Интерфейс с ОС
Страница 1 из 1

Интерфейс с ОС
автор Gudleifr Чт Авг 31, 2017 11:14 am
ОГРЫЗКИ...
Казалось бы, мы вправе ожидать от FORTH такого же изящного решения проблем ввода-вывода, каковые он предлагает для решения проблем компиляции или передачи параметров. Тем более, что прецендент есть. Тот же SmallTalk так удачно расширил свои идеи объектно-ориетированного программирования на визуальные объекты, что все разработанные позже оконные системы пользуются его решениями... Не тут-то было. Хотя, ввод-вывод на FORTH не единожды пересматривался, он так и остался по сути BASIC-подобным: т.е., по сути, недостаточным и, одновременно, избыточным набором частных решений для простейших случаев.
***
В 10-й главе Броуди - "Ввод-вывод" - тоже как-то уж очень сумбурно все описано. Кроме ввода/вывода там кратко описывается весь Цикл Управления FORTH, работа со строками и много еще чего. Кажется, весь материал этой главы собран там по одному признаку: "все, что не укладывается в FORTH-концепцию Броуди". Это не порок именно этой книги или одного FORTH. Начиная с ALGOL 60 и LISP авторы языков как-то очень не любят говорить о взаимодействии их программ с внешним миром.
И даже в FORTH-стандарте ANSI-94 большая часть подобных вопросов обнесена заборчиком: "Не входить. Зависит от реализации".
***
А в чем особенность ввода/вывода вообще? Наверное, в неисчислимых особенностях устройств (реальных и виртуальных) для этого самого ввода/вывода. Попробуем хотя бы очертить размер бедствия.
Казалось бы, мы вправе ожидать от FORTH такого же изящного решения проблем ввода-вывода, каковые он предлагает для решения проблем компиляции или передачи параметров. Тем более, что прецендент есть. Тот же SmallTalk так удачно расширил свои идеи объектно-ориетированного программирования на визуальные объекты, что все разработанные позже оконные системы пользуются его решениями... Не тут-то было. Хотя, ввод-вывод на FORTH не единожды пересматривался, он так и остался по сути BASIC-подобным: т.е., по сути, недостаточным и, одновременно, избыточным набором частных решений для простейших случаев.
***
В 10-й главе Броуди - "Ввод-вывод" - тоже как-то уж очень сумбурно все описано. Кроме ввода/вывода там кратко описывается весь Цикл Управления FORTH, работа со строками и много еще чего. Кажется, весь материал этой главы собран там по одному признаку: "все, что не укладывается в FORTH-концепцию Броуди". Это не порок именно этой книги или одного FORTH. Начиная с ALGOL 60 и LISP авторы языков как-то очень не любят говорить о взаимодействии их программ с внешним миром.
И даже в FORTH-стандарте ANSI-94 большая часть подобных вопросов обнесена заборчиком: "Не входить. Зависит от реализации".
***
А в чем особенность ввода/вывода вообще? Наверное, в неисчислимых особенностях устройств (реальных и виртуальных) для этого самого ввода/вывода. Попробуем хотя бы очертить размер бедствия.

Gudleifr- Admin
- Сообщения : 3399
Дата регистрации : 2017-03-29
Re: Интерфейс с ОС
автор Gudleifr Чт Авг 31, 2017 11:21 am
ОСОБЕННОСТИ АВТОНОМИИ УСТРОЙСТВ
Если FORTH реализуется "на голом железе", без операционной системы (ОС), то, с одной стороны ввод/вывод может быть сделан ровно таким, каким нужно по условиям программируемой задачи, с другой - писать придется процедуры для всякой нудной мелочи: приведения устройства в исходное состояние, его опроса, буферизации, обработки прерываний и т.д. и т.п. Если же FORTH функционирует под ОС, то многие вещи упрощаются (кто-то уже многое написал за нас), но взамен мы получаем набор устройств, способ работы с которыми жестко диктуется.
Т.о. мы можем иметь одновременно иметь устройства ввода/вывода, драйвера которых придется писать с нуля, в терминах простейших аппаратных команд, и устройства, представленные сложными объектами, которые, позволяют пользователю редактировать ввод (без всякого участия FORTH), сами сообщают о готовности порции данных, и сами производят форматирование/парсирование информации, не говоря уже об обеспечении всей необходимой буферизации...
Некоторый промежуточный вариант - привычная FORTH-консоль. Она позволяет (как следует из стандарта) получать нажатия клавиш пользователем, "аппаратно" отображает их на экране и обеспечивает простенькое редактирование ввода пользователем (например, использованием клавиши "забой"), понимает некоторые управляющие коды (например, перевод строки)...
***
Самое известное решение этой проблемы принадлежит ОС Unix. Не имея возможности охватить все многообразие устройств ввода/вывода, там стандартизировали некий "средний уровень" - обязательный набор универсальных команд. Т.е. вся аппаратура должна иметь драйвера, его обеспечивающие, а все более сложные возможности должны на нем базироваться. Основная идея: все, что не является кодом или структурой данных в памяти, является файлом. Действие/бездействие любого устройства/программы в системе выражается файлом, т.е. цепочкой литер. Любой обмен состоит в том, что кто-то один пишет символ за символом в какой-то файл, а кто-то другой, также символ за символом из него читает. С точки зрения структур данных, идеальная очередь: первым записан, первым прочтен. Создается ли этот файл в оперативной памяти только на время обмена или на диске, чтобы прочесть его когда-нибудь потом, не важно.
Самое полезное в файлах было то, что для управления ими было достаточно всего пяти операций:
- open - открыть файл (а иногда и создать);
- close - закрыть файл (а иногда и уничтожить);
- read - читать из файла;
- write - писать в файл;
- ioctl - сделать что-то зависящее от типа файла (перемотать ленту, передвинуть указатель...).
Т.о. весь Unix работал полностью упорядоченно, всякий читающий смиренно ждал, пока пишущий соизволит что-то выложить.
Были, конечно, устройства - магнитные диски - с которыми такой способ последовательного чтения не проходил, не будешь же читать весь диск подряд в поисках нужного куска данных (правда, с магнитной лентой именно это и приходилось делать). Пришлось, все-таки, диски считать файлами специального вида - блочными. В первых блоках дисков хранился т.н. каталог - файл, содержащий имена и номера блоков других файлов и каталогов.
Другое ограничение Unix-решения - отказ от совмещения потоков вводов команд и данных. Оно ориентировано на заранее откомпилированные команды, хранящиеся в исполняемых файлах. Т.е. ввод кода программы не может пересечься с вводом данных. Даже при интерпретации кода, считается хорошим тоном собрать интерпретируемые команды в отдельный "псевдо-исполняемый" файл.
Неспособность FORTH воспользоваться плодами этого решения просто раздражает. Именно ее я имел в виду, когда писал о BASIC-подобии. Этакий набор суб-файлов, супер-файлов и команд для второстепенных файловых операций.
***
Если угодно, Windows-решение - огранизовать иерархию "виртуальных драйверов" для стандартной работы с устройствами-объектами самой различной сложности - тоже получилось неудачным. Т.к. "мелкогибким" так и не удалось изобрести приемлемый "стандарт".
***
Единственное удачное ОС-независимое FORTH-решение - использование БЛОКОВ - некоего логического диска с простейшей буферизацией. Память блоков достаточно легко эмулируется средствами любой ОС или, даже, может быть легко создана на "голом железе".
Если FORTH реализуется "на голом железе", без операционной системы (ОС), то, с одной стороны ввод/вывод может быть сделан ровно таким, каким нужно по условиям программируемой задачи, с другой - писать придется процедуры для всякой нудной мелочи: приведения устройства в исходное состояние, его опроса, буферизации, обработки прерываний и т.д. и т.п. Если же FORTH функционирует под ОС, то многие вещи упрощаются (кто-то уже многое написал за нас), но взамен мы получаем набор устройств, способ работы с которыми жестко диктуется.
Т.о. мы можем иметь одновременно иметь устройства ввода/вывода, драйвера которых придется писать с нуля, в терминах простейших аппаратных команд, и устройства, представленные сложными объектами, которые, позволяют пользователю редактировать ввод (без всякого участия FORTH), сами сообщают о готовности порции данных, и сами производят форматирование/парсирование информации, не говоря уже об обеспечении всей необходимой буферизации...
Некоторый промежуточный вариант - привычная FORTH-консоль. Она позволяет (как следует из стандарта) получать нажатия клавиш пользователем, "аппаратно" отображает их на экране и обеспечивает простенькое редактирование ввода пользователем (например, использованием клавиши "забой"), понимает некоторые управляющие коды (например, перевод строки)...
