подключен к клавиатуре, то значение функции пусто.
#(чц,Z) "Чтение цепочки" (два аргумента). Эта функция есть видоизменение ранее определенной функции чц. Если из текущего файла ввода невозможен ввод, то значением этой функции является аргумент Z в активном режиме независимо от, режима вызова функции.
ЛИТЕРАТУРА
Муэрс (Mooers С.N.). Computer Software and Copyright, Computing Surveys, 7, I, pp.45-72, 1975.
Хотя эта статья не посвящена непосредственно Траку, ее тематика порождена, по крайней мере отчасти, опасениями за чистоту Трака. Муэрс сформулировал если не закон, то во всяком случае четкую позицию в отношении к вопросам защиты программ.
Муэрс (Mooers С.N.). How Some Fundamental Problems are Treated in the Design of the TRAC Language. In Symbol Manipulation Languages and Techniques, edited by D.G.Bobrow. North-Holland Publishing Co., Amsterdam, pp.178-190, 1968.
В этой работе Муэрс обсуждает некоторые решения, принятые при проектировании Трака. Трак сравнивается с другими языками для аналогичных целей, в частности с Лиспом. Общефилософские принципы, которые вы почерпнете из этой статьи, послужат отличными дрожжами для закваски познаний по основам Трака.
Нельсон (Nelson Т.Н.). Computer Lib or Dream Machines. Hugo's Book Service, Chicago, IL, 1974.
Всемирный каталог познаний по компьютерам. Эта книга - увлекательный сборник. Она даже имеет два разных названия, в зависимости от того, откуда вы начнете читать ее - с начала или с конца. Нельсон считает, чго Трак - предвестник будущих языков, и дает прекрасное введение в него.
Муэрс (Mooers С.N.). TRAC, A Procedure-Describing Language for the Reactive Typewriter. CACM, 9, 3, pp.215-219, 1966.
Стрейчи (Strachey С.). A General Purpose Macrogenerator. Comput. J. 8, 3, pp.225-241, 1966.
В статье Муэрса Трак описывается с точки зрения его использования. Изложение проблем во многом повторяет предыдущую статью, но во встроенные функции внесены некоторые очевидные усовершенствования. Стрейчи в своей статье описывает очень похожий язык, в котором вместо встроенных функций имеются более мощные, чем в Траке, средства определения функций, и приводит листинг модельного процессора. Две эти статьи были написаны независимо и представляют собой яркий образец проявления исторической необходимости.
Браун (Brown P.J.). Macro Processing and Techniques for Portable Software Wiley, New York, NY, 1975. [Имеется перевод: Браун П. Макропроцессоры и мобильность программного обеспечения.- М.: Мир, 1977]
Вегнер (Wegner P.). Programming Languages, Information Structures, and MaMachine Organization. McGraw-Hill, New York, NY, 1978.
И Браун, и Вегнер с позиций общей информатики обсуждают Трак наряду с другими макропроцессорами.
Gudleifr- Admin
- Сообщения : 3252
Дата регистрации : 2017-03-29
Re: Уэзерелл. Этюды для программистов. 1982
автор Gudleifr Чт Мар 04, 2021 11:34 am
РЕШЕНИЯ
Ниже в качестве решений представлены законченные программы, однако это далеко не все, что должны сделать студенты. На примере конкретных задач мы обсуждаем искусство программирования, в частности некоторые полезные нюансы, о которых умалчивают многие руководства. Студентам необходимо представить больше внешней документации, больше выдач, больше подтверждений правильности программ. Заметим также, что мы не навязываем другим выбранные нами языки.
29
КРАСЬТЕ С НАМИ,
ИЛИ...
ПОЛНОЕ РЕШЕНИЕ ЗАДАЧИ
В данной главе в полном виде приводится программа для задачи о раскраске карты (см. гл.3). Читатели, которым довелось испытать это на собственной шкуре, знают как трудно описывать программу, излагая алгоритм прозрачно и просто. Когда решение головоломки рассказано, обычной реакцией бывает: "Как я не догадался!" вместо: "Как здорово!" Ну а программа - это, конечно, тоже решение головоломки. Из описаний всегда устраняют дух исследования, историю неудавшихся подходов и отступлений, упоминание о глупых ошибках, сбивавших с правильного пути. Если бы мы попытались полностью изложить процесс разработки программы, вы бы не знали, плакать вам или смеяться над тупостью автора. Так что лучше пойдем уже проторенной дорогой от задачи к решению, лишь изредка поглядывая по сторонам [Для усиления аналогии между трудом писателя и программиста отметим, что данная глава переписывалась не раз и не два].
По условию задачи требуется раскрасить карту или неориентированный граф в минимальное число цветов так, чтобы никаких два СОСЕДНИХ региона (никакие две СМЕЖНЫЕ вершины) не были одного цвета. Хотя в данный момент не требуется точно специфицировать формат исходной и выводимой информации, а также внутреннее представление данных, можно сообразить, какие свойства графа будут существенны для любой программы. Очевидно, нужно знать число вершин графа, уметь регулярным образом обращаться к вершинам, уметь раскрашивать вершины и узнавать их цвет, определять, являются ли две вершины смежными, и, наконец, нужно уметь порождать много различных цветов. Проще всего удовлетворить перечисленным требованиям, обозначив вершины натуральными числами 1, 2, ..., n, где n - общее количество вершин. Аналогично и цвета обозначим натуральными числами (ясно, что при этом в нашем распоряжении окажется много цветов). Вопрос о конкретном способе определения смежности вершин целесообразно отложить.
Раскрашивать можно двумя способами: либо предположить, что каждая вершина уже раскрашена в свой цвет и попытаться избавиться от нескольких цветов, либо предположить, что ни одна вершина еще не раскрашена, и пытаться добавлять как можно меньше цветов. Однако на любом пути мы сталкиваемся с неприятным теоретическим результатом (или с отсутствием оного): никто не знает, как раскрасить карту, не перебрав для худшего случая все возможные раскраски с минимальным числом цветов. Большинство специалистов считает, что нет более быстрого метода раскрашивания карты, чем перебор всех вариантов. Иными словами, какой бы умной ни была ваша программа и как быстро она ни работала в среднем, найдутся карты с n вершинами, требующие k цветов, на раскраску которых программа затратит порядка k**n единиц времени. Возможно, кому-нибудь посчастливится найти алгоритм, и для худшего случая оказывавшийся не столь расточительным, но теоретики считают это маловероятным. Так что давайте займемся простой быстрой программой, а не суперсложной, которая вряд ли будет лучше [Данная программа иллюстрирует важность теоретической информатики для программистов-практиков. Многие другие распространенные КОМБИНАТОРНЫЕ ЗАДАЧИ, среди которых наиболее известна ЗАДАЧА О КОММИВОЯЖЕРЕ, в наихудшем случае требуют для своего решения такой же крайней расточительности, как и раскрашивание карты. Но довольно часто небольшое изменение условия делает возможным очень эффективное решение. Программисту не нужно знать все задачи и их решения, однако он должен узнавать трудные задачи и обращаться за решениями к литературе или специалистам. Между прочим, если не требуется ОПТИМАЛЬНОЕ, МИНИМАЛЬНОЕ, МАКСИМАЛЬНОЕ или ТОЧНОЕ решение, целесообразно испробовать имеющиеся для многих задач эвристики, позволяющие быстро получить хорошие приближения].
Предлагаемое решение основано наблюдении, что если некоторый подграф нельзя раскрасить в k цветов, то и весь граф, очевидно, тоже нельзя раскрасить в k цветов. На каждом шаге нашего алгоритма мы пытаемся добавить к уже раскрашенному подграфу еще одну вершину. Если сделать это не удастся, текущий раскрашенный подграф перекрашивается всеми возможными способами с использованием тех же цветов. Если новую вершину добавить все же нельзя, число цветов увеличивается на единицу, поскольку найден подграф, не раскрашиваемый выделенными цветами. В описании алгоритма предполагается, что есть вектор ЦВЕТ, содержащий цвета, приписанные каждой вершине. Логическая функция СВЯЗЬ позволяет узнать, связана ли вершина i с вершиной j.
АЛГОРИТМ РАСКРАСКИ ГРАФА
1. (Начальная установка). Предположим, что в графе имеется ЧИСЛОВЕРШИН вершин, что переменная СТАРШИЙЦВЕТ содержит номер старшего из уже использованных цветов, а нуль показывает, что вершина еще не наделена цветом. Для всех вершин n установить ЦВЕТ[n] равным нулю (т. е. сделать все вершины нераскрашенными). Установить СТАРШИЙЦВЕТ равным нулю, а переменную ТЕКУЩАЯВЕРШИНА равной единице.
2. (Основной цикл). Пока ТЕКУЩАЯВЕРШИНА не превзойдет ЧИСЛОВЕРШИН, выполнять шаги с 3-го по 7-й. Этим шагом начинается цикл, который повторяется, пока не будут раскрашены все вершины. Перед началом каждого прохождения цикла все вершины от 1 до ТЕКУЩАЯВЕРШИНА - 1 правильно раскрашены в СТАРШИЙЦВЕТ цветов.
3. (Подготовка одного узла). Увеличить ЦВЕТ[ТЕКУЩАЯВЕРШИНА] на единицу. Установить булеву переменную ФЛАГЦИКЛА равной значению отношения ЦВЕТ[ТЕКУЩАЯВЕРШИНА] <= СТАРШИЙЦВЕТ. Теперь рассматриваемая вершина имеет ненулевой цвет, и необходимо проверить, совместима ли ТЕКУЩАЯВЕРШИНА со своими соседями. Заметьте, что впервые добавляемая вершина всегда имеет нулевой цвет. Прибавляя единицу к нулю, мы наделяем вершину допустимым цветом. Пока ФЛАГЦИКЛА имеет значение ИСТИНА, выполнять шаги 4 и 5.
4. (Проверка цвета смежных вершин). Присвоить переменной ФЛАГЦИКЛА значение ЛОЖЬ и установить i равным единице. Пока i меньше, чем ТЕКУЩАЯВЕРШИНА, выполнять шаг 5.
5. (Проверка цвета каждого соседа). Если вершина i и ТЕКУЩАЯВЕРШИНА связаны (т.е. если связь (i, ТЕКУЩАЯВЕРШИНА) имеет значение ИСТИНА) и если ЦВЕТ[i] и ЦВЕТ[ТЕКУЩАЯВЕРШИНА] равны, значит, текущаявершина имеет недопустимый цвет. В этом случае установить значение i равным ТЕКУЩАЯВЕРШИНА, чтобы прервать цикл, начинающийся в шаге 4, увеличить ЦВЕТ[ТЕКУЩАЯВЕРШИНА] на единицу чтобы попробовать следующий цвет, и установить значение ФЛАГЦИКЛА равным значению отношения ЦВЕТ[ТЕКУЩАЯЕЕРШИНА] <= СТАРШИЙЦВЕТ. В противном случае просто увеличить i на единицу, чтобы проверить следующего соседа. Заметьте, что последнее присваивание переменной ФЛАГЦИКЛА перекроет присваивание в шаге 4, но может установить переменную ФЛАГЦИКЛА равной значению ЛОЖЬ. Далее, если начинающийся в шаге 4 цикл завершается нормально (т.е. без насильственного присваивания переменной ТЕКУЩАЯВЕРШИНА значения i), произойдет выход из цикла, начинающегося в шаге 3. Важно, чтобы при проверке допустимости раскраски использовались лишь вершины, номера которых строго меньше, чем ТЕКУЩАЯВЕРШИНА, поскольку вершины с большими номерами еще не раскрашены.
6. (Продвинуться или вернуться?) Если ТЕКУЩАЯВЕРШИНА получила допустимый цвет, мы хотим перейти к следующей вершине; в противном случае необходимо отступить. Поэтому, если ЦВЕТ[ТЕКУЩАЯВЕРШИНА] > СТАРШИЙЦВЕТ, установить ЦВЕТ[ТЕКУЩАЯВЕРШИНА] равным нулю и уменьшить значение ТЕКУЩАЯВЕРШИНА на единицу; в противном случае увеличить значение ТЕКУЩАЯВЕРШИНА на единицу. Заметьте, что цвета вершин с номерами большими, чем ТЕКУЩАЯВЕРШИНА, по-прежнему нулевые и что, когда мы возвращаемся к уже раскрашивавшейся вершине, мы продолжаем продвигать ее цвет со значения, оставшегося от предыдущей обработки.
7. (Добавление цвета, если это необходимо). Если ТЕКУЩАЯВЕРШИНА нулевая, увеличить СТАРШИЙЦВЕТ на единицу и установить значение ТЕКУЩАЯВЕРШИНА равным единице. Если мы вернулись к самому началу, число цветов необходимо увеличить.
Легко видеть, что данный алгоритм должен завершиться. В крайнем случае он остановится, когда все вершины получат разные цвета. Также достаточно ясно, что перед началом каждого прохождения основного цикла все вершины от первой до (ТЕКУЩАЯВЕРШИНА - 1) имеют допустимую раскраску. Чуть менее очевидно, что СТАРШИЙЦВЕТ увеличивается только тогда, когда невозможно раскрасить некий начальный подграф выделенным числом цветов. Удостовериться в этом вам помогут эксперименты на небольших графах. Заметьте, что алгоритм правильно работает для пустого графа, для графов, все вершины которых изолированы, и для графов, все вершины которых связаны.
РЕАЛИЗАЦИЯ
В нашей реализации мы используем Фортран. Ясно, что Фортран - очень бедный язык, с недостаточными возможностями определения данных и управления последовательностью действий. Однако мы выбрали его как раз для того, чтобы показать, что даже на неудобном языке можно написать хорошо структурированную, ясную программу. Теоретически каждую программу можно было бы написать на более новом, более выразительном языке; на практике большинству программистов время от времени приходится работать на архаичном языке, но плохие инструменты не могут служить оправданием для плохого программирования.
Логическую функцию СВЯЗЬ на Фортране можно представить двумерным логическим массивом, в котором (i,j)-й элемент имеет значение ИСТИНА тогда и только тогда, когда вершина i связана с вершиной j. Первый элемент ввода - это запись с количеством вершин раскрашиваемого графа. Затем читаются наборы записей, где каждый набор описывает связи одной вершины. Первая запись набора содержит номер вершины и количество ее соседей; в оставшихся записях в произвольном порядке перечисляются соседи. Признаком конца исходных данных служит нулевой номер вершины. Вершины можно описывать в произвольном порядке, а описание одной вершины можно разбивать на несколько частей. Когда вершина i связывается с вершиной j, вершина j автоматически связывается с вершиной i. Единственными возможными ошибками являются выход номера вершины за допустимые границы и попытка связать вершину с ней самой. Ниже воспроизводится реальная программа.






Исходные данные взяты с рис.1 из гл.3. Штаты перенумерованы сверху вниз; столбцы упорядочены слева направо. В каждой головной перфокарте справа присутствует название штата; вследствие заданного формата существенны только первые восемь литер карты. Для экономии места в книге данные разбиты на две колонки, но в остальном они точно соответствуют требованиям программы.

Выдача выглядит наилучшим образом, если ее напечатать на АЦПУ и повесить на стену. Пропорции приведенной в книге выдачи несколько нарушают симметрию. Заметьте, что горизонтальная печать решения экономит много бумаги, без всякой потери информации. Первоначально мы хотели напечатать номера и цвета вершин вертикально, что делается несколько проще, но выдача при этом получается весьма неряшливой.

ЗАМЕЧАНИЯ ПО ПРОГРАММЕ
Строки 1-19. Заголовок программы служит тем же целям, что и аннотация в научной статье. Вне зависимости от того, велика или мала программа, в ее начале должна присутствовать такого рода информация. В частности, в программе обязательна ссылка на соответствующую внешнюю документацию.
Строки 22-26. Если бы программа была побольше, перед определением данных следовало бы поместить больше материала по алгоритмическим вопросам. В нашем же случае тексту программы предшествует полный словарь. Поскольку размеры модулей не должны превышать нескольких страниц, мы предпочли толковый словарь, в котором переменные упоминаются группами в соответствии со своей ролью, важностью и местом употребления. Очевидно, количество пояснений в словаре зависит от других комментариев, но ни одна переменная не должна быть выпущена. Мы пытались сделать шести литерные имена мнемоничными, однако нелегко бороться против одного из глупейших фортрановских правил.
Строки 62-89. Все переменные продекларированы, хотя в Фортране декларации не обязательны. Во-первых, лучше перестраховаться, а во-вторых, лучше увериться, что читающий программу точно знает наши намерения. Комментарии в строках 62-65 поясняют, почему мы отклоняемся от стандарта: к этому нас вынуждает компилятор; точно указаны изменения, которые могут потребоваться при выполнении программы на другой вычислительной установке. Во вводе/выводе использованы переменные номера каналов, так что если программа переносится на другую установку с другими соглашениями о номерах, для налаживания работы ввода/вывода потребуется только одно изменение.
Строки 92-98. Начиная с этого места перемежаются абзацы комментариев на естественном языке и абзацы инструкций на Фортране. Не давайте комментарии слишком часто, иначе будет трудно уследить за порядком выполнения программы. Разумеется, ничто не может оправдать недостаток комментариев. В нашей программе 145 строк комментариев и 157 строк с инструкциями на Фортране. По общему правилу комментарии пишутся перед соответствующими инструкциями.
Строки 105-109. Помечать следует только инструкции CONTINUE и FORMAT. В Фортран-программе всегда много меток, и при отладке часто приходится перемещать их. Не накликайте беды, помечая самостоятельные инструкции, при перемещении которых легко ошибиться. По тем же причинам в одной строке закрывайте только один DO-цикл.
Строки 110-115. Проверка исходных данных - одновременно одна из самых скучных и самых важных обязанностей программы. Не доверяйте ничьим данным, даже своим собственным. Обратите внимание на инверсию смысла логических проверок в условных инструкциях. Подобная инверсия - обычное для Фортрана дело. Трудно выработать твердую схему для ступенчатой записи условных инструкций (ввиду отсутствия else), но имеющиеся в программе примеры показывают возможные варианты.
Строки 139-151. Метка 65 демонстрирует целесообразность расположения меток в порядке возрастания, с большим постоянным шагом. Проверка исходных данных, расположенная непосредственно перед меткой 65, добавлена после того, как при подготовке данных была допущена ошибка. Когда метки упорядочены, вставка дополнительных инструкций не вызывает затруднений. Обратите внимание также на использование переменной J. Она нужна потому, что стандартный Фортран не допускает употребления в индексных выражениях переменных с индексами. Только следуя всем, даже неприятным, правилам, можно гарантировать переносимость и правильность. Большинство компиляторов не требует временного использования J, но лучше быть готовым ко всему.
Строки 155-162. Комментарии должны разъяснять, почему инструкция делает то, что она делает; как это делается, обычно видно из самой инструкции.
Строки 196-211. Было бы излишним переписывать в программу из внешних документов весь алгоритм; читающего программу будут направлять к источникам соответствующие ссылки на литературу. Правда, для этого хорошую внешнюю документацию нужно иметь. О ней следует позаботиться до начала работы над программой.
Строки 238-239. Стоящая особняком инструкция перехода может показаться несколько странной. Ее существование объясняется тем, что структура программы в точности повторяет структуру алгоритма. "Поборники эффективности" могут ворчать, что в строке 226 достаточно заменить GOTO 220 на GOTO 170, экономя две строки исходного текста и одну-две микросекунды на каждое прохождение цикла. Так-то оно так, но можно ли экономить за счет понятности? Сколько микросекунд машинного времени нужно сэкономить, чтобы окупить 5мин. времени программиста?
Строки 277-301. Все форматы собраны в конце программы, чтобы не затемнять логику ее работы. Каждый класс инструкций ввода/вывода, каждый файл, канал, каждое обращение имеет свою последовательность меток. Эти последовательности не перемешиваются друг с другом и с обычными программными метками. Заметьте, что холлеритовы данные передаются посредством старомодных форматов nH, поскольку по стандарту Фортрана эти глупые счетчики необходимы, хотя большинство компиляторов их не требует.
ЗАКЛЮЧИТЕЛЬНЫЕ ЗАМЕЧАНИЯ
На этом заканчивается обсуждение раскрашивания карт. Укажем, что на первоначальную разработку алгоритма ушло около 5 часов, написание программы заняло около 8 часов, ввод ее текста в системе с разделением времени занял около 3 часов, а тестирование и отладка потребовали около 2 часов. Большая часть тестового времени ушла на проверку соответствия между вводом и выводом. Две ошибки при вводе текста и две неправильно расположенные метки обнаружились либо компилятором, либо по нелепой первой выдаче. Дополнительная проверка ввода придумана во время подготовки тестовых данных. Алгоритм содержал один логический дефект, и его удалось вскрыть посредством первого же реального множества данных.
Эта задача иллюстрирует также важность документирования для будущей работы. Приведенный здесь алгоритм на самом деле разработан примерно за 6 месяцев до написания главы. Была формально доказана его правильность. Группа программистов, видевших и алгоритм, и доказательство, единодушно признали их совершенно безукоризненными. Но пока автор собирался сесть писать главу, какие-то жулики украли единственную копию алгоритма и доказательства (хотя трудно себе представить, для чего им эти бумаги). Пришлось потратить еще около 5 часов на восстановление первоначального хода мыслей; при этом снова была допущена логическая ошибка. Пусть же поразят компьютер этих жуликов вечные ошибки четности!
ЛИТЕРАТУРА
Кнут (Knuth D.E.). Estimating the Efficiency of Backtrack Programs. MathemaMathematics of Computation, 29, 129, pp.121-136, 1976.
Хотя для наихудшего случая время работы алгоритма раскраски карт экспоненциально зависит от размера исходного графа, среднее время обычно весьма невелико. Однако аналитический вывод среднего значения, видимо, превышает наши возможности. Кнут описывает метод для оценки скорости работы программ, действующих по методу перебора с возвратами. Оценка дается вручную после просчета некоторых тестовых случаев. Кнут приводит примеры, иллюстрирующие его метод.
Эппл, Хейкен (Appel К., Haken W.). Every Planar Map is Four Colorable. BulleBulletin of the American Mathematical Society, 82, 5, pp.711-712, September 1976.
Стин (Steen L.A.). Solution of the Four Color Problems. Mathematics Magazine, 49, 4, pp.219-272, September 1976.
Иссяк еще один источник диссертаций. Эппл и Хейкен объявили о доказательстве истинности гипотезы о четырех красках. В момент написания данной главы доказательство циркулировало в рукописном виде, и несколько видных специалистов по комбинаторике считали, что, по-видимому, оно верно. К моменту выхода в свет нашей книги доказательство наверняка появится в математических журналах. Стин описывает метод доказательства и его значение для математики. ЭВМ интенсивно использовалась для разработки доказательства и для проверки 1936 случаев в окончательном варианте доказательства.
* Яглом И.М. Четырех красок достаточно. "Природа", 1977, #6, с.20-25.
* Ахо А., Хопкрофт Дж., Ульман Дж. Построение и анализ вычислительных алгоритмов. Пер. с англ.- М.: Мир, 1979.
Это как раз та книга, с которой программисту полезно советоваться в трудных случаях. На стр.449 содержится ссылка на статью с подробным обсуждением теоремы о четырех красках.
* Н.Вирт. Систематическое программирование. Введение. Пер. с англ.- М.: Мир, 1977.
На наш взгляд было бы интересно испытать разные эвристики. Из п.15.4 книги Н.Вирта читатель увидит, как можно механически получать программы, работающие по голой схеме перебора с возвратами.
* ПАРТИЯ ПЕРЕВОДЧИКА
В 1978г. был утвержден новый американский стандарт языка Фортран. Описываемый в нем язык получил название Фортран-77 (см. Катцан Г. Язык Фортран-77. Пер. с англ.- М.: Мир, 1982). Ознакомившись с приводимой ниже программой, читатель, разумеется, легко заметит новые возможности Фортрана. Поскольку программа получена прямолинейным переписыванием авторского варианта, трактовка новых возможностей не вызовет затруднений. По той же причине отсутствуют комментарии. Лишь два момента вызвали небольшие заминки при переписывании программы. Во-первых, в строке 141, видимо, допущена опечатка и вместо OR следует читать AND. Во-вторых, инструкции 232 и 237 GOTO 190 выполняют сразу две функции: завершают условную инструкцию и передают управление на начало цикла. Любопытно сопоставить их с инструкцией 239 GOTO 170, которой автор уделил немало внимания. Небезынтересно также сопоставить авторские замечания с новым вариантом программы.