***
Самое известное решение этой проблемы принадлежит ОС Unix. Не имея возможности охватить все многообразие устройств ввода/вывода, там стандартизировали некий "средний уровень" - обязательный набор универсальных команд. Т.е. вся аппаратура должна иметь драйвера, его обеспечивающие, а все более сложные возможности должны на нем базироваться. Основная идея: все, что не является кодом или структурой данных в памяти, является файлом. Действие/бездействие любого устройства/программы в системе выражается файлом, т.е. цепочкой литер. Любой обмен состоит в том, что кто-то один пишет символ за символом в какой-то файл, а кто-то другой, также символ за символом из него читает. С точки зрения структур данных, идеальная очередь: первым записан, первым прочтен. Создается ли этот файл в оперативной памяти только на время обмена или на диске, чтобы прочесть его когда-нибудь потом, не важно.
Самое полезное в файлах было то, что для управления ими было достаточно всего пяти операций:
- open - открыть файл (а иногда и создать);
- close - закрыть файл (а иногда и уничтожить);
- read - читать из файла;
- write - писать в файл;
- ioctl - сделать что-то зависящее от типа файла (перемотать ленту, передвинуть указатель...).
Т.о. весь Unix работал полностью упорядоченно, всякий читающий смиренно ждал, пока пишущий соизволит что-то выложить.
Были, конечно, устройства - магнитные диски - с которыми такой способ последовательного чтения не проходил, не будешь же читать весь диск подряд в поисках нужного куска данных (правда, с магнитной лентой именно это и приходилось делать). Пришлось, все-таки, диски считать файлами специального вида - блочными. В первых блоках дисков хранился т.н. каталог - файл, содержащий имена и номера блоков других файлов и каталогов.
Другое ограничение Unix-решения - отказ от совмещения потоков вводов команд и данных. Оно ориентировано на заранее откомпилированные команды, хранящиеся в исполняемых файлах. Т.е. ввод кода программы не может пересечься с вводом данных. Даже при интерпретации кода, считается хорошим тоном собрать интерпретируемые команды в отдельный "псевдо-исполняемый" файл.
Неспособность FORTH воспользоваться плодами этого решения просто раздражает. Именно ее я имел в виду, когда писал о BASIC-подобии. Этакий набор суб-файлов, супер-файлов и команд для второстепенных файловых операций.
***
Если угодно, Windows-решение - огранизовать иерархию "виртуальных драйверов" для стандартной работы с устройствами-объектами самой различной сложности - тоже получилось неудачным. Т.к. "мелкогибким" так и не удалось изобрести приемлемый "стандарт".
***
Единственное удачное ОС-независимое FORTH-решение - использование БЛОКОВ - некоего логического диска с простейшей буферизацией. Память блоков достаточно легко эмулируется средствами любой ОС или, даже, может быть легко создана на "голом железе".
Gudleifr- Admin
- Сообщения : 3399
Дата регистрации : 2017-03-29
Re: Интерфейс с ОС
автор Gudleifr Чт Авг 31, 2017 11:28 am
ОСОБЕННОСТИ НАЗНАЧЕНИЯ ВВОДА
Это проблема свойственна, вообще всем интерпретаторам. Вводимая информация может ими трактоваться, в общем случае, трояко: как команды, которые нужно исполнить; как команды, сохраняемые для исполнения потом (в составе программы); и как данные, запрашиваемые командами при исполнении. Например, в BASIC: если строка начинается с команды, последняя исполняется, если с числа - строка сохраняется в тексте программы; если строка набита в состоянии выполнения команды INPUT - это ввод данных.
Чарльза Мура так поразил этот разнобой, что он использовал термин "ввод" исключительно для процесса ввода команд (для исполнения или компиляции).
Эта проблема до сих пор смущает начинающих фортеров. Им гораздо проще написать
3 5 СУММА
т.е. засунуть данные в поток команд, чем изобрести слово СУММА, выводящее на консоль посказку для запроса от пользователя слагаемых:
СУММА
1-Е СЛАГАЕМОЕ= 5
2-Е СЛАГАЕМОЕ= 3
***
Так возникло еще одно из важнейших понятий FORTH - ПОТОК. Т.е. процесс считывания откуда-либо слов для исполнения.
Простейшие случаи использования ПОТОКА приведены в таблице:
Забегая вперед, можно показать, что весь широкий спектр пользовательского ввода может быть быть реализован как ввод через ПОТОК. Рассмотрим, например, диалоги с применением условного слова СУММА:
Обычный поток
5 3 СУММА
РЕЗУЛЬТАТ= 8 Ok
Поток с выборкой
СУММА 5 3
РЕЗУЛЬТАТ= 8 Ok
Консольный диалог
СУММА
1-Е СЛАГАЕМОЕ= 5
2-Е СЛАГАЕМОЕ= 3
РЕЗУЛЬТАТ= 8 Ok
Визуальный диалог
1-Е СЛАГАЕМОЕ= [....5]
2-Е СЛАГАЕМОЕ= [....3]
[СУММА]
РЕЗУЛЬТАТ= ....8 Ok
(1) и (2) суть два из многих вариантов использования ПОТОКА. Например, форма (2) может быть использована для произвольного числа параметров, помещающихся в строку ввода. В дальнейшем (1) и (2) различать не буду.
Вариант (4) легко сводится к (1) методом "мышиного драйвера", описанным ниже. Организуется "подпоток" ввода (по сигналу от кнопки СУММА) и в него забивается (1).
О том, что вариант (3) необходим, знает каждый кто видел жуткие Win-программы, в которых для организации выполнения какой-нибудь комплексной операции приходится последовательно заполнить несколько выскакивающих друг за другом диалоговых окошек ответами "Да" и "Очень". Но совершенно очевидно, что (3) очень похож на (2), только с дополнительным "довыводом" приглашений.
***
Как уже писал ранее, еще одна проблема современности - неготовность пользователя что-то писать в ПОТОК. Давить на кнопочки и выбирать из меню он согласен, но написать какой-то скрипт на проблемно-ориентированном языке? Не будем забывать, что создание пользовательских Windows-макросов умерло за ненадобностью еще при переходе к Win-95.
***
ИСТОРИЧЕСКИЙ ЭКСКУРС. Когда-то с подобной проблемой уже сталкивались. Это было в те времена, когда персональные компьютеры только начали оснащать "мышками". Была разработана методика встраивания меню и кнопочек в программы, которые сами по себе не умели работать с мышкой. Драйвер мышки загружался до запуска такой программы и ждал какого-то события (не помню, какого). Дождавшись, вываливал на экран программы кучу менюшек-кнопочек (и, понятно, мышиный курсор) и отслеживал перемещения и клики мышки. Когда пользователь делал, наконец, свой "мышиный" выбор, драйвер восстанавливал экран, переводил сделанный выбор в команды программы и полученный текст запихивал в буфер клавиатурного ввода. Программа, т.о., не ведая о всех этих событиях, пребывала в уверенности, что полученные ею команды честно введены пользователем с клавиатуры. КОНЕЦ ЭКСКУРСА.
Это проблема свойственна, вообще всем интерпретаторам. Вводимая информация может ими трактоваться, в общем случае, трояко: как команды, которые нужно исполнить; как команды, сохраняемые для исполнения потом (в составе программы); и как данные, запрашиваемые командами при исполнении. Например, в BASIC: если строка начинается с команды, последняя исполняется, если с числа - строка сохраняется в тексте программы; если строка набита в состоянии выполнения команды INPUT - это ввод данных.
Чарльза Мура так поразил этот разнобой, что он использовал термин "ввод" исключительно для процесса ввода команд (для исполнения или компиляции).
Эта проблема до сих пор смущает начинающих фортеров. Им гораздо проще написать
3 5 СУММА
т.е. засунуть данные в поток команд, чем изобрести слово СУММА, выводящее на консоль посказку для запроса от пользователя слагаемых:
СУММА
1-Е СЛАГАЕМОЕ= 5
2-Е СЛАГАЕМОЕ= 3
***
Так возникло еще одно из важнейших понятий FORTH - ПОТОК. Т.е. процесс считывания откуда-либо слов для исполнения.
Простейшие случаи использования ПОТОКА приведены в таблице:
| FORTH | КОНСОЛЬ | БЛОКИ |
| Обычная работа | FORTH ведет диалог с пользователем, используя терминал | Вместо ввода с терминала, можно читать из блока. Кроме того к данным в блоках можно обращаться, как к обычным данным в памяти |
| Переназначение ввода/вывода средствами ОС | Как и любую программу, ОС может запустить FORTH, подменив терминал файлами для ввода и вывода | Очевидно, можно запустить FORTH и подсунув ему другой "диск с блоками" (чем бы он ни был) |
| Начальная загрузка FORTH-системы | Пользователь ничего не вводит, ожидая, пока FORTH загрузится | FORTH читает ввод из определенного блока, обычно, первого |
| FORTH, умеющий работать с файлами | Он сам может подменить терминал пользователя чтением/записью в файл | А зачем блоки, если можно читать/писать файлы? |
Забегая вперед, можно показать, что весь широкий спектр пользовательского ввода может быть быть реализован как ввод через ПОТОК. Рассмотрим, например, диалоги с применением условного слова СУММА:
Обычный поток
5 3 СУММА
РЕЗУЛЬТАТ= 8 Ok
Поток с выборкой
СУММА 5 3
РЕЗУЛЬТАТ= 8 Ok
Консольный диалог
СУММА
1-Е СЛАГАЕМОЕ= 5
2-Е СЛАГАЕМОЕ= 3
РЕЗУЛЬТАТ= 8 Ok
Визуальный диалог
1-Е СЛАГАЕМОЕ= [....5]
2-Е СЛАГАЕМОЕ= [....3]
[СУММА]
РЕЗУЛЬТАТ= ....8 Ok
(1) и (2) суть два из многих вариантов использования ПОТОКА. Например, форма (2) может быть использована для произвольного числа параметров, помещающихся в строку ввода. В дальнейшем (1) и (2) различать не буду.
Вариант (4) легко сводится к (1) методом "мышиного драйвера", описанным ниже. Организуется "подпоток" ввода (по сигналу от кнопки СУММА) и в него забивается (1).
О том, что вариант (3) необходим, знает каждый кто видел жуткие Win-программы, в которых для организации выполнения какой-нибудь комплексной операции приходится последовательно заполнить несколько выскакивающих друг за другом диалоговых окошек ответами "Да" и "Очень". Но совершенно очевидно, что (3) очень похож на (2), только с дополнительным "довыводом" приглашений.
***
Как уже писал ранее, еще одна проблема современности - неготовность пользователя что-то писать в ПОТОК. Давить на кнопочки и выбирать из меню он согласен, но написать какой-то скрипт на проблемно-ориентированном языке? Не будем забывать, что создание пользовательских Windows-макросов умерло за ненадобностью еще при переходе к Win-95.
***
ИСТОРИЧЕСКИЙ ЭКСКУРС. Когда-то с подобной проблемой уже сталкивались. Это было в те времена, когда персональные компьютеры только начали оснащать "мышками". Была разработана методика встраивания меню и кнопочек в программы, которые сами по себе не умели работать с мышкой. Драйвер мышки загружался до запуска такой программы и ждал какого-то события (не помню, какого). Дождавшись, вываливал на экран программы кучу менюшек-кнопочек (и, понятно, мышиный курсор) и отслеживал перемещения и клики мышки. Когда пользователь делал, наконец, свой "мышиный" выбор, драйвер восстанавливал экран, переводил сделанный выбор в команды программы и полученный текст запихивал в буфер клавиатурного ввода. Программа, т.о., не ведая о всех этих событиях, пребывала в уверенности, что полученные ею команды честно введены пользователем с клавиатуры. КОНЕЦ ЭКСКУРСА.
Gudleifr- Admin
- Сообщения : 3399
Дата регистрации : 2017-03-29
Re: Интерфейс с ОС
автор Gudleifr Чт Авг 31, 2017 11:47 am
Терминов ПОТОК и БЛОК уже достаточно для разбиения слов FORTH-ввода/вывода по типам (БЛОК здесь трактуется более широко - как любая буферизация ввода/вывода):
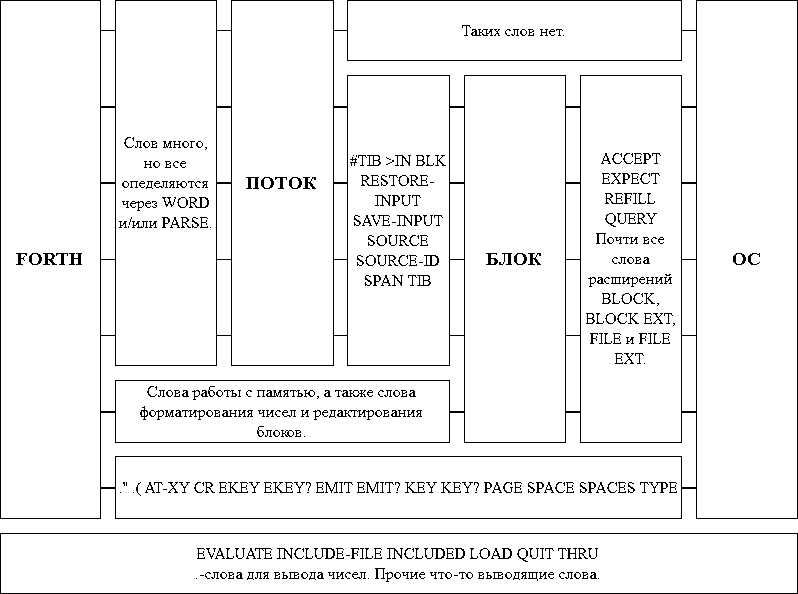
Что тут можно сказать? Очевидно, что одного слова WORD (PARSE - лишь неудобная заплатка для совместимости) достаточно только для простейшего случая ввода команд. Но об этом - позже. Слова тракта БЛОК-ПОТОК - это только переменные указателей, показывающих, какая область памяти считается сейчас источником ПОТОКА. Слова тракта ОС-БЛОК делятся на три группы - работы с терминалом, работы с блоками и работы с файлами. Общего у этих трех групп нет почти ничего, даже имена у них формируются по-разному. А еще там много устаревших слов. Слова тракта ОС-FORTH (т.е. работающие без буферизации и помимо ПОТОКА) - это убогий набор примитивов для ввода-вывода символов (в лучшем случае, строк), плюс зарезервированные (но отданные на откуп реализации) слова опроса состояния клавиатуры. "Прочие слова" - это те, которые собственно и обеспечивают потребности FORTH в вводе и выводе. Они, конечно, используют обсужденные слова отдельных трактов, но совершенно бессистемно и часто прибегая к их "нестандартным аналогам". Например, слова для вывода чисел используют никем более не используемый буфер, зависимый, однако, от состояния словаря. Т.о. если во время форматного вывода чисел произойдет компиляция или выделение памяти, выводимое число будет разрушено.
Что тут можно сказать? Очевидно, что одного слова WORD (PARSE - лишь неудобная заплатка для совместимости) достаточно только для простейшего случая ввода команд. Но об этом - позже. Слова тракта БЛОК-ПОТОК - это только переменные указателей, показывающих, какая область памяти считается сейчас источником ПОТОКА. Слова тракта ОС-БЛОК делятся на три группы - работы с терминалом, работы с блоками и работы с файлами. Общего у этих трех групп нет почти ничего, даже имена у них формируются по-разному. А еще там много устаревших слов. Слова тракта ОС-FORTH (т.е. работающие без буферизации и помимо ПОТОКА) - это убогий набор примитивов для ввода-вывода символов (в лучшем случае, строк), плюс зарезервированные (но отданные на откуп реализации) слова опроса состояния клавиатуры. "Прочие слова" - это те, которые собственно и обеспечивают потребности FORTH в вводе и выводе. Они, конечно, используют обсужденные слова отдельных трактов, но совершенно бессистемно и часто прибегая к их "нестандартным аналогам". Например, слова для вывода чисел используют никем более не используемый буфер, зависимый, однако, от состояния словаря. Т.о. если во время форматного вывода чисел произойдет компиляция или выделение памяти, выводимое число будет разрушено.
Gudleifr- Admin
- Сообщения : 3399
Дата регистрации : 2017-03-29
Re: Интерфейс с ОС
автор Gudleifr Чт Авг 31, 2017 11:51 am
ОСОБЕННОСТИ ЭТАПОВ ПУТИ ОС-FORTH
Можно видеть две разновидности ПОТОКОВ - КОНЕЧНЫЕ и БЕСКОНЕЧНЫЕ. В случае КОНЕЧНЫХ ПОТОКОВ FORTH в курсе длины считанного фрагмента. Т.е. слово WORD (PARSE) при считывании из такого ПОТОКА нового слова проверяет, не вылезло ли оно уже за границу фрагмента. Это общепринятая практика.