Ниже в качестве решений представлены законченные программы, однако это далеко не все, что должны сделать студенты. На примере конкретных задач мы обсуждаем искусство программирования, в частности некоторые полезные нюансы, о которых умалчивают многие руководства. Студентам необходимо представить больше внешней документации, больше выдач, больше подтверждений правильности программ. Заметим также, что мы не навязываем другим выбранные нами языки.
29
КРАСЬТЕ С НАМИ,
ИЛИ...
ПОЛНОЕ РЕШЕНИЕ ЗАДАЧИ
В данной главе в полном виде приводится программа для задачи о раскраске карты (см. гл.3). Читатели, которым довелось испытать это на собственной шкуре, знают как трудно описывать программу, излагая алгоритм прозрачно и просто. Когда решение головоломки рассказано, обычной реакцией бывает: "Как я не догадался!" вместо: "Как здорово!" Ну а программа - это, конечно, тоже решение головоломки. Из описаний всегда устраняют дух исследования, историю неудавшихся подходов и отступлений, упоминание о глупых ошибках, сбивавших с правильного пути. Если бы мы попытались полностью изложить процесс разработки программы, вы бы не знали, плакать вам или смеяться над тупостью автора. Так что лучше пойдем уже проторенной дорогой от задачи к решению, лишь изредка поглядывая по сторонам [Для усиления аналогии между трудом писателя и программиста отметим, что данная глава переписывалась не раз и не два].
По условию задачи требуется раскрасить карту или неориентированный граф в минимальное число цветов так, чтобы никаких два СОСЕДНИХ региона (никакие две СМЕЖНЫЕ вершины) не были одного цвета. Хотя в данный момент не требуется точно специфицировать формат исходной и выводимой информации, а также внутреннее представление данных, можно сообразить, какие свойства графа будут существенны для любой программы. Очевидно, нужно знать число вершин графа, уметь регулярным образом обращаться к вершинам, уметь раскрашивать вершины и узнавать их цвет, определять, являются ли две вершины смежными, и, наконец, нужно уметь порождать много различных цветов. Проще всего удовлетворить перечисленным требованиям, обозначив вершины натуральными числами 1, 2, ..., n, где n - общее количество вершин. Аналогично и цвета обозначим натуральными числами (ясно, что при этом в нашем распоряжении окажется много цветов). Вопрос о конкретном способе определения смежности вершин целесообразно отложить.
Раскрашивать можно двумя способами: либо предположить, что каждая вершина уже раскрашена в свой цвет и попытаться избавиться от нескольких цветов, либо предположить, что ни одна вершина еще не раскрашена, и пытаться добавлять как можно меньше цветов. Однако на любом пути мы сталкиваемся с неприятным теоретическим результатом (или с отсутствием оного): никто не знает, как раскрасить карту, не перебрав для худшего случая все возможные раскраски с минимальным числом цветов. Большинство специалистов считает, что нет более быстрого метода раскрашивания карты, чем перебор всех вариантов. Иными словами, какой бы умной ни была ваша программа и как быстро она ни работала в среднем, найдутся карты с n вершинами, требующие k цветов, на раскраску которых программа затратит порядка k**n единиц времени. Возможно, кому-нибудь посчастливится найти алгоритм, и для худшего случая оказывавшийся не столь расточительным, но теоретики считают это маловероятным. Так что давайте займемся простой быстрой программой, а не суперсложной, которая вряд ли будет лучше [Данная программа иллюстрирует важность теоретической информатики для программистов-практиков. Многие другие распространенные КОМБИНАТОРНЫЕ ЗАДАЧИ, среди которых наиболее известна ЗАДАЧА О КОММИВОЯЖЕРЕ, в наихудшем случае требуют для своего решения такой же крайней расточительности, как и раскрашивание карты. Но довольно часто небольшое изменение условия делает возможным очень эффективное решение. Программисту не нужно знать все задачи и их решения, однако он должен узнавать трудные задачи и обращаться за решениями к литературе или специалистам. Между прочим, если не требуется ОПТИМАЛЬНОЕ, МИНИМАЛЬНОЕ, МАКСИМАЛЬНОЕ или ТОЧНОЕ решение, целесообразно испробовать имеющиеся для многих задач эвристики, позволяющие быстро получить хорошие приближения].
Предлагаемое решение основано наблюдении, что если некоторый подграф нельзя раскрасить в k цветов, то и весь граф, очевидно, тоже нельзя раскрасить в k цветов. На каждом шаге нашего алгоритма мы пытаемся добавить к уже раскрашенному подграфу еще одну вершину. Если сделать это не удастся, текущий раскрашенный подграф перекрашивается всеми возможными способами с использованием тех же цветов. Если новую вершину добавить все же нельзя, число цветов увеличивается на единицу, поскольку найден подграф, не раскрашиваемый выделенными цветами. В описании алгоритма предполагается, что есть вектор ЦВЕТ, содержащий цвета, приписанные каждой вершине. Логическая функция СВЯЗЬ позволяет узнать, связана ли вершина i с вершиной j.
АЛГОРИТМ РАСКРАСКИ ГРАФА
1. (Начальная установка). Предположим, что в графе имеется ЧИСЛОВЕРШИН вершин, что переменная СТАРШИЙЦВЕТ содержит номер старшего из уже использованных цветов, а нуль показывает, что вершина еще не наделена цветом. Для всех вершин n установить ЦВЕТ[n] равным нулю (т. е. сделать все вершины нераскрашенными). Установить СТАРШИЙЦВЕТ равным нулю, а переменную ТЕКУЩАЯВЕРШИНА равной единице.
2. (Основной цикл). Пока ТЕКУЩАЯВЕРШИНА не превзойдет ЧИСЛОВЕРШИН, выполнять шаги с 3-го по 7-й. Этим шагом начинается цикл, который повторяется, пока не будут раскрашены все вершины. Перед началом каждого прохождения цикла все вершины от 1 до ТЕКУЩАЯВЕРШИНА - 1 правильно раскрашены в СТАРШИЙЦВЕТ цветов.
3. (Подготовка одного узла). Увеличить ЦВЕТ[ТЕКУЩАЯВЕРШИНА] на единицу. Установить булеву переменную ФЛАГЦИКЛА равной значению отношения ЦВЕТ[ТЕКУЩАЯВЕРШИНА] <= СТАРШИЙЦВЕТ. Теперь рассматриваемая вершина имеет ненулевой цвет, и необходимо проверить, совместима ли ТЕКУЩАЯВЕРШИНА со своими соседями. Заметьте, что впервые добавляемая вершина всегда имеет нулевой цвет. Прибавляя единицу к нулю, мы наделяем вершину допустимым цветом. Пока ФЛАГЦИКЛА имеет значение ИСТИНА, выполнять шаги 4 и 5.
4. (Проверка цвета смежных вершин). Присвоить переменной ФЛАГЦИКЛА значение ЛОЖЬ и установить i равным единице. Пока i меньше, чем ТЕКУЩАЯВЕРШИНА, выполнять шаг 5.
5. (Проверка цвета каждого соседа). Если вершина i и ТЕКУЩАЯВЕРШИНА связаны (т.е. если связь (i, ТЕКУЩАЯВЕРШИНА) имеет значение ИСТИНА) и если ЦВЕТ[i] и ЦВЕТ[ТЕКУЩАЯВЕРШИНА] равны, значит, текущаявершина имеет недопустимый цвет. В этом случае установить значение i равным ТЕКУЩАЯВЕРШИНА, чтобы прервать цикл, начинающийся в шаге 4, увеличить ЦВЕТ[ТЕКУЩАЯВЕРШИНА] на единицу чтобы попробовать следующий цвет, и установить значение ФЛАГЦИКЛА равным значению отношения ЦВЕТ[ТЕКУЩАЯЕЕРШИНА] <= СТАРШИЙЦВЕТ. В противном случае просто увеличить i на единицу, чтобы проверить следующего соседа. Заметьте, что последнее присваивание переменной ФЛАГЦИКЛА перекроет присваивание в шаге 4, но может установить переменную ФЛАГЦИКЛА равной значению ЛОЖЬ. Далее, если начинающийся в шаге 4 цикл завершается нормально (т.е. без насильственного присваивания переменной ТЕКУЩАЯВЕРШИНА значения i), произойдет выход из цикла, начинающегося в шаге 3. Важно, чтобы при проверке допустимости раскраски использовались лишь вершины, номера которых строго меньше, чем ТЕКУЩАЯВЕРШИНА, поскольку вершины с большими номерами еще не раскрашены.
6. (Продвинуться или вернуться?) Если ТЕКУЩАЯВЕРШИНА получила допустимый цвет, мы хотим перейти к следующей вершине; в противном случае необходимо отступить. Поэтому, если ЦВЕТ[ТЕКУЩАЯВЕРШИНА] > СТАРШИЙЦВЕТ, установить ЦВЕТ[ТЕКУЩАЯВЕРШИНА] равным нулю и уменьшить значение ТЕКУЩАЯВЕРШИНА на единицу; в противном случае увеличить значение ТЕКУЩАЯВЕРШИНА на единицу. Заметьте, что цвета вершин с номерами большими, чем ТЕКУЩАЯВЕРШИНА, по-прежнему нулевые и что, когда мы возвращаемся к уже раскрашивавшейся вершине, мы продолжаем продвигать ее цвет со значения, оставшегося от предыдущей обработки.
7. (Добавление цвета, если это необходимо). Если ТЕКУЩАЯВЕРШИНА нулевая, увеличить СТАРШИЙЦВЕТ на единицу и установить значение ТЕКУЩАЯВЕРШИНА равным единице. Если мы вернулись к самому началу, число цветов необходимо увеличить.
Легко видеть, что данный алгоритм должен завершиться. В крайнем случае он остановится, когда все вершины получат разные цвета. Также достаточно ясно, что перед началом каждого прохождения основного цикла все вершины от первой до (ТЕКУЩАЯВЕРШИНА - 1) имеют допустимую раскраску. Чуть менее очевидно, что СТАРШИЙЦВЕТ увеличивается только тогда, когда невозможно раскрасить некий начальный подграф выделенным числом цветов. Удостовериться в этом вам помогут эксперименты на небольших графах. Заметьте, что алгоритм правильно работает для пустого графа, для графов, все вершины которых изолированы, и для графов, все вершины которых связаны.
РЕАЛИЗАЦИЯ
В нашей реализации мы используем Фортран. Ясно, что Фортран - очень бедный язык, с недостаточными возможностями определения данных и управления последовательностью действий. Однако мы выбрали его как раз для того, чтобы показать, что даже на неудобном языке можно написать хорошо структурированную, ясную программу. Теоретически каждую программу можно было бы написать на более новом, более выразительном языке; на практике большинству программистов время от времени приходится работать на архаичном языке, но плохие инструменты не могут служить оправданием для плохого программирования.
Логическую функцию СВЯЗЬ на Фортране можно представить двумерным логическим массивом, в котором (i,j)-й элемент имеет значение ИСТИНА тогда и только тогда, когда вершина i связана с вершиной j. Первый элемент ввода - это запись с количеством вершин раскрашиваемого графа. Затем читаются наборы записей, где каждый набор описывает связи одной вершины. Первая запись набора содержит номер вершины и количество ее соседей; в оставшихся записях в произвольном порядке перечисляются соседи. Признаком конца исходных данных служит нулевой номер вершины. Вершины можно описывать в произвольном порядке, а описание одной вершины можно разбивать на несколько частей. Когда вершина i связывается с вершиной j, вершина j автоматически связывается с вершиной i. Единственными возможными ошибками являются выход номера вершины за допустимые границы и попытка связать вершину с ней самой. Ниже воспроизводится реальная программа.