В крайнем случае, фрагмент может быть и длиной в один символ. Такое обычно не встречается, но, в принципе, возможно, например, если мы будем интерпретировать "входную ленту" машины Тьюринга.
В БЕСКОНЕЧНЫХ ПОТОКАХ о конце фрагмента сигнализирует специальное завершающее слово, исполнение которого уведомляет систему об этом событии. Например, обычно блоковые буфера имеют после себя нулевой байт, воспринимаемый WORD, как слово с именем нулевой длины. Такое слово специально вставляют в словарь, а его действием делают "завершить интерпретацию блока".
Можно представить себе еще и ФИКСИРОВАННЫЙ ПОТОК, конец которого фиксируется по считывании конкретного числа слов (например, для чтения записей базы данных) и, даже, ПЕРМАНЕНТНЫЙ ПОТОК, чтение из которого будет прервано каким-то внешним событием заведомо раньше, чем исчерпается фрагмент.
С другой стороны, реакция ПОТОКА может быть двоякой - ПОТОКИ С ПРОДОЛЖЕНИЕМ будут приостановлены до представления нового фрагмента, а интерпретация ПОТОКА С ЗАВЕРШЕНИЕМ заканчивается, возвращая управление.
Можно ли привести все эти случаи к одному знаменателю? Можно. Таковым будет КОНЕЧНЫЙ ПОТОК С ЗАВЕРШЕНИЕМ. Слова, завершающие интерпретацию строки (БЕСКОНЕЧНЫЙ ПОТОК) никто нам вставлять в фрагмент не запретит. О придании ПОТОКУ свойств ФИКСИРОВАННОГО и/или ПЕРМАНЕНТНОГО (как и ПОТОКА С ПРОДОЛЖЕНИЕМ) пусть заботится охватывающая процедура.
Так все и делают. К сожалению, это вызывает некоторые накладные расходы: слово WORD вынуждено пару раз проверять, не закончилась ли представленная строка, а ПРОДОЛЖЕНИЕ требует лишнего перехода на уровень - к вызвавшей процедуре (правда, сам бог велел вставить там запрос новой строки).
***
У БЛОКОВ можно выделить всего две разновидности: БЛОКИ ЗАХАТВАТЫВАЕМЫЕ и БЛОКИ КОПИРУЕМЫЕ. Первые предназначены для их возвращения "на место" после выполнения операций над ними (например, при обычном редактировании БЛОКОВ дисковой памяти и/или ФАЙЛОВ). Вторые - содержимое которых можно спокойно разрушить в результате обработки, т.к. они содержат лишь "слепок" полезной информации (например, передача БЛОКА в ПОТОК).
Для блоков первого вида нужно предусмотреть некий механизм защиты БЛОКА от всех других соискателей на время нашей обработки.
Наиболее общим решением здесь будут КОПИРУЕМЫЕ БЛОКИ, переносимые вне зависимости от вида обработки из системных областей во временные буфера процесса. Однако, плата за это решение достаточно высока и достаточно часто используется механизм блоков данных, разделяемых между многими процессами.
Надо отметить, что большинство операций вывода тоже попадает в разряд операций с БЛОКАМИ. (Даже, если "блок" - просто строка в памяти).
***
Естественным будет введение иерархии блоков. Строительными кубиками для нас будут "блоки" трех видов:
- блоки, содержащие информацию "как есть", например кусок считанный из файла;
- структурированный блок, содержащий информацию в виде, определяемом каким-либо синтаксисом. Например, при обмене по http, блок должен иметь стандартные заголовок и завершение, а в середине - структуру <FORM> с тегами, обозначающими органы управления, содержимое которых пишется/читается.
- псевдо-блок, не имеющий возможности сохранить всю информацию за раз в каком-то буфере (возможно, даже, читающий ее частями из различных источников), но создающий у пользователя иллюзию честного последовательного чтения. Например, таким "блоком" (вырожденным) является ПОТОК, лишь переключающий FORTH-читалку с одного реального блока на другой.
Блоки (1) и (2) обычно внешние по отношению к FORTH-системе (будь они ХРАНИМЫМИ или КОПИРУЕМЫМИ), (3) - это блоки самого FORTH, содержащие в откомпилированном виде инструкции по работе с (1) и (2). Они, понятно, КОПИРУЕМЫЕ.
Возвращаясь к нашей схеме, видим: ОС дает БЛОКИ (1), мы рассматриваем их как фрагменты (2), т.е. состоящие из слов, и организуем ПОТОК (3). Т.о. иерархия, вроде бы, уже дана нам в ощущениях.
***
Канал БЛОК-ПОТОК никаких трудностей при реализации не вызывает, все очевидно. Разве что, использование упомянутого выше слова нулевой длины для завершения (т.е. получения ПОТОКА С ЗАВЕРШЕНИЕМ) и слов, принудительно переключающих интерпретацию с одного блока на другой.
***
Остаются операции "мимо" БЛОКА и ПОТОКА.
Во-первых, сюда попадают все "ЧАСТНЫЕ" случаи, подобные описанным выше. Такое, встречается постоянно. Программист замечает, что общее решение слишком затратно в его случае или не охватывает все нужные ему частности, и не минуты не сомневаясь обходит все узкие места, создавая свои аналоги FORTH-процедур. Обидно, конечно, что при этом приходится переписывать очень много кода, т.к. "модульность" стандартных слов работы с ПОТОКАМИ и БЛОКАМИ оставляет желать лучшего.
Во-вторых, здесь присутствуют операции, в корне отличные от уже упоминавшихся. Например не требующие особой буферизации опрос клавиатуры, управление терминалом... Или, наоборот, сложные цепочки преобразований с большим количеством параллельно или последовательно связанных буферов.
Сюда же можно отнести и некоторые операции вывода, которые в FORTH позиционируются как терминальные подсказки: "Ok", "Error...", запрос вводимых данных... От вывода блока они отличаются тем, что требуют от программиста разобраться, где и как ставить перевод строки, и тем, что непосредственно связаны с последующей операцией ввода.
Можно видеть две разновидности ПОТОКОВ - КОНЕЧНЫЕ и БЕСКОНЕЧНЫЕ. В случае КОНЕЧНЫХ ПОТОКОВ FORTH в курсе длины считанного фрагмента. Т.е. слово WORD (PARSE) при считывании из такого ПОТОКА нового слова проверяет, не вылезло ли оно уже за границу фрагмента. Это общепринятая практика.
В крайнем случае, фрагмент может быть и длиной в один символ. Такое обычно не встречается, но, в принципе, возможно, например, если мы будем интерпретировать "входную ленту" машины Тьюринга.
В БЕСКОНЕЧНЫХ ПОТОКАХ о конце фрагмента сигнализирует специальное завершающее слово, исполнение которого уведомляет систему об этом событии. Например, обычно блоковые буфера имеют после себя нулевой байт, воспринимаемый WORD, как слово с именем нулевой длины. Такое слово специально вставляют в словарь, а его действием делают "завершить интерпретацию блока".
Можно представить себе еще и ФИКСИРОВАННЫЙ ПОТОК, конец которого фиксируется по считывании конкретного числа слов (например, для чтения записей базы данных) и, даже, ПЕРМАНЕНТНЫЙ ПОТОК, чтение из которого будет прервано каким-то внешним событием заведомо раньше, чем исчерпается фрагмент.
С другой стороны, реакция ПОТОКА может быть двоякой - ПОТОКИ С ПРОДОЛЖЕНИЕМ будут приостановлены до представления нового фрагмента, а интерпретация ПОТОКА С ЗАВЕРШЕНИЕМ заканчивается, возвращая управление.
Можно ли привести все эти случаи к одному знаменателю? Можно. Таковым будет КОНЕЧНЫЙ ПОТОК С ЗАВЕРШЕНИЕМ. Слова, завершающие интерпретацию строки (БЕСКОНЕЧНЫЙ ПОТОК) никто нам вставлять в фрагмент не запретит. О придании ПОТОКУ свойств ФИКСИРОВАННОГО и/или ПЕРМАНЕНТНОГО (как и ПОТОКА С ПРОДОЛЖЕНИЕМ) пусть заботится охватывающая процедура.