Исходные данные взяты с рис.1 из гл.3. Штаты перенумерованы сверху вниз; столбцы упорядочены слева направо. В каждой головной перфокарте справа присутствует название штата; вследствие заданного формата существенны только первые восемь литер карты. Для экономии места в книге данные разбиты на две колонки, но в остальном они точно соответствуют требованиям программы.

Выдача выглядит наилучшим образом, если ее напечатать на АЦПУ и повесить на стену. Пропорции приведенной в книге выдачи несколько нарушают симметрию. Заметьте, что горизонтальная печать решения экономит много бумаги, без всякой потери информации. Первоначально мы хотели напечатать номера и цвета вершин вертикально, что делается несколько проще, но выдача при этом получается весьма неряшливой.

ЗАМЕЧАНИЯ ПО ПРОГРАММЕ
Строки 1-19. Заголовок программы служит тем же целям, что и аннотация в научной статье. Вне зависимости от того, велика или мала программа, в ее начале должна присутствовать такого рода информация. В частности, в программе обязательна ссылка на соответствующую внешнюю документацию.
Строки 22-26. Если бы программа была побольше, перед определением данных следовало бы поместить больше материала по алгоритмическим вопросам. В нашем же случае тексту программы предшествует полный словарь. Поскольку размеры модулей не должны превышать нескольких страниц, мы предпочли толковый словарь, в котором переменные упоминаются группами в соответствии со своей ролью, важностью и местом употребления. Очевидно, количество пояснений в словаре зависит от других комментариев, но ни одна переменная не должна быть выпущена. Мы пытались сделать шести литерные имена мнемоничными, однако нелегко бороться против одного из глупейших фортрановских правил.
Строки 62-89. Все переменные продекларированы, хотя в Фортране декларации не обязательны. Во-первых, лучше перестраховаться, а во-вторых, лучше увериться, что читающий программу точно знает наши намерения. Комментарии в строках 62-65 поясняют, почему мы отклоняемся от стандарта: к этому нас вынуждает компилятор; точно указаны изменения, которые могут потребоваться при выполнении программы на другой вычислительной установке. Во вводе/выводе использованы переменные номера каналов, так что если программа переносится на другую установку с другими соглашениями о номерах, для налаживания работы ввода/вывода потребуется только одно изменение.
Строки 92-98. Начиная с этого места перемежаются абзацы комментариев на естественном языке и абзацы инструкций на Фортране. Не давайте комментарии слишком часто, иначе будет трудно уследить за порядком выполнения программы. Разумеется, ничто не может оправдать недостаток комментариев. В нашей программе 145 строк комментариев и 157 строк с инструкциями на Фортране. По общему правилу комментарии пишутся перед соответствующими инструкциями.
Строки 105-109. Помечать следует только инструкции CONTINUE и FORMAT. В Фортран-программе всегда много меток, и при отладке часто приходится перемещать их. Не накликайте беды, помечая самостоятельные инструкции, при перемещении которых легко ошибиться. По тем же причинам в одной строке закрывайте только один DO-цикл.
Строки 110-115. Проверка исходных данных - одновременно одна из самых скучных и самых важных обязанностей программы. Не доверяйте ничьим данным, даже своим собственным. Обратите внимание на инверсию смысла логических проверок в условных инструкциях. Подобная инверсия - обычное для Фортрана дело. Трудно выработать твердую схему для ступенчатой записи условных инструкций (ввиду отсутствия else), но имеющиеся в программе примеры показывают возможные варианты.
Строки 139-151. Метка 65 демонстрирует целесообразность расположения меток в порядке возрастания, с большим постоянным шагом. Проверка исходных данных, расположенная непосредственно перед меткой 65, добавлена после того, как при подготовке данных была допущена ошибка. Когда метки упорядочены, вставка дополнительных инструкций не вызывает затруднений. Обратите внимание также на использование переменной J. Она нужна потому, что стандартный Фортран не допускает употребления в индексных выражениях переменных с индексами. Только следуя всем, даже неприятным, правилам, можно гарантировать переносимость и правильность. Большинство компиляторов не требует временного использования J, но лучше быть готовым ко всему.
Строки 155-162. Комментарии должны разъяснять, почему инструкция делает то, что она делает; как это делается, обычно видно из самой инструкции.
Строки 196-211. Было бы излишним переписывать в программу из внешних документов весь алгоритм; читающего программу будут направлять к источникам соответствующие ссылки на литературу. Правда, для этого хорошую внешнюю документацию нужно иметь. О ней следует позаботиться до начала работы над программой.
Строки 238-239. Стоящая особняком инструкция перехода может показаться несколько странной. Ее существование объясняется тем, что структура программы в точности повторяет структуру алгоритма. "Поборники эффективности" могут ворчать, что в строке 226 достаточно заменить GOTO 220 на GOTO 170, экономя две строки исходного текста и одну-две микросекунды на каждое прохождение цикла. Так-то оно так, но можно ли экономить за счет понятности? Сколько микросекунд машинного времени нужно сэкономить, чтобы окупить 5мин. времени программиста?
Строки 277-301. Все форматы собраны в конце программы, чтобы не затемнять логику ее работы. Каждый класс инструкций ввода/вывода, каждый файл, канал, каждое обращение имеет свою последовательность меток. Эти последовательности не перемешиваются друг с другом и с обычными программными метками. Заметьте, что холлеритовы данные передаются посредством старомодных форматов nH, поскольку по стандарту Фортрана эти глупые счетчики необходимы, хотя большинство компиляторов их не требует.
ЗАКЛЮЧИТЕЛЬНЫЕ ЗАМЕЧАНИЯ
На этом заканчивается обсуждение раскрашивания карт. Укажем, что на первоначальную разработку алгоритма ушло около 5 часов, написание программы заняло около 8 часов, ввод ее текста в системе с разделением времени занял около 3 часов, а тестирование и отладка потребовали около 2 часов. Большая часть тестового времени ушла на проверку соответствия между вводом и выводом. Две ошибки при вводе текста и две неправильно расположенные метки обнаружились либо компилятором, либо по нелепой первой выдаче. Дополнительная проверка ввода придумана во время подготовки тестовых данных. Алгоритм содержал один логический дефект, и его удалось вскрыть посредством первого же реального множества данных.
Эта задача иллюстрирует также важность документирования для будущей работы. Приведенный здесь алгоритм на самом деле разработан примерно за 6 месяцев до написания главы. Была формально доказана его правильность. Группа программистов, видевших и алгоритм, и доказательство, единодушно признали их совершенно безукоризненными. Но пока автор собирался сесть писать главу, какие-то жулики украли единственную копию алгоритма и доказательства (хотя трудно себе представить, для чего им эти бумаги). Пришлось потратить еще около 5 часов на восстановление первоначального хода мыслей; при этом снова была допущена логическая ошибка. Пусть же поразят компьютер этих жуликов вечные ошибки четности!
ЛИТЕРАТУРА
Кнут (Knuth D.E.). Estimating the Efficiency of Backtrack Programs. MathemaMathematics of Computation, 29, 129, pp.121-136, 1976.
Хотя для наихудшего случая время работы алгоритма раскраски карт экспоненциально зависит от размера исходного графа, среднее время обычно весьма невелико. Однако аналитический вывод среднего значения, видимо, превышает наши возможности. Кнут описывает метод для оценки скорости работы программ, действующих по методу перебора с возвратами. Оценка дается вручную после просчета некоторых тестовых случаев. Кнут приводит примеры, иллюстрирующие его метод.
Эппл, Хейкен (Appel К., Haken W.). Every Planar Map is Four Colorable. BulleBulletin of the American Mathematical Society, 82, 5, pp.711-712, September 1976.
Стин (Steen L.A.). Solution of the Four Color Problems. Mathematics Magazine, 49, 4, pp.219-272, September 1976.
Иссяк еще один источник диссертаций. Эппл и Хейкен объявили о доказательстве истинности гипотезы о четырех красках. В момент написания данной главы доказательство циркулировало в рукописном виде, и несколько видных специалистов по комбинаторике считали, что, по-видимому, оно верно. К моменту выхода в свет нашей книги доказательство наверняка появится в математических журналах. Стин описывает метод доказательства и его значение для математики. ЭВМ интенсивно использовалась для разработки доказательства и для проверки 1936 случаев в окончательном варианте доказательства.
* Яглом И.М. Четырех красок достаточно. "Природа", 1977, #6, с.20-25.
* Ахо А., Хопкрофт Дж., Ульман Дж. Построение и анализ вычислительных алгоритмов. Пер. с англ.- М.: Мир, 1979.
Это как раз та книга, с которой программисту полезно советоваться в трудных случаях. На стр.449 содержится ссылка на статью с подробным обсуждением теоремы о четырех красках.
* Н.Вирт. Систематическое программирование. Введение. Пер. с англ.- М.: Мир, 1977.
На наш взгляд было бы интересно испытать разные эвристики. Из п.15.4 книги Н.Вирта читатель увидит, как можно механически получать программы, работающие по голой схеме перебора с возвратами.
* ПАРТИЯ ПЕРЕВОДЧИКА
В 1978г. был утвержден новый американский стандарт языка Фортран. Описываемый в нем язык получил название Фортран-77 (см. Катцан Г. Язык Фортран-77. Пер. с англ.- М.: Мир, 1982). Ознакомившись с приводимой ниже программой, читатель, разумеется, легко заметит новые возможности Фортрана. Поскольку программа получена прямолинейным переписыванием авторского варианта, трактовка новых возможностей не вызовет затруднений. По той же причине отсутствуют комментарии. Лишь два момента вызвали небольшие заминки при переписывании программы. Во-первых, в строке 141, видимо, допущена опечатка и вместо OR следует читать AND. Во-вторых, инструкции 232 и 237 GOTO 190 выполняют сразу две функции: завершают условную инструкцию и передают управление на начало цикла. Любопытно сопоставить их с инструкцией 239 GOTO 170, которой автор уделил немало внимания. Небезынтересно также сопоставить авторские замечания с новым вариантом программы.



Gudleifr- Admin
- Сообщения : 3252
Дата регистрации : 2017-03-29
Re: Уэзерелл. Этюды для программистов. 1982
автор Gudleifr Пт Мар 05, 2021 10:05 am
30
СЖАТЫЕ СТРОКИ,
ИЛИ...
ПРОГРАММА УПЛОТНЕНИЯ ТЕКСТОВ
В гл.11 был рассмотрен полезный алгоритм, предназначенный для сжатия текстовой информации. И работай вы программистом, скажем в библиотеке или в газете, то были бы вправе ожидать, что шеф выложит вам на стол одиннадцатую главу и предложит попытаться подключить описанный в ней алгоритм к уже работающей системе. А поскольку кажется вполне правдоподобным, что этот алгоритм мог бы обеспечить значительную экономию памяти, то и задача выглядит на первый взгляд привлекательной. Сомнения приходят позже.
- Насколько сложны алгоритмы, необходимые для выполнения сравнений в словаре, какова сложность структур данных? Как долго придется со всем этим возиться?
- Работа алгоритма определяется наборами параметров. Как эти параметры выбрать?
- В какой степени коэффициент сжатия зависит от вариаций в уплотняемом тексте?
- Ради экономии памяти расходуется процессорное время. Когда можно считать, что овчинка стоит выделки?
- Вообразим, что в первой версии программы все уже ясно и она работает правильно, хотя и не очень эффективно. Какие переделки позволят поднять ее производительность? Можно ли в исходном проекте предусмотреть возможность внесения изменений и дополнений без больших переделок?
- И наконец, сколько времени стоит потратить на эту задачу, чтобы считать, что она выполнена достаточно хорошо?
Примерно те же вопросы должны возникнуть и у начальника, да еще наряду с сомнениями, тот ли вы программист, который осилит поставленную задачу. Тем не менее нельзя допустить, чтобы сомнения вас парализовали. Энергично беритесь за дело невзирая на отдельные трудности (но и не забывая о них) и сконцентрируйте все свои усилия на тех вопросах, которые кажутся легко разрешимыми. В данной работе мы в свою очередь испробуем прежде всего программу, использующую простые структуры данных и алгоритмы. А после того, как программа заработает правильно, постараемся ее улучшить, внося различные усовершенствования. Вполне может так случиться, что свойства программы будут зависеть от неких параметров, поэтому постараемся сделать так, чтобы их можно было легко менять; в первом варианте программы, однако, мы будем просто пробовать возможные значения. Для того чтобы исследовать, как влияют на результаты вносимые в программу изменения, исходная информация или параметры программы, мы будем разрабатывать ее как автономную, не являющуюся частью какой-либо большей системы,- и тогда эффективность интересующей нас программы не будет скрыта за накладными расходами ее окружения.
На практике, разумеется, сжатие текстов, как правило, только часть некоторой большей задачи, предполагающей наличие значительных массивов текста. А положит конец нашей работе отнюдь не снижающаяся результативность, а усталость и скука.
КАК ЗАТОЧИТЬ КАРАНДАШ
У каждого писателя своя манера подготовки к работе. Некоторым надо протрезветь, а кое-кому выпить, одни встают в 4 утра, другие поднимаются на ночь; некоторым необходима тишина, а другим требуется шумная веселая обстановка, а есть и такие, которые обходятся остроотточенным карандашом и традиционным блокнотом. Программисты - те же писатели, и им требуется найти удобный для себя распорядок и уютную окружающую обстановку. Прежде чем приступить к решению задачи о сжатии текста, хотелось бы предложить несколько рецептов, как сделать процесс программирования более приятным и плодотворным. Нас такая методика вполне устраивает, и вы уж по крайней мере испробуйте ее, прежде чем вернетесь к своей собственной.
Программы должны быть читабельными, а это достигается прежде всего их единообразием и согласованностью. Такие качества обусловливают общепризнанный стиль программирования, когда повторяющиеся действия записываются по возможности сходными конструкциями. Чтобы повысить единообразие в программах, старайтесь программировать всегда в одной и той же окружающей обстановке. Почти все наши программы, в том числе большая часть приведенных в книге, написаны в старом садовом кресле-качалке, к которому из листов фанеры и пластмассы была на скорую руку прилажена доска для письма. Это сооружение располагается в жилой комнате, где легко включить стереозапись классической музыки и где всегда под рукой охлажденный чай в холодильнике. То, что нельзя начинать программировать, если в доме гости,- это, конечно, совершенно справедливо. И все же дома настолько спокойнее, чем в любом учреждении, что делается во много раз больше. Может быть, вы предпочтете какие-нибудь другие условия. Не оставляйте поисков, пока не найдете для себя действительно удобной обстановки, а потом поймите, каким образом ее воспроизвести всякий раз, когда программируете.
Многие программисты работают так: набросают на обороте старого конверта несколько строк программы и мчатся к терминалу, чтобы поскорее их набрать и пропустить. А все остальное время занимаются тем, что вставляют в программу там и сям заплатки, и конечный результат их труда смотрится так, словно ужасный доктор Франкенштейн впопыхах прооперировал Шалтая-Болтая. На самом деле, немаловажный вклад в повышение читабельности вносит самодисциплина, одним из способов воспитания которой служат бланки для записи программ. Свободные художники, о которых упоминалось выше, часто с пренебрежением взирают на программистов, которые работают, заполняя клеточки на бланках, и тем не менее бланки оказывают сильное стабилизирующее влияние на манеру работы и во много раз облегчают разработку и использование метода ступенчатой записи программ. Кроме того, программу, написанную на бланках, можно отдать на перфорацию. Причем, как ни приятно освободиться от нудной работы, намного важнее, что девушки из перфораторной ПРОЧИТАЮТ программу и проверят правильность пробивки. Поэтому многие описки никогда не попадут в машину, да и лишний глаз - вовсе не помеха.
Теперь о борьбе с предрассудком. Старайтесь писать свои программы чернилами. Большинство институтских преподавателей программирования будет говорить, что не надо бояться допустить ошибку в программе (это-то достаточно справедливо) и что ластик может стать вашим самым мощным инструментом. К несчастью, ластик может оказаться чересчур мощным. Ведь коль скоро ошибки так просто исправить, значит, пока не совершишь очередную, можно особенно тщательно и не думать. В том же случае, когда вы пишете чернилами, ошибки обходятся дороже, в особенности из-за того, что измазанный переправленный бланк могут однажды на пробивку не принять. Из-за никчемных ошибок придется переписывать целую страницу. Неудача вынудит вас писать медленнее и глубже задумываться над каждой строкой; время, потраченное на написание, окупится при тестировании и отладке программы. Даже если у вас есть редактор текстов, который поощряет или навязывает правильный стиль программирования, все равно следует испробовать эти последние две рекомендации. Запись программы необходимо тщательно продумывать, а опыт показывает, что от электрических полей, окружающих терминалы компьютера, в наших мыслях нередко возникают короткие замыкания.
Вместо того чтобы пользоваться блок-схемой, старайтесь сначала писать комментарии. Всякий раз, когда начинаете новую программу, пишите длинные комментарии, в которых как можно подробнее описывайте назначение программы и ее организацию. Относитесь к составлению комментариев как к важнейшей программистской задаче. После того как комментарии написаны, положите их перед собой и, пользуясь написанным как справочником, протранслируйте их вручную на используемый вами язык программирования. И если язык не очень нудный, как, например, язык ассемблера, то перевод не должен быть существенно длиннее комментариев, а может оказаться даже короче. Благодаря тому что комментарии написаны на отдельных листах (предположительно бланках), их можно рассматривать как документацию, которую нет надобности переписывать только из-за того, что транслируемая программа оказалась неверной. Конечно, если у вас изменятся замыслы в отношении программы, может быть, и потребуется переписать как комментарии, так и сам код.
Ни одну программу не приводите к виду, пригодному для ввода в машину, до тех пор, пока не напишете ее полностью. Однако, как только закончите, пропустите, не откладывая, через машину и устраните все описки,- все неправильно написанные идентификаторы, поставленные не на место точки с запятой и т.д. Ваша цель - получить чистый листинг, лучше бы с полной таблицей перекрестных ссылок. Такой "чистый" листинг не свободен, конечно, от ошибок - просто он не содержит совсем уж глупых, которые в состоянии обнаружить транслятор. Теперь садитесь за программу и пройдитесь по ней так, словно кто-то другой пытается вам ее продать. Проверьте каждую инструкцию, прокрутите каждый цикл, ищите неиспользуемые или употребляемые неверно переменные, старайтесь упростить структуру управления, подправляйте даже знаки препинания в комментариях. Причиной того, почему все это делается на листинге, а не на бланках, является тот факт, что многие ошибки отчетливее проявляются на фоне аккуратно отпечатанной программы. Именно в это время уже пора привести в порядок внешний вид программы, чтобы она стала как можно более наглядной. Если в листинге набралось уже столько правок, что за ними не видно саму программу, внесите все исправления, отпечатайте новый листинг и продолжайте дальше. Не жалейте бумагу - пропущенная ошибка вам может обойтись куда дороже.
Эти предложения годятся, очевидно, не для любых программ и не во всех случаях. Многие системы программирования снабжены целым арсеналом средств, помогающих в процессе разработки программ. Пренебрегать этими возможностями было бы глупо и расточительно. Они особенно полезны при создании программ одноразового использования и для контроля хода работ в больших проектах. Однако мы не можем не предостеречь вас самым серьезным образом: машина не должна мешать вам принимать решения. Чарующая песня компьютера "Доверься мне - я все решу" соблазнила многих программистов и привела к крушению их замыслов.
АНАЛИЗ ВОПРОСА
Поскольку оба основных алгоритма (построение словаря и кодирование текста) уже разработаны, нам необходимо рассмотреть теперь, какими вспомогательными программами их надо снабдить. Прежде всего отметим, что в обоих алгоритмах введенный текст просматривается слева направо и при сравнениях его на совпадение со словарем важны лишь несколько ближайших рядом стоящих литер. Это значит, что как для построения словаря, так и для кодирования можно применить одну и ту же программу ввода и что нам не следует заботиться о деталях доступа к входному потоку, поскольку программа ввода всегда выдает литеры для проведения сравнений или признак конца файла. Во-вторых, в обоих алгоритмах требуется поиск цепочки в словаре, но ни один из алгоритмов не должен зависеть от метода поиска. Поэтому и здесь алгоритмы могут быть снабжены общей обслуживающей программой, и по-прежнему нет необходимости уточнять детали. В-третьих, алгоритму кодирования потребуется хотя бы одна литера, нигде во вводимом тексте не используемая и выступающая в качестве управляющего кодирующего знака. Вместо того чтобы выбрать некую литеру до прочтения текста, можно в программе ввода отслеживать все поступающие на вход литеры и для кодирования употребить любую невстретившуюся. Процедура построения словаря, написанная на XPL показана на рис.30.1 [Номера строк в этой процедуре те же, что и в полной программе, приведенной далее].

Рисунок 30.1.
Здесь уместно кое-что пояснить. Процедура написана на XPL - языке, в достаточной степени похожем как на Паскаль, так и на PL/I, так что его легко понять (подтверждение того факта, что разобраться в специализированном языке, как правило, весьма несложно). Применительно к нашей задаче XPL обладает рядом достоинств, в том числе наличием в языке цепочек в качестве встроенного типа данных и удобных управляющих структур. Недостаток языка заключен, в частности, в том, что единственным видом структурированных данных являются одномерные статические массивы. Язык содержит и редко встречающиеся средства - оператор конкатенации цепочек || и функцию SUBSTR, употребляемую для выделения из имеющейся цепочки подцепочки [Если переменная V - цепочка или выражение, тогда SUBSTR(V, S, L) есть подцепочка V, начинающаяся с S-й литеры (первая литера цепочки имеет номер нуль) и содержащая L байтов. Если аргумент L опущен, будет выдан весь остаток цепочки V, начиная с S-й позиции. Функция LENGTH выдает в качестве значения число литер в цепочке-аргументе. В строке 332 процедуры BUILD.DICTIONARY используется SUBSTR вместе с LENGTH для того, чтобы исключить сличенную цепочку MATCH из начала INPUT.BUFFER (буфер ввода)]. Программа ввода FILL.INPUT.BUFFER (заполнение входного буфера) загружает входной буфер, если он оказывается пустым, и выдает пустую цепочку в случае, когда вводимый файл исчерпан. Если вводить больше нечего, происходит выход из программы BUILD.DICTIONARY (построение словаря). Заметим, что сравнить длину цепочки с нулем и проверять, не пустая ли она,- это одно и то же, но в данном случае первое предпочтительнее, поскольку в XPL операция LENGTH весьма эффективна. Посмотрите теперь как выглядит процедура ввода (рис.30.2).