Так все и делают. К сожалению, это вызывает некоторые накладные расходы: слово WORD вынуждено пару раз проверять, не закончилась ли представленная строка, а ПРОДОЛЖЕНИЕ требует лишнего перехода на уровень - к вызвавшей процедуре (правда, сам бог велел вставить там запрос новой строки).
***
У БЛОКОВ можно выделить всего две разновидности: БЛОКИ ЗАХАТВАТЫВАЕМЫЕ и БЛОКИ КОПИРУЕМЫЕ. Первые предназначены для их возвращения "на место" после выполнения операций над ними (например, при обычном редактировании БЛОКОВ дисковой памяти и/или ФАЙЛОВ). Вторые - содержимое которых можно спокойно разрушить в результате обработки, т.к. они содержат лишь "слепок" полезной информации (например, передача БЛОКА в ПОТОК).
Для блоков первого вида нужно предусмотреть некий механизм защиты БЛОКА от всех других соискателей на время нашей обработки.
Наиболее общим решением здесь будут КОПИРУЕМЫЕ БЛОКИ, переносимые вне зависимости от вида обработки из системных областей во временные буфера процесса. Однако, плата за это решение достаточно высока и достаточно часто используется механизм блоков данных, разделяемых между многими процессами.
Надо отметить, что большинство операций вывода тоже попадает в разряд операций с БЛОКАМИ. (Даже, если "блок" - просто строка в памяти).
***
Естественным будет введение иерархии блоков. Строительными кубиками для нас будут "блоки" трех видов:
- блоки, содержащие информацию "как есть", например кусок считанный из файла;
- структурированный блок, содержащий информацию в виде, определяемом каким-либо синтаксисом. Например, при обмене по http, блок должен иметь стандартные заголовок и завершение, а в середине - структуру <FORM> с тегами, обозначающими органы управления, содержимое которых пишется/читается.
- псевдо-блок, не имеющий возможности сохранить всю информацию за раз в каком-то буфере (возможно, даже, читающий ее частями из различных источников), но создающий у пользователя иллюзию честного последовательного чтения. Например, таким "блоком" (вырожденным) является ПОТОК, лишь переключающий FORTH-читалку с одного реального блока на другой.
Блоки (1) и (2) обычно внешние по отношению к FORTH-системе (будь они ХРАНИМЫМИ или КОПИРУЕМЫМИ), (3) - это блоки самого FORTH, содержащие в откомпилированном виде инструкции по работе с (1) и (2). Они, понятно, КОПИРУЕМЫЕ.
Возвращаясь к нашей схеме, видим: ОС дает БЛОКИ (1), мы рассматриваем их как фрагменты (2), т.е. состоящие из слов, и организуем ПОТОК (3). Т.о. иерархия, вроде бы, уже дана нам в ощущениях.
***
Канал БЛОК-ПОТОК никаких трудностей при реализации не вызывает, все очевидно. Разве что, использование упомянутого выше слова нулевой длины для завершения (т.е. получения ПОТОКА С ЗАВЕРШЕНИЕМ) и слов, принудительно переключающих интерпретацию с одного блока на другой.
***
Остаются операции "мимо" БЛОКА и ПОТОКА.
Во-первых, сюда попадают все "ЧАСТНЫЕ" случаи, подобные описанным выше. Такое, встречается постоянно. Программист замечает, что общее решение слишком затратно в его случае или не охватывает все нужные ему частности, и не минуты не сомневаясь обходит все узкие места, создавая свои аналоги FORTH-процедур. Обидно, конечно, что при этом приходится переписывать очень много кода, т.к. "модульность" стандартных слов работы с ПОТОКАМИ и БЛОКАМИ оставляет желать лучшего.
Во-вторых, здесь присутствуют операции, в корне отличные от уже упоминавшихся. Например не требующие особой буферизации опрос клавиатуры, управление терминалом... Или, наоборот, сложные цепочки преобразований с большим количеством параллельно или последовательно связанных буферов.
Сюда же можно отнести и некоторые операции вывода, которые в FORTH позиционируются как терминальные подсказки: "Ok", "Error...", запрос вводимых данных... От вывода блока они отличаются тем, что требуют от программиста разобраться, где и как ставить перевод строки, и тем, что непосредственно связаны с последующей операцией ввода.
Gudleifr- Admin
- Сообщения : 3399
Дата регистрации : 2017-03-29
Re: Интерфейс с ОС
автор Gudleifr Чт Авг 31, 2017 11:55 am
ОСОБЕННОСТИ ОПЕРАЦИОННЫХ СИСТЕМ
Рассматривая тот же Must Die, сразу можно констатировать огромную сложность синхронизации процессов. Тут и обмен сообщениями, и создание-уничтожение процессов, и семафоры, и критические секции... И, кажется, все полезно и находит себе применение. А на самом деле? Еще в конце 70-х специалисты XEROX (прославившегося созданием первого работающего графического оконного интерфейса) попытались проанализировать ситуацию. См. ON THE DUALITY OF OPERATING SYSTEM STRUCTURES, HUGH C.LAUER, XEROX CORPORATION, PALO ALTO, CALIFORNIA, ROGER M.NEEDHAM, CAMBRIDGE UNIVERSITY, CAMBRIDGE, ENGLAND (см. далее ПРИЛОЖЕНИЕ). Они показали, что два подхода в построении ОС - долгоживущие процессы, обменивающиеся сообщениями, и короткоживущие процессы, разделяющие даные, в принципе, эквивалентны. И там, и там можно выделить штуки четыре основных понятий, которые однозначно переводятся один-в-один при том, что вся остальная программа остается безразличной к тому, под какой ОС ее выполняют. К таким понятиям относятся:
Это дает нам "эквивалентность в общем" двух, казалось бы совершенно различных концепций ввода данных:
- асинхронная система (например, Windows) - запуск процедуры ввода по получении сообщения, сообщающего о готовности данных и
- синхронная система (например, Unix) - приостановки процесса в ожиданни готовности данных.
Действительно, почти одно и то же - процедура диалога состоит и там, и там из двух частей: запроса ввода (вывода приглашения, обращения к источнику данных) и обработки данных по их готовности.
***
Нельзя ли покончить с разночтением ОС раз и навсегда? Мне сейчас кажется, что можно. Просто события, получаемые FORTH от MD, это - тоже ПОТОК. Т.о. я, конечно, сразу вынужден говорить о жуткой многозадачности, вплоть до отдельных стеков и словарей, порождаемых этим потоком (потоками), но никак иначе асинхронность не победить. (Кстати, в Linux работа в оконном режиме тоже гробит всю ранее созданную многозадачность и создает "свою" - все, что относится к многочисленным окошкам, вынуждено сосуществовать в одной консоли).
Рассматривая тот же Must Die, сразу можно констатировать огромную сложность синхронизации процессов. Тут и обмен сообщениями, и создание-уничтожение процессов, и семафоры, и критические секции... И, кажется, все полезно и находит себе применение. А на самом деле? Еще в конце 70-х специалисты XEROX (прославившегося созданием первого работающего графического оконного интерфейса) попытались проанализировать ситуацию. См. ON THE DUALITY OF OPERATING SYSTEM STRUCTURES, HUGH C.LAUER, XEROX CORPORATION, PALO ALTO, CALIFORNIA, ROGER M.NEEDHAM, CAMBRIDGE UNIVERSITY, CAMBRIDGE, ENGLAND (см. далее ПРИЛОЖЕНИЕ). Они показали, что два подхода в построении ОС - долгоживущие процессы, обменивающиеся сообщениями, и короткоживущие процессы, разделяющие даные, в принципе, эквивалентны. И там, и там можно выделить штуки четыре основных понятий, которые однозначно переводятся один-в-один при том, что вся остальная программа остается безразличной к тому, под какой ОС ее выполняют. К таким понятиям относятся:
| ПОНЯТИЯ | ОС НА СООБЩЕНИЯХ | ОС НА ПРОЦЕДУРАХ |
| Приостановка текущего процесса | После обработки сообщения | В ожидании освобождения критической секции или установки семафора |
| Очереди ожидающих | Очереди сообщений | Очередь приостановленных процессов |
| Группировки ожидающих | Очереди разных портов, приоритеты | Семафоры |
| Привязывание данных | Привязка к сообщениям | Привязка к критической секции кода |
Это дает нам "эквивалентность в общем" двух, казалось бы совершенно различных концепций ввода данных:
- асинхронная система (например, Windows) - запуск процедуры ввода по получении сообщения, сообщающего о готовности данных и
- синхронная система (например, Unix) - приостановки процесса в ожиданни готовности данных.
Действительно, почти одно и то же - процедура диалога состоит и там, и там из двух частей: запроса ввода (вывода приглашения, обращения к источнику данных) и обработки данных по их готовности.
***
Нельзя ли покончить с разночтением ОС раз и навсегда? Мне сейчас кажется, что можно. Просто события, получаемые FORTH от MD, это - тоже ПОТОК. Т.о. я, конечно, сразу вынужден говорить о жуткой многозадачности, вплоть до отдельных стеков и словарей, порождаемых этим потоком (потоками), но никак иначе асинхронность не победить. (Кстати, в Linux работа в оконном режиме тоже гробит всю ранее созданную многозадачность и создает "свою" - все, что относится к многочисленным окошкам, вынуждено сосуществовать в одной консоли).
Последний раз редактировалось: Gudleifr (Сб Июн 02, 2018 6:24 pm), всего редактировалось 3 раз(а)
Gudleifr- Admin
- Сообщения : 3399
Дата регистрации : 2017-03-29
Re: Интерфейс с ОС
автор Gudleifr Чт Авг 31, 2017 11:57 am
ПЕРВЫЕ НАМЕТКИ К РЕАЛИЗАЦИИ
В алгоритм слова WORD пока вникать не будем, опишем только его спецификацию:
ВХОД: символ-разделитель, адрес фрагмента, длина фрагмента.
ВЫХОД: считанное слово, новые адрес фрагмента и его длина (то, что осталось после считывания слова); если фрагмент был исчерпан ранее, чем удалось считать слово, то на выходе - слово нулевой длины.
Т.о. КОНЕЧНЫЙ ПОТОК можно считать реализованным.
Если добавить слово с нулевым именем (непосредственного исполнения) c действием полностью эквивалентным слову EXIT, то мы реализуем ПОТОК С ЗАВЕРШЕНИЕМ, т.к. такой "выход" будет автоматически выкидывать нас из цикла ПРОДОЛЖЕНИЯ, охватывающего WORD.
Сам этот цикл (он же Цикл Управления FORTH-системы) в простейшем случае выглядит примерно так (у Мура он был целиком кодовым):
: INTERPRET ( ->) BEGIN BL WORD
СЛОВО-В-СЛОВАРЕ? IF
ЕГО-НАДО-ИСПОЛНИТЬ? IF EXECUTE ELSE , THEN
ELSE СЛОВО-ЧИСЛО THEN
ПРОВЕРИТЬ-СТЕК AGAIN ;
: FORTH-СИСТЕМА ( ->) BEGIN ПОЛУЧИТЬ-НОВЫЙ-ФРАГМЕНТ INTERPRET OK AGAIN ;
Вот он, БЕСКОНЕЧНЫЙ или КОНЕЧНЫЙ ПОТОК С ПРОДОЛЖЕНИЕМ, в зависимости от того будет ли слово с нулевым именем (или EXIT) найдено во фрагменте или сгенерировано WORD по исчерпании фрагмента. В обоих случаях оно попадет к EXECUTE и прервет бесконечный цикл INTERPRET. ПРОДОЛЖЕНИЕ ПОТОКА обеспечивается зацикливанием слова FORTH-СИСТЕМА (с подкачкой нового фрагмента). Обратите внимание на положение слова OK, печатающего одноименное приглашение. До него доходит очередь только, если INTERPRET успешно обработало фрагмент. Кроме того, хотелось бы, что бы "Ok" выводилось только если бы конец фрагмента совпадал с концом предложения (например, не выскакивало бы при разрыве посреди ввода определения).
Однако, приведенный пример совершенно не годится для работы в асинхронных ОС (для синхронных - сойдет, процесс тормозится при выполнении слова ПОЛУЧИТЬ-НОВЫЙ-ФРАГМЕНТ).
***
В силу традиций следует, конечно, создать окно (текстовый редактор) для эмуляции консоли. Но, т.к. я использую FOBOS не в качестве универсальной системы, а только для экспериментов с Win-API, то мне консоль пока без надобности. Удобнее править загружаемый в ПОТОК файл.
***
О ПОТОКЕ win-сообщений пока сказать ничего не могу, т.к. только сейчас понял, что он нужен. Очевидно, что один цикл его "интерпретации" уже включен в ассемблерное ядро - цикл обработки сообщений в WinMain() . Никакого сохранительно-восстановительного обвеса она не требует, но должна содержать в себе специальные ловушки для немодальных диалогов и таблиц акселераторов, сильно зависящие от структуры программы. (Ну, не думал Билл, что при добавлении в программу какой-то фигульки мне будет неудобно лезть в самое начало кода, чтобы там ее зарегистрировать).
***
Наличие двух циклов "интерпретации" (если хотите, "пользователей") победить можно по-всякому, вплоть до создания новых стеков для каждого обработчика. Пока же я ограничился паллиативом (т.к. многозадачность внутри одной задачи MD все-таки "нечестная") - стеком сохранения регистров обработчика. (Именно здесь и становится понятным, как удобнее размещать стеки данных и возвратов. Например, если занять родной стек Intel под возвраты, то параметры, передаваемые задействованным здесь функциям Win-API, нужно будет перетаскивать с одного стека на другой. Поэтому я и принял в FOBOS обратное соглашение: SP указывает на данные, а BP - на адреса возврата. Удобнее).
В алгоритм слова WORD пока вникать не будем, опишем только его спецификацию:
ВХОД: символ-разделитель, адрес фрагмента, длина фрагмента.
ВЫХОД: считанное слово, новые адрес фрагмента и его длина (то, что осталось после считывания слова); если фрагмент был исчерпан ранее, чем удалось считать слово, то на выходе - слово нулевой длины.
Т.о. КОНЕЧНЫЙ ПОТОК можно считать реализованным.
Если добавить слово с нулевым именем (непосредственного исполнения) c действием полностью эквивалентным слову EXIT, то мы реализуем ПОТОК С ЗАВЕРШЕНИЕМ, т.к. такой "выход" будет автоматически выкидывать нас из цикла ПРОДОЛЖЕНИЯ, охватывающего WORD.
Сам этот цикл (он же Цикл Управления FORTH-системы) в простейшем случае выглядит примерно так (у Мура он был целиком кодовым):
: INTERPRET ( ->) BEGIN BL WORD
СЛОВО-В-СЛОВАРЕ? IF
ЕГО-НАДО-ИСПОЛНИТЬ? IF EXECUTE ELSE , THEN
ELSE СЛОВО-ЧИСЛО THEN
ПРОВЕРИТЬ-СТЕК AGAIN ;
: FORTH-СИСТЕМА ( ->) BEGIN ПОЛУЧИТЬ-НОВЫЙ-ФРАГМЕНТ INTERPRET OK AGAIN ;
Вот он, БЕСКОНЕЧНЫЙ или КОНЕЧНЫЙ ПОТОК С ПРОДОЛЖЕНИЕМ, в зависимости от того будет ли слово с нулевым именем (или EXIT) найдено во фрагменте или сгенерировано WORD по исчерпании фрагмента. В обоих случаях оно попадет к EXECUTE и прервет бесконечный цикл INTERPRET. ПРОДОЛЖЕНИЕ ПОТОКА обеспечивается зацикливанием слова FORTH-СИСТЕМА (с подкачкой нового фрагмента). Обратите внимание на положение слова OK, печатающего одноименное приглашение. До него доходит очередь только, если INTERPRET успешно обработало фрагмент. Кроме того, хотелось бы, что бы "Ok" выводилось только если бы конец фрагмента совпадал с концом предложения (например, не выскакивало бы при разрыве посреди ввода определения).
Однако, приведенный пример совершенно не годится для работы в асинхронных ОС (для синхронных - сойдет, процесс тормозится при выполнении слова ПОЛУЧИТЬ-НОВЫЙ-ФРАГМЕНТ).
***
В силу традиций следует, конечно, создать окно (текстовый редактор) для эмуляции консоли. Но, т.к. я использую FOBOS не в качестве универсальной системы, а только для экспериментов с Win-API, то мне консоль пока без надобности. Удобнее править загружаемый в ПОТОК файл.
***
О ПОТОКЕ win-сообщений пока сказать ничего не могу, т.к. только сейчас понял, что он нужен. Очевидно, что один цикл его "интерпретации" уже включен в ассемблерное ядро - цикл обработки сообщений в WinMain() . Никакого сохранительно-восстановительного обвеса она не требует, но должна содержать в себе специальные ловушки для немодальных диалогов и таблиц акселераторов, сильно зависящие от структуры программы. (Ну, не думал Билл, что при добавлении в программу какой-то фигульки мне будет неудобно лезть в самое начало кода, чтобы там ее зарегистрировать).