Рисунок 30.2.
Программы ввода и вывода используют встроенные функции и всегда читают или печатают цепочки. На самом же деле PRINT (печать) является макрокомандой, внутри которой и скрыта работа вывода. Программа FILL.INPUT.BUFFER при необходимости распечатывает буфер ввода и, кроме того, регистрирует данные о каждой встретившейся литере. Функция BYTE при использовании ее в выражении преобразует выбранную из цепочки литеру в целое число таким образом, чтобы можно было ее использовать в арифметических операциях. В нашем случае литеры употребляются для индексирования логического вектора CHARACTER.USED (встречаемость литер), в котором регистрируются все встретившиеся литеры. Кроме того, BYTE употребляется в BUILD.ENCODING.TABLE (формирование таблицы кодировок) для обратного превращения целых чисел в литеры; таким образом, BYTE выполняет те же функции, что и ORD и CHAR в Паскале.
В качестве структуры хранения информации в словаре выберем сначала простую неупорядоченную таблицу, в которой будет осуществляться линейный поиск. Такую структуру можно будет запросто отладить, хотя она, по-видимому, окажется мучительно неэффективна. Но как только у нас все заработает, можно попытаться ускорить поиск. В каждом гнезде словаря будут четыре поля: цепочка литер, частота гнезда во время построения словаря, кодировка, присвоенная этой цепочке, и счетчик обращений к ней при сжатии текста. Эти поля запоминаются в соответствующих четырех массивах, описанных в строках 66-73 главной программы (вот тут-то начинает давать о себе знать ограниченность структур данных в XPL). Первое полноценное гнездо всегда имеет номер 0, а последнее - DICTIONARY.TOP (вершина словаря). Максимальный размер словаря задает макро DICTIONARY.SIZE (размер словаря). При поиске требуется лишь полный просмотр всех гнезд словаря; новые гнезда могут добавляться в конец таблицы. При исключении низкочастотных гнезд на их место переписываются высокочастотные гнезда; читателю надлежит убедиться самому, что при работе цикла, описанного в строках 261-270, информация не теряется. Ниже программа приведена полностью, причем программы работы со словарем описаны в строках 195-296. Обратите внимание, что вычисление параметров, влияющих на степень сжатия, разнесено по самостоятельным подпрограммам, приведенным в строках 154-193, что позволяет с легкостью их отыскать и заменить. Мы предпочли здесь удобство в ущерб эффективности: в окончательной рабочей версии желательно исключить подпрограммы вычисления параметров, а требуемые функции переписать прямо в тех местах, где они должны использоваться.











РЕЗУЛЬТАТЫ
Программа была пропущена, а в качестве исходных данных было использовано ее собственное короткое предисловие. Результаты отпечатаны ниже и снабжены номерами строк, чтобы было легче на них ссылаться. В строках 67-71 показана таблица кодировок. При таком коротком текстовом файле нет ничего удивительного, что словарь получился маленьким. Сжатие составляет лишь 0.973 отчасти из-за того, что строки текста в основных комментариях не раздуты за счет тех самых пробелов, которые столь милы сердцу большинства программ сжатия. Тем не менее имеются некоторые любопытные моменты, о чем свидетельствует строка 69. Обратите внимание, что сжатия "D F" не произошло, поскольку другое сжатие слопало "D" еще раньше.

О ПРЕДПРИНЯТЫХ УСОВЕРШЕНСТВОВАНИЯХ
Как предрекалось выше, линейный поиск в словаре не очень-то эффективен. Когда текст всей исходной программы был взят в качестве исходных данных, для его сжатия на машине со средним быстродействием потребовалось 127с, что страшно долго для файла в 500 строк. Заметьте, что, для того чтобы гарантировать при поиске в словаре отыскание самой длинной из цепочек, совпадающих с началом текста на входе, необходимо просмотреть все гнезда словаря. А вот если гнезда словаря расположить в порядке от самых длинных к самым коротким, поиск можно было бы прекратить при первом же удачном сравнении, ибо волей-неволей найденная цепочка была бы самой длинной из всех возможных. Причем процедуру поиска можно было бы не менять, и выбрасывание низкочастотных гнезд не нарушило бы порядок следования цепочек - от длинных к коротким. Однако при заведении нового гнезда необходимо все более короткие цепочки сдвинуть в таблице на одну позицию вниз. Чтобы определить, где производить вставку, мы ввели массив LENGTH.VECTOR (массив длин), i-я компонента которого указывает на гнездо словаря, в котором начинаются цепочки длиной i литер (если таковые есть) или короче (если нет ни одной цепочки длиной i). В случае если цепочки длиной i литер или меньше отсутствуют, значение LENGTH.VECTOR(i) равно значению DJCTIONARY.TOP + 1. Программы, приведенные ниже, обеспечивают правильное хранение новой структуры данных. Чтобы создать новую версию программы сжатия, в соответствующие места нашей программы помещаются вставки, которые и приведены. Отметим, что для облегчения этого процесса массив вставок снабжен необходимыми комментариями.