***
Наличие двух циклов "интерпретации" (если хотите, "пользователей") победить можно по-всякому, вплоть до создания новых стеков для каждого обработчика. Пока же я ограничился паллиативом (т.к. многозадачность внутри одной задачи MD все-таки "нечестная") - стеком сохранения регистров обработчика. (Именно здесь и становится понятным, как удобнее размещать стеки данных и возвратов. Например, если занять родной стек Intel под возвраты, то параметры, передаваемые задействованным здесь функциям Win-API, нужно будет перетаскивать с одного стека на другой. Поэтому я и принял в FOBOS обратное соглашение: SP указывает на данные, а BP - на адреса возврата. Удобнее).
Gudleifr- Admin
- Сообщения : 3399
Дата регистрации : 2017-03-29
Re: Интерфейс с ОС
автор Gudleifr Чт Авг 31, 2017 11:59 am
А ВЫВОД?
Что это я все о вводе, да о вводе? Поговорим о выводе. Видится три обычных варианта:
1. Консольно-диалоговый. Изначально именно на это и рассчитанный. Построчный вывод на экран. Обилие подсказок (вроде "нажми любую клавишу", "введи команду", ">", "Ok"...). Иногда, особенно в старых диалоговых системах, деление окна на фреймы и/или подсветка некоторых строк/слов.
2. Потоковый. Упор на передачу информации в некоем стандартном виде, пригодном для скармливания другим программам в качестве ввода. На этом построены все 'nix-ы.
3. Оконный. Ну, тут все понятно.
Очевидно, что (1) легко эмулируется средствами (2) и (3); и что между (2) и (3) практически нет ничего общего.
Это и есть одно из проклятий FORTH. Как какой-нибудь жалкий BASIC, он стандартно ориентирован исключительно на (1). А ежели делать более обобщенную систему, то что взять за основу: (2) или (3)?
Большинство разработчиков берут, что есть. И реализуют голый (1) средствами, наиболее естественными для используемой ОС. И после этого удивляются: почему так мало охотников использовать их продукт? А кому, скажите, интересно тащить за собой избыточные консоли, которые будут вылезать на экран, изумляя пользователя, в случае любого сбоя? А заодно тащить с собой весь код этой "виртуальной машины". Плюс, конечно, реализовать свой (2) или (3) ручками.
(Просматривается аналогия с БЛОКАМИ. Т.е. предлагается легко реализуемая в любых условиях схема. Однако, в отличие от БЛОКОВ, на основе которых можно создавать самые разные хранилища данных, диалогово-консольный ввод-вывод - это тупик. Он пригоден только для сугубо технологических целей.).
***
Главное отличие схем вывода в поток или окно от диалогово-консольных: необходимость буферизации. В FORTH буферизация ввода вывода используется:
- для вывода чисел;
- в механизме БЛОКОВ, очевидно являющихся буферами;
- внутри WORD при распознавании слов из ПОТОКА;
- ввод строк, предназначеных, для ПОТОКА.
Буфера для WORD и вывода чисел удобно располагаются в свободной области словаря.
Без буферизации производится вывод символов, заранее приготовленных строк, пробелов и переводов строки, а также сообщений об успехе-неуспехе обработки ПОТОКА (они же приглашения к вводу в буфер ПОТОКА новых слов-команд).
Конечно, понятно, почему во времена господства FORTRAN уделено такое внимание выводу чисел, но почему тогда практически нет средств форматирования и табулирования?
***
Наличие форматов вывода в таких общепринятых языках, как FORTRAN, C, Perl, разбаловало программистов. Им стало гораздо удобнее описать строку вывода в виде шаблона, чем создать процедуру вывода строки самим.
Однако, последний способ, пусть, менее наглядный, гораздо мощнее. Пример тому - формирование сложных блоков ресурсов в FOBOS. Во-первых, они слишком сложны и потребовалось бы слишком много шаблонов-форматов на все случаи, а, во-вторых, FORTH позволяет упаковывать выводящие шаблоны слова в достаточно наглядные определения. Чем лучше строка "%d %s" последовательности %D SPACE %S ?
Что это я все о вводе, да о вводе? Поговорим о выводе. Видится три обычных варианта:
1. Консольно-диалоговый. Изначально именно на это и рассчитанный. Построчный вывод на экран. Обилие подсказок (вроде "нажми любую клавишу", "введи команду", ">", "Ok"...). Иногда, особенно в старых диалоговых системах, деление окна на фреймы и/или подсветка некоторых строк/слов.
2. Потоковый. Упор на передачу информации в некоем стандартном виде, пригодном для скармливания другим программам в качестве ввода. На этом построены все 'nix-ы.
3. Оконный. Ну, тут все понятно.
Очевидно, что (1) легко эмулируется средствами (2) и (3); и что между (2) и (3) практически нет ничего общего.
Это и есть одно из проклятий FORTH. Как какой-нибудь жалкий BASIC, он стандартно ориентирован исключительно на (1). А ежели делать более обобщенную систему, то что взять за основу: (2) или (3)?
Большинство разработчиков берут, что есть. И реализуют голый (1) средствами, наиболее естественными для используемой ОС. И после этого удивляются: почему так мало охотников использовать их продукт? А кому, скажите, интересно тащить за собой избыточные консоли, которые будут вылезать на экран, изумляя пользователя, в случае любого сбоя? А заодно тащить с собой весь код этой "виртуальной машины". Плюс, конечно, реализовать свой (2) или (3) ручками.
(Просматривается аналогия с БЛОКАМИ. Т.е. предлагается легко реализуемая в любых условиях схема. Однако, в отличие от БЛОКОВ, на основе которых можно создавать самые разные хранилища данных, диалогово-консольный ввод-вывод - это тупик. Он пригоден только для сугубо технологических целей.).
***
Главное отличие схем вывода в поток или окно от диалогово-консольных: необходимость буферизации. В FORTH буферизация ввода вывода используется:
- для вывода чисел;
- в механизме БЛОКОВ, очевидно являющихся буферами;
- внутри WORD при распознавании слов из ПОТОКА;
- ввод строк, предназначеных, для ПОТОКА.
Буфера для WORD и вывода чисел удобно располагаются в свободной области словаря.
Без буферизации производится вывод символов, заранее приготовленных строк, пробелов и переводов строки, а также сообщений об успехе-неуспехе обработки ПОТОКА (они же приглашения к вводу в буфер ПОТОКА новых слов-команд).
Конечно, понятно, почему во времена господства FORTRAN уделено такое внимание выводу чисел, но почему тогда практически нет средств форматирования и табулирования?
***
Наличие форматов вывода в таких общепринятых языках, как FORTRAN, C, Perl, разбаловало программистов. Им стало гораздо удобнее описать строку вывода в виде шаблона, чем создать процедуру вывода строки самим.
Однако, последний способ, пусть, менее наглядный, гораздо мощнее. Пример тому - формирование сложных блоков ресурсов в FOBOS. Во-первых, они слишком сложны и потребовалось бы слишком много шаблонов-форматов на все случаи, а, во-вторых, FORTH позволяет упаковывать выводящие шаблоны слова в достаточно наглядные определения. Чем лучше строка "%d %s" последовательности %D SPACE %S ?
Gudleifr- Admin
- Сообщения : 3399
Дата регистрации : 2017-03-29
Re: Интерфейс с ОС
автор Gudleifr Пт Дек 08, 2017 1:07 pm
ПРИЛОЖЕНИЕ / HUGH C.LAUER, ROGER M.NEEDHAM / XEROX / ON THE DUALITY OF OPERATING SYSTEM STRUCTURES
"Lauer, H.C., Needham, R.M., "On the Duality of Operating Systems Structures," in Proc. Second International Symposium on Operating Systems, IRIA, Oct. 1978, reprinted in Operating Systems Review, 13,2 April 1979, pp.3-19.
Перевод мой и, вероятно, где-то ошибочный. Часто не более, чем пересказ. Но, суть, надеюсь, вы уловите.
***
РЕЗЮМЕ
Многие операционные системы могут грубо отнесены к одной из двух категорий, в зависимости от того, как там понимаются термины "процесс" и "синхронизация". "Системы, ориентированные на сообщения" характеризуются относительно небольшим, практически постоянным числом процессов, использующих для общения специальную явную систему обмена сообщениями. "Процедурно-ориентированные системы" - большим, постоянно меняющимся числом процессов, синхронизирующихся механизмом доступа к общим данным.