Можно рассчитывать, что при использовании поиска до первого совпадения во время построения словаря сравнений будет меньше, а более сложная процедура добавления новых гнезд может занять при этом большее время. Тем не менее из табл. 30.1 видно, что, несмотря на меньшее число сравнений при поиске в упорядоченном словаре, как время построения словаря, так и время кодирования текста увеличивается. Следует, однако, отметить, что для сравнений в первоначальной программе можно обойтись лишь дешевыми проверками длин цепочек, в то время как при поиске в упорядоченном словаре все сравнения требуют дорогих операций сопоставления цепочек. Чтобы повысить эффективность программы, надо бы, конечно, что-то предпринять. Но с другой стороны, проведенная переделка программы иллюстрирует важный принцип отладки. Если структура программы заменяется на функционально эквивалентную, то результаты при тех же исходных данных должны оставаться неизменными. На фактический процесс сжатия организация словаря влиять не должна, только параметры сжатия должны сказываться на содержании словаря. Следовательно, убеждаясь, что результаты работы программы с простым линейным поиском и с поиском до первого совпадения совершенно одинаковы (за исключением временной статистики), мы проверяем правильность изменений в подпрограммах, оперирующих со словарем. Это является также контролем на отсутствие ошибок в других частях программы: если бы в какой-нибудь другой подпрограмме был ляпсус, то он вполне мог бы проявиться в программах работы со словарем. А если уж результаты остаются постоянными после того, как подключается правильная программа поиска до первого совпадения, не исключено (но вовсе и не обязательно), что скрытых ошибок, влияющих на словарь, нет.
Таблица 30.1. Сравнение двух алгоритмов организации словаря
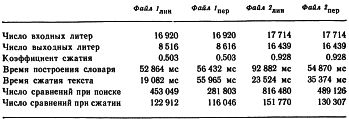
Файл 1 содержит обычную производственную информацию, а файл 2 является текстом исходной программы с линейным поиском. В последнем случае коэффициент сжатия плохой из-за неудачно выбранных параметров. Индексы в названиях файлов соответствуют различным способам поиска - линейному или до первого совпадения.
ВЫБОР ПАРАМЕТРОВ
Конструированием словаря управляют четыре параметра: размер словаря, порог укрупнения гнезд, начальное значение счетчика укрупненных гнезд и порог исключения гнезд. Выбор, который мы сделали, может показаться несколько странным. Размер словаря определяет макро DICTIONARY.SIZE и задается в нашем случае равным 100 (не забудьте, что массивы в XPL начинаются с нулевого индекса), а начальное значение счетчика в гнезде - посредством функции FIRST.COUNT (начальный счетчик) - устанавливается равным единице. Укрупнение гнезд производится в случае, когда каждое из них имеет частоту не меньше, чем
DICTIONARY.SIZE/(DICTIONARY.SIZE - DICTIONARY.TOP + 1) + 1,
т.е. когда частоты обоих гнезд больше величины, обратно пропорциональной свободному пространству словаря. При этом мы исходили из представления (которое не слишком-то хорошо себя оправдало), что, когда словарь почти заполнен, записать новое гнездо должно быть труднее. Исходя из вида приведенного выражения, мы называем порог укрупнения гнезд ЗАВЫШЕННЫМ порогом укрупнения. Исключение гнезд осуществляется в случае, если их частоты по крайней мере не больше средней частоты,- предполагается, что она является приближенным значением медианы.
Чтобы установить, в какой степени такой выбор параметров действительно необоснован, изменим каждый из них, кроме размера словаря, и положим их значение равным пяти. В табл.30.2 отражены результаты обработки обоих файлов. Из таблицы видно, что как порог укрупнения, так и порог исключения оказались неудачными. Вполне возможно, что завышенный порог укрупнения не позволяет объединить и поместить в таблицу достаточное число укрупненных гнезд и, кроме того, быть может, средняя частота, взятая в качестве порога исключения, является плохим приближением медианы, что приводит к ликвидации слишком большого числа гнезд. Все это - лишь очень поверхностное исследование, и надо бы собрать еще дополнительный материал. Однако нас заест тоска раньше, чем программа станет более эффективной.
Таблица 30.2. Небольшое исследование влияния параметров
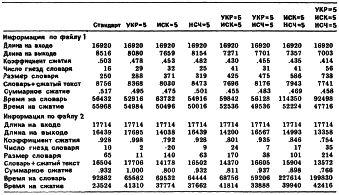
Запись УКР=5 (ИСК=5, НСЧ=5) означает, что в соответствующем столбце результатов порог УКРупнения (порог ИСКлючения, Начальное значение СЧетчика) устанавливается равным 5. В строках РАЗМЕР СЛОВАРЯ указано минимальное количество литер, необходимое для записи гнезд словаря и их кодировок. Величина суммарного сжатия получена путем деления суммы размера словаря и длины выходного файла на длину входного файла. Времена приведены в мс.
ЗАКЛЮЧИТЕЛЬНЫЕ ЗАМЕЧАНИЯ
Должно быть, эта глава совершенно не похожа на проект, выполненный на пять с плюсом. Над самой программой можно было потрудиться и побольше, особенно над комментариями. Немало среди них путаных и бесполезных. В результате напечатанная программа еще на полпути к завершению, и вы можете полюбоваться, на что похожи ваши собственные недоделанные программы. Вернитесь назад и еще разберите программу, задаваясь при этом мысленным вопросом: "А как бы можно было вылизать данную строку (комментарий, процедуру), чтобы достичь кристальной ясности?" И после того, как вы, ехидничая поводу чужих способностей, закончите, посмотрите, положа руку на сердце, нельзя ли ваши рекомендации применить к вашим собственным программам. Желательно, чтобы законченный проект включал в себя также наглядное доказательство правильности алгоритмов, дополнительную печать и хотя бы несколько рекомендаций по повышению эффективности словаря. Составление программы заняло около восьми часов, а отладка - около четырех. Причем из четырех часов отладки два ушло на устранение обычных описок и наведение красоты печати. Остальные два часа отладки были посвящены тому, чтобы добавить "+1" в 91-ю строку измененного файла. Одна эта маленькая коварная ошибка вызвала массу трудностей и полностью нарушила режим работы программы поиска в упорядоченном словаре. В конце концов ошибка была обнаружена после того, как мы объяснили всю программу другому программисту. Придерживаясь принципа беспристрастности, он не разделял нашего превратного толкования программы и моментально обнаружил "ляп". Кроме того, около часа было затрачено на вставку и отладку временных переменных (средства подсчета времени в эксплуатирующейся у нас системе развиты в недостаточной степени) и порядка четырех часов на жонглирование параметрами.
СЖАТЫЕ СТРОКИ,
ИЛИ...
ПРОГРАММА УПЛОТНЕНИЯ ТЕКСТОВ
В гл.11 был рассмотрен полезный алгоритм, предназначенный для сжатия текстовой информации. И работай вы программистом, скажем в библиотеке или в газете, то были бы вправе ожидать, что шеф выложит вам на стол одиннадцатую главу и предложит попытаться подключить описанный в ней алгоритм к уже работающей системе. А поскольку кажется вполне правдоподобным, что этот алгоритм мог бы обеспечить значительную экономию памяти, то и задача выглядит на первый взгляд привлекательной. Сомнения приходят позже.
- Насколько сложны алгоритмы, необходимые для выполнения сравнений в словаре, какова сложность структур данных? Как долго придется со всем этим возиться?
- Работа алгоритма определяется наборами параметров. Как эти параметры выбрать?
- В какой степени коэффициент сжатия зависит от вариаций в уплотняемом тексте?
- Ради экономии памяти расходуется процессорное время. Когда можно считать, что овчинка стоит выделки?
- Вообразим, что в первой версии программы все уже ясно и она работает правильно, хотя и не очень эффективно. Какие переделки позволят поднять ее производительность? Можно ли в исходном проекте предусмотреть возможность внесения изменений и дополнений без больших переделок?
- И наконец, сколько времени стоит потратить на эту задачу, чтобы считать, что она выполнена достаточно хорошо?
Примерно те же вопросы должны возникнуть и у начальника, да еще наряду с сомнениями, тот ли вы программист, который осилит поставленную задачу. Тем не менее нельзя допустить, чтобы сомнения вас парализовали. Энергично беритесь за дело невзирая на отдельные трудности (но и не забывая о них) и сконцентрируйте все свои усилия на тех вопросах, которые кажутся легко разрешимыми. В данной работе мы в свою очередь испробуем прежде всего программу, использующую простые структуры данных и алгоритмы. А после того, как программа заработает правильно, постараемся ее улучшить, внося различные усовершенствования. Вполне может так случиться, что свойства программы будут зависеть от неких параметров, поэтому постараемся сделать так, чтобы их можно было легко менять; в первом варианте программы, однако, мы будем просто пробовать возможные значения. Для того чтобы исследовать, как влияют на результаты вносимые в программу изменения, исходная информация или параметры программы, мы будем разрабатывать ее как автономную, не являющуюся частью какой-либо большей системы,- и тогда эффективность интересующей нас программы не будет скрыта за накладными расходами ее окружения.
На практике, разумеется, сжатие текстов, как правило, только часть некоторой большей задачи, предполагающей наличие значительных массивов текста. А положит конец нашей работе отнюдь не снижающаяся результативность, а усталость и скука.
КАК ЗАТОЧИТЬ КАРАНДАШ
У каждого писателя своя манера подготовки к работе. Некоторым надо протрезветь, а кое-кому выпить, одни встают в 4 утра, другие поднимаются на ночь; некоторым необходима тишина, а другим требуется шумная веселая обстановка, а есть и такие, которые обходятся остроотточенным карандашом и традиционным блокнотом. Программисты - те же писатели, и им требуется найти удобный для себя распорядок и уютную окружающую обстановку. Прежде чем приступить к решению задачи о сжатии текста, хотелось бы предложить несколько рецептов, как сделать процесс программирования более приятным и плодотворным. Нас такая методика вполне устраивает, и вы уж по крайней мере испробуйте ее, прежде чем вернетесь к своей собственной.
Программы должны быть читабельными, а это достигается прежде всего их единообразием и согласованностью. Такие качества обусловливают общепризнанный стиль программирования, когда повторяющиеся действия записываются по возможности сходными конструкциями. Чтобы повысить единообразие в программах, старайтесь программировать всегда в одной и той же окружающей обстановке. Почти все наши программы, в том числе большая часть приведенных в книге, написаны в старом садовом кресле-качалке, к которому из листов фанеры и пластмассы была на скорую руку прилажена доска для письма. Это сооружение располагается в жилой комнате, где легко включить стереозапись классической музыки и где всегда под рукой охлажденный чай в холодильнике. То, что нельзя начинать программировать, если в доме гости,- это, конечно, совершенно справедливо. И все же дома настолько спокойнее, чем в любом учреждении, что делается во много раз больше. Может быть, вы предпочтете какие-нибудь другие условия. Не оставляйте поисков, пока не найдете для себя действительно удобной обстановки, а потом поймите, каким образом ее воспроизвести всякий раз, когда программируете.
Многие программисты работают так: набросают на обороте старого конверта несколько строк программы и мчатся к терминалу, чтобы поскорее их набрать и пропустить. А все остальное время занимаются тем, что вставляют в программу там и сям заплатки, и конечный результат их труда смотрится так, словно ужасный доктор Франкенштейн впопыхах прооперировал Шалтая-Болтая. На самом деле, немаловажный вклад в повышение читабельности вносит самодисциплина, одним из способов воспитания которой служат бланки для записи программ. Свободные художники, о которых упоминалось выше, часто с пренебрежением взирают на программистов, которые работают, заполняя клеточки на бланках, и тем не менее бланки оказывают сильное стабилизирующее влияние на манеру работы и во много раз облегчают разработку и использование метода ступенчатой записи программ. Кроме того, программу, написанную на бланках, можно отдать на перфорацию. Причем, как ни приятно освободиться от нудной работы, намного важнее, что девушки из перфораторной ПРОЧИТАЮТ программу и проверят правильность пробивки. Поэтому многие описки никогда не попадут в машину, да и лишний глаз - вовсе не помеха.
Теперь о борьбе с предрассудком. Старайтесь писать свои программы чернилами. Большинство институтских преподавателей программирования будет говорить, что не надо бояться допустить ошибку в программе (это-то достаточно справедливо) и что ластик может стать вашим самым мощным инструментом. К несчастью, ластик может оказаться чересчур мощным. Ведь коль скоро ошибки так просто исправить, значит, пока не совершишь очередную, можно особенно тщательно и не думать. В том же случае, когда вы пишете чернилами, ошибки обходятся дороже, в особенности из-за того, что измазанный переправленный бланк могут однажды на пробивку не принять. Из-за никчемных ошибок придется переписывать целую страницу. Неудача вынудит вас писать медленнее и глубже задумываться над каждой строкой; время, потраченное на написание, окупится при тестировании и отладке программы. Даже если у вас есть редактор текстов, который поощряет или навязывает правильный стиль программирования, все равно следует испробовать эти последние две рекомендации. Запись программы необходимо тщательно продумывать, а опыт показывает, что от электрических полей, окружающих терминалы компьютера, в наших мыслях нередко возникают короткие замыкания.
Вместо того чтобы пользоваться блок-схемой, старайтесь сначала писать комментарии. Всякий раз, когда начинаете новую программу, пишите длинные комментарии, в которых как можно подробнее описывайте назначение программы и ее организацию. Относитесь к составлению комментариев как к важнейшей программистской задаче. После того как комментарии написаны, положите их перед собой и, пользуясь написанным как справочником, протранслируйте их вручную на используемый вами язык программирования. И если язык не очень нудный, как, например, язык ассемблера, то перевод не должен быть существенно длиннее комментариев, а может оказаться даже короче. Благодаря тому что комментарии написаны на отдельных листах (предположительно бланках), их можно рассматривать как документацию, которую нет надобности переписывать только из-за того, что транслируемая программа оказалась неверной. Конечно, если у вас изменятся замыслы в отношении программы, может быть, и потребуется переписать как комментарии, так и сам код.
Ни одну программу не приводите к виду, пригодному для ввода в машину, до тех пор, пока не напишете ее полностью. Однако, как только закончите, пропустите, не откладывая, через машину и устраните все описки,- все неправильно написанные идентификаторы, поставленные не на место точки с запятой и т.д. Ваша цель - получить чистый листинг, лучше бы с полной таблицей перекрестных ссылок. Такой "чистый" листинг не свободен, конечно, от ошибок - просто он не содержит совсем уж глупых, которые в состоянии обнаружить транслятор. Теперь садитесь за программу и пройдитесь по ней так, словно кто-то другой пытается вам ее продать. Проверьте каждую инструкцию, прокрутите каждый цикл, ищите неиспользуемые или употребляемые неверно переменные, старайтесь упростить структуру управления, подправляйте даже знаки препинания в комментариях. Причиной того, почему все это делается на листинге, а не на бланках, является тот факт, что многие ошибки отчетливее проявляются на фоне аккуратно отпечатанной программы. Именно в это время уже пора привести в порядок внешний вид программы, чтобы она стала как можно более наглядной. Если в листинге набралось уже столько правок, что за ними не видно саму программу, внесите все исправления, отпечатайте новый листинг и продолжайте дальше. Не жалейте бумагу - пропущенная ошибка вам может обойтись куда дороже.
Эти предложения годятся, очевидно, не для любых программ и не во всех случаях. Многие системы программирования снабжены целым арсеналом средств, помогающих в процессе разработки программ. Пренебрегать этими возможностями было бы глупо и расточительно. Они особенно полезны при создании программ одноразового использования и для контроля хода работ в больших проектах. Однако мы не можем не предостеречь вас самым серьезным образом: машина не должна мешать вам принимать решения. Чарующая песня компьютера "Доверься мне - я все решу" соблазнила многих программистов и привела к крушению их замыслов.
АНАЛИЗ ВОПРОСА
Поскольку оба основных алгоритма (построение словаря и кодирование текста) уже разработаны, нам необходимо рассмотреть теперь, какими вспомогательными программами их надо снабдить. Прежде всего отметим, что в обоих алгоритмах введенный текст просматривается слева направо и при сравнениях его на совпадение со словарем важны лишь несколько ближайших рядом стоящих литер. Это значит, что как для построения словаря, так и для кодирования можно применить одну и ту же программу ввода и что нам не следует заботиться о деталях доступа к входному потоку, поскольку программа ввода всегда выдает литеры для проведения сравнений или признак конца файла. Во-вторых, в обоих алгоритмах требуется поиск цепочки в словаре, но ни один из алгоритмов не должен зависеть от метода поиска. Поэтому и здесь алгоритмы могут быть снабжены общей обслуживающей программой, и по-прежнему нет необходимости уточнять детали. В-третьих, алгоритму кодирования потребуется хотя бы одна литера, нигде во вводимом тексте не используемая и выступающая в качестве управляющего кодирующего знака. Вместо того чтобы выбрать некую литеру до прочтения текста, можно в программе ввода отслеживать все поступающие на вход литеры и для кодирования употребить любую невстретившуюся. Процедура построения словаря, написанная на XPL показана на рис.30.1 [Номера строк в этой процедуре те же, что и в полной программе, приведенной далее].

Рисунок 30.1.
Здесь уместно кое-что пояснить. Процедура написана на XPL - языке, в достаточной степени похожем как на Паскаль, так и на PL/I, так что его легко понять (подтверждение того факта, что разобраться в специализированном языке, как правило, весьма несложно). Применительно к нашей задаче XPL обладает рядом достоинств, в том числе наличием в языке цепочек в качестве встроенного типа данных и удобных управляющих структур. Недостаток языка заключен, в частности, в том, что единственным видом структурированных данных являются одномерные статические массивы. Язык содержит и редко встречающиеся средства - оператор конкатенации цепочек || и функцию SUBSTR, употребляемую для выделения из имеющейся цепочки подцепочки [Если переменная V - цепочка или выражение, тогда SUBSTR(V, S, L) есть подцепочка V, начинающаяся с S-й литеры (первая литера цепочки имеет номер нуль) и содержащая L байтов. Если аргумент L опущен, будет выдан весь остаток цепочки V, начиная с S-й позиции. Функция LENGTH выдает в качестве значения число литер в цепочке-аргументе. В строке 332 процедуры BUILD.DICTIONARY используется SUBSTR вместе с LENGTH для того, чтобы исключить сличенную цепочку MATCH из начала INPUT.BUFFER (буфер ввода)]. Программа ввода FILL.INPUT.BUFFER (заполнение входного буфера) загружает входной буфер, если он оказывается пустым, и выдает пустую цепочку в случае, когда вводимый файл исчерпан. Если вводить больше нечего, происходит выход из программы BUILD.DICTIONARY (построение словаря). Заметим, что сравнить длину цепочки с нулем и проверять, не пустая ли она,- это одно и то же, но в данном случае первое предпочтительнее, поскольку в XPL операция LENGTH весьма эффективна. Посмотрите теперь как выглядит процедура ввода (рис.30.2).

Рисунок 30.2.
Программы ввода и вывода используют встроенные функции и всегда читают или печатают цепочки. На самом же деле PRINT (печать) является макрокомандой, внутри которой и скрыта работа вывода. Программа FILL.INPUT.BUFFER при необходимости распечатывает буфер ввода и, кроме того, регистрирует данные о каждой встретившейся литере. Функция BYTE при использовании ее в выражении преобразует выбранную из цепочки литеру в целое число таким образом, чтобы можно было ее использовать в арифметических операциях. В нашем случае литеры употребляются для индексирования логического вектора CHARACTER.USED (встречаемость литер), в котором регистрируются все встретившиеся литеры. Кроме того, BYTE употребляется в BUILD.ENCODING.TABLE (формирование таблицы кодировок) для обратного превращения целых чисел в литеры; таким образом, BYTE выполняет те же функции, что и ORD и CHAR в Паскале.
В качестве структуры хранения информации в словаре выберем сначала простую неупорядоченную таблицу, в которой будет осуществляться линейный поиск. Такую структуру можно будет запросто отладить, хотя она, по-видимому, окажется мучительно неэффективна. Но как только у нас все заработает, можно попытаться ускорить поиск. В каждом гнезде словаря будут четыре поля: цепочка литер, частота гнезда во время построения словаря, кодировка, присвоенная этой цепочке, и счетчик обращений к ней при сжатии текста. Эти поля запоминаются в соответствующих четырех массивах, описанных в строках 66-73 главной программы (вот тут-то начинает давать о себе знать ограниченность структур данных в XPL). Первое полноценное гнездо всегда имеет номер 0, а последнее - DICTIONARY.TOP (вершина словаря). Максимальный размер словаря задает макро DICTIONARY.SIZE (размер словаря). При поиске требуется лишь полный просмотр всех гнезд словаря; новые гнезда могут добавляться в конец таблицы. При исключении низкочастотных гнезд на их место переписываются высокочастотные гнезда; читателю надлежит убедиться самому, что при работе цикла, описанного в строках 261-270, информация не теряется. Ниже программа приведена полностью, причем программы работы со словарем описаны в строках 195-296. Обратите внимание, что вычисление параметров, влияющих на степень сжатия, разнесено по самостоятельным подпрограммам, приведенным в строках 154-193, что позволяет с легкостью их отыскать и заменить. Мы предпочли здесь удобство в ущерб эффективности: в окончательной рабочей версии желательно исключить подпрограммы вычисления параметров, а требуемые функции переписать прямо в тех местах, где они должны использоваться.











РЕЗУЛЬТАТЫ
Программа была пропущена, а в качестве исходных данных было использовано ее собственное короткое предисловие. Результаты отпечатаны ниже и снабжены номерами строк, чтобы было легче на них ссылаться. В строках 67-71 показана таблица кодировок. При таком коротком текстовом файле нет ничего удивительного, что словарь получился маленьким. Сжатие составляет лишь 0.973 отчасти из-за того, что строки текста в основных комментариях не раздуты за счет тех самых пробелов, которые столь милы сердцу большинства программ сжатия. Тем не менее имеются некоторые любопытные моменты, о чем свидетельствует строка 69. Обратите внимание, что сжатия "D F" не произошло, поскольку другое сжатие слопало "D" еще раньше.

О ПРЕДПРИНЯТЫХ УСОВЕРШЕНСТВОВАНИЯХ
Как предрекалось выше, линейный поиск в словаре не очень-то эффективен. Когда текст всей исходной программы был взят в качестве исходных данных, для его сжатия на машине со средним быстродействием потребовалось 127с, что страшно долго для файла в 500 строк. Заметьте, что, для того чтобы гарантировать при поиске в словаре отыскание самой длинной из цепочек, совпадающих с началом текста на входе, необходимо просмотреть все гнезда словаря. А вот если гнезда словаря расположить в порядке от самых длинных к самым коротким, поиск можно было бы прекратить при первом же удачном сравнении, ибо волей-неволей найденная цепочка была бы самой длинной из всех возможных. Причем процедуру поиска можно было бы не менять, и выбрасывание низкочастотных гнезд не нарушило бы порядок следования цепочек - от длинных к коротким. Однако при заведении нового гнезда необходимо все более короткие цепочки сдвинуть в таблице на одну позицию вниз. Чтобы определить, где производить вставку, мы ввели массив LENGTH.VECTOR (массив длин), i-я компонента которого указывает на гнездо словаря, в котором начинаются цепочки длиной i литер (если таковые есть) или короче (если нет ни одной цепочки длиной i). В случае если цепочки длиной i литер или меньше отсутствуют, значение LENGTH.VECTOR(i) равно значению DJCTIONARY.TOP + 1. Программы, приведенные ниже, обеспечивают правильное хранение новой структуры данных. Чтобы создать новую версию программы сжатия, в соответствующие места нашей программы помещаются вставки, которые и приведены. Отметим, что для облегчения этого процесса массив вставок снабжен необходимыми комментариями.



Можно рассчитывать, что при использовании поиска до первого совпадения во время построения словаря сравнений будет меньше, а более сложная процедура добавления новых гнезд может занять при этом большее время. Тем не менее из табл. 30.1 видно, что, несмотря на меньшее число сравнений при поиске в упорядоченном словаре, как время построения словаря, так и время кодирования текста увеличивается. Следует, однако, отметить, что для сравнений в первоначальной программе можно обойтись лишь дешевыми проверками длин цепочек, в то время как при поиске в упорядоченном словаре все сравнения требуют дорогих операций сопоставления цепочек. Чтобы повысить эффективность программы, надо бы, конечно, что-то предпринять. Но с другой стороны, проведенная переделка программы иллюстрирует важный принцип отладки. Если структура программы заменяется на функционально эквивалентную, то результаты при тех же исходных данных должны оставаться неизменными. На фактический процесс сжатия организация словаря влиять не должна, только параметры сжатия должны сказываться на содержании словаря. Следовательно, убеждаясь, что результаты работы программы с простым линейным поиском и с поиском до первого совпадения совершенно одинаковы (за исключением временной статистики), мы проверяем правильность изменений в подпрограммах, оперирующих со словарем. Это является также контролем на отсутствие ошибок в других частях программы: если бы в какой-нибудь другой подпрограмме был ляпсус, то он вполне мог бы проявиться в программах работы со словарем. А если уж результаты остаются постоянными после того, как подключается правильная программа поиска до первого совпадения, не исключено (но вовсе и не обязательно), что скрытых ошибок, влияющих на словарь, нет.
Таблица 30.1. Сравнение двух алгоритмов организации словаря

Файл 1 содержит обычную производственную информацию, а файл 2 является текстом исходной программы с линейным поиском. В последнем случае коэффициент сжатия плохой из-за неудачно выбранных параметров. Индексы в названиях файлов соответствуют различным способам поиска - линейному или до первого совпадения.
ВЫБОР ПАРАМЕТРОВ
Конструированием словаря управляют четыре параметра: размер словаря, порог укрупнения гнезд, начальное значение счетчика укрупненных гнезд и порог исключения гнезд. Выбор, который мы сделали, может показаться несколько странным. Размер словаря определяет макро DICTIONARY.SIZE и задается в нашем случае равным 100 (не забудьте, что массивы в XPL начинаются с нулевого индекса), а начальное значение счетчика в гнезде - посредством функции FIRST.COUNT (начальный счетчик) - устанавливается равным единице. Укрупнение гнезд производится в случае, когда каждое из них имеет частоту не меньше, чем
DICTIONARY.SIZE/(DICTIONARY.SIZE - DICTIONARY.TOP + 1) + 1,
т.е. когда частоты обоих гнезд больше величины, обратно пропорциональной свободному пространству словаря. При этом мы исходили из представления (которое не слишком-то хорошо себя оправдало), что, когда словарь почти заполнен, записать новое гнездо должно быть труднее. Исходя из вида приведенного выражения, мы называем порог укрупнения гнезд ЗАВЫШЕННЫМ порогом укрупнения. Исключение гнезд осуществляется в случае, если их частоты по крайней мере не больше средней частоты,- предполагается, что она является приближенным значением медианы.
Чтобы установить, в какой степени такой выбор параметров действительно необоснован, изменим каждый из них, кроме размера словаря, и положим их значение равным пяти. В табл.30.2 отражены результаты обработки обоих файлов. Из таблицы видно, что как порог укрупнения, так и порог исключения оказались неудачными. Вполне возможно, что завышенный порог укрупнения не позволяет объединить и поместить в таблицу достаточное число укрупненных гнезд и, кроме того, быть может, средняя частота, взятая в качестве порога исключения, является плохим приближением медианы, что приводит к ликвидации слишком большого числа гнезд. Все это - лишь очень поверхностное исследование, и надо бы собрать еще дополнительный материал. Однако нас заест тоска раньше, чем программа станет более эффективной.
Таблица 30.2. Небольшое исследование влияния параметров

Запись УКР=5 (ИСК=5, НСЧ=5) означает, что в соответствующем столбце результатов порог УКРупнения (порог ИСКлючения, Начальное значение СЧетчика) устанавливается равным 5. В строках РАЗМЕР СЛОВАРЯ указано минимальное количество литер, необходимое для записи гнезд словаря и их кодировок. Величина суммарного сжатия получена путем деления суммы размера словаря и длины выходного файла на длину входного файла. Времена приведены в мс.
ЗАКЛЮЧИТЕЛЬНЫЕ ЗАМЕЧАНИЯ
Должно быть, эта глава совершенно не похожа на проект, выполненный на пять с плюсом. Над самой программой можно было потрудиться и побольше, особенно над комментариями. Немало среди них путаных и бесполезных. В результате напечатанная программа еще на полпути к завершению, и вы можете полюбоваться, на что похожи ваши собственные недоделанные программы. Вернитесь назад и еще разберите программу, задаваясь при этом мысленным вопросом: "А как бы можно было вылизать данную строку (комментарий, процедуру), чтобы достичь кристальной ясности?" И после того, как вы, ехидничая поводу чужих способностей, закончите, посмотрите, положа руку на сердце, нельзя ли ваши рекомендации применить к вашим собственным программам. Желательно, чтобы законченный проект включал в себя также наглядное доказательство правильности алгоритмов, дополнительную печать и хотя бы несколько рекомендаций по повышению эффективности словаря. Составление программы заняло около восьми часов, а отладка - около четырех. Причем из четырех часов отладки два ушло на устранение обычных описок и наведение красоты печати. Остальные два часа отладки были посвящены тому, чтобы добавить "+1" в 91-ю строку измененного файла. Одна эта маленькая коварная ошибка вызвала массу трудностей и полностью нарушила режим работы программы поиска в упорядоченном словаре. В конце концов ошибка была обнаружена после того, как мы объяснили всю программу другому программисту. Придерживаясь принципа беспристрастности, он не разделял нашего превратного толкования программы и моментально обнаружил "ляп". Кроме того, около часа было затрачено на вставку и отладку временных переменных (средства подсчета времени в эксплуатирующейся у нас системе развиты в недостаточной степени) и порядка четырех часов на жонглирование параметрами.
Gudleifr- Admin
- Сообщения : 3252
Дата регистрации : 2017-03-29
Страница 2 из 2 • 1, 2
» Растригин. Вычислительные машины, системы, сети... 1982
» Приложение. BASIC 1982. Пара книг издательства USBORNE
» Приложение. BASIC 1982. Пара книг издательства USBORNE
Страница 2 из 2
Права доступа к этому форуму:
Вы не можете отвечать на сообщения|
|
|