Данная статья показывает, что эти две категории взаимозаменяемы и любой системе, первой категории может быть поставлена в соответствие точно так же работающая система второй категории. [Более важно то, что система, пытающаяся совместить в себе оба принципа, будет избыточна по определению.- G.] Главный вывод - ни одна категория не является предпочтительнее другой, и выбор из них диктуется более удобной реализацией на данной машине, но не требованиями к конечному результату.
***
Эта статья носит характер естественнонаучного опыта. Авторы выделили некоторые свойства наблюдаемых объектов и классифицировали их. На основе этой классификации были построены абстрактные модели свойств. Сравнивая поведение реальных объектов и абстрактных моделей подтвердили правильность последних и вывели заключения об их применимости.
Объекты, которые исследовались - операционные системы, а интересующие авторов свойства - взаимодействие и синхронизация процессов в них и их клиентах. Выделилось две категории операционок - "ориентированные на сообщения" и "процедурно-ориентированные". Большинство наблюдаемых систем тяготели либо к одному, либо к другому типу. Причем, внутри групп наблюдалось гораздо больше общих деталей, чем между любыми системами из разных групп. И, наконец, ни одна попытка совместить в одной системе черты обоих групп не увенчалась успехом.
***
Были построены канонические модели обеих категорий. Ориентированная на сообщения система характеризуется малым, статичным числом больших процессов с устойчивыми каналами связи между ними, минимумом разделяемых данных и привязкой пространств данных (контекстов) к процессам. Процедурно-ориентированная система - большим числом часто создаваемых и недолго живущих маленьких процессов, связанным посредством прямого доступа и блокировки данных в памяти, с контекстами, привязанными, скорее, к исполняемой функции, чем к процессу. Эти две модели определяются, соответственно, двумя наборами примитивных операций по управлению процессами их синхронизации. При исследовании их было сделано три наблюдения:
1. Обе модели эквивалентны. Т.е. программа или подсистема может быть перенесена из одной в другую только заменой примитивов.
2. Логика программы/подсистемы от такого переноса не меняется. И оба варианта могут быть сделаны текстуально практически одинаковыми, за исключением несущественными детали.
3. Жизнь программы/подсистемы в обоих моделях - длины очередей, время ожидания, скорость обслуживания - при тех же стратегиях планирования будет одинакова. Потенциальная эффективность примитивов одинакова для обоих моделей.
Основной сделанный вывод состоит в том, что выбор для реализации той или иной модели не зависит от требований к ее функционалу, но, лишь, от удобства реализации примитивов и поддерживающих их механизмов на той или иной архитектуре и аппаратуре.
Остаток статьи посвящен более подробной деталировке моделей, наблюдениям за их поведением, резонам, обоснованиям и, наоборот, опыту и выводам авторов.
***
ДВЕ МОДЕЛИ
Упор в статье сделан на неформальный подход с максимальной опорой на привычную терминологию.
Важно понимать, что ни одна реальная система не является в чистом виде строгим выражением предложенных моделей. Многие из них даже имеют наборы подсистем, тяготеющих к разным моделям. Т.о. наблюдения авторов за моделями относятся к реальным системам постольку поскольку.
Однако, авторы верят (и видят на практике), что, чем более системы или отдельные их части ближе к одной из идеальных моделей, тем лучше они работают, а большинство гибридных реализаций заведомо неудачны.
***
СИСТЕМА, ОРИЕНТИРОВАННАЯ НА СООБЩЕНИЯ.
В ее основе - механизм простого и быстрого обмена сообщениями между процессами (отслеживания событий или еще чего-нибудь - как ни назови). Наличествует механизм очередей сообщений, ожидающих обработки процессами. Процессы могут использовать примитивы посылки сообщений, ожидания сообщений, в т.ч. конкретного класса, проверки состояния очереди. Приостановка низкоприоритетных процессов достигается путем передачи сообщения самому привилегированному из ожидающих его процессов.
Некоторые полезные решения для подобных систем:
- Каналы связи между процессами (порты, сокеты и прочее - как ни назови) образуют устойчивые связи определенных видов между парами процессов. Эти связи обычно долгоживущи и могут быть установлены при инициализации системы.
- Числа процессов и связей между ними достаточно статичны. Уничтожение процессов затруднено наличием неизвестного количества оставшихся в их очередях сообщений, требующих обработки. Создание новых процессов и изменение связей между ними также может вызывать сложности.
- Каждый процесс живет в относительно статичном контексте. Виртуальные или физические пространства памяти ассоциируются с процессами в целом. Защита памяти используется редко (разве что, защита данных от исполнения и доступ к ядру системы), как и разделение данных.
- В результате, процессы имеют тенденцию ассоциироваться с системными ресурсами, и запросы приложений на системное обслуживание передаются как данные соответствующих сообщений.
Подобные решения наиболее обычны в системах реального времени и производственных системах управления, где все необходимые данные часто вмещаются в сообщения. Однако, такая архитектура присуща и некоторым операционным системам общего назначения. Например, IBM OS/360 [IBM Corporation, Operating System/360: Concepts and Facilites, Poughkeepsie, New York] и особенно GEC 4080 [General Electric Company (Marconi-Elliot Division), Borehamwood, London, Great Britain].
Многие из перечисленных выше решений в этих системах возникли закономерно, как следствие хорошего стиля программирования:
- Синхронизация процессов и выделение ресурсов реализуются с использованием прицепленных к управляющим ресурсами процессам очередей сообщений.
- Структуры данных, разделяемые процессами, передаются (в виде ссылок на них) в сообщениях. Никакой процесс, кроме того, кому поступило такое сообщение, не может иметь к ним доступа. В том числе и процесс, пославший сообщение.
- С периферийными устройствами обращаются как с процессами (возможно виртуальными). Управление устройствами реализуется как посылка им сообщений, а аппаратные прерывания от них рассматриваются как сообщения процессов.
- Приоритеты процессов назначаются еще во время разработки системы, сообразно времени, требуемому для работы с соответствующими устройствами.
- Процессы имеют одновременно дело с очень малым числом сообщений и обычно заканчивают все действия, связанные с одним сообщением, до выборки из очереди следующего.
- Поскольку процессы работают в статических контекстах, развитые процедурные интерфейсы и пространства имен не являются особо полезными.
Предложенная каноническая модель обеспечивает следующие механизмы:
- Сообщения и идентификаторы сообщений. Сообщение - структура данных, передаваемая от одного процесса к другому, обычно содержит маленькую фиксированную область для передачи данных, в т.ч. ссылок на большие структуры. Идентификатор идентифицирует конкретное сообщение.
- Каналы и порты передачи сообщений. Канал - абстрактная структура идентифицирующая получателя сообщения. Порт - очередь сообщений некоторого класса или типа, которая привязана к отдельному процессу. Каждый канал должен быть привязан к существующему порту, прежде чем его можно будет использовать. К одному порту может быть привязано несколько каналов.
- Четыре операции передачи сообщений:
- - SendMessage[messageChannel, messageBody] returns [messageId] - ставит сообщение в очередь(порт) соответствующего канала. Идентификатор сообщения возвращается для использования в других операциях.
- - AwaitReply[messageld] returns [messageBody] - система приостанавливает процесс в ожидании ответа на ранее посланное сообщение.
- - WaitForMessage[set of messagePort] returns [messageBody, messageId, messagePort] - процесс приостанавливается в ожидании сообщений, возвращаются параметры первого из сообщений.
- - SendReply[messageId, messageBody] - посылка ответа на сообщение.
- Объявление процесса. Совокупность локальных данных и алгоритмов, его порты и каналы сообщений.
- Операция создания процесса. Создается объявленный заранее процесс и связывает его каналы сообщений с соответствующими портами уже существующих процессов. Из-за связывания это операция достаточно сложна и не должна проводиться часто. (Операция удаления процесса в этой модели не рассматривается из-за сложности и ненужности).
Ниже приведен примерный шаблон процесса обслуживания некоторого ресурса.
Здесь обработка сообщения зависит от порта, куда оно прибыло. Эта обработка может включать посылку новых сообщений или ответ на полученное. Может возникнуть ситуация (например, истощение ресурса), которая повлечет временное игнорирование сообщений из некоторых портов (такие сообщения остаются в очереди, ожидая пока прослушивание порта не будет возобновлено).
Если система построена целиком в этом стиле, то все взаимодействие ее компонентов реализуется механизмом сообщений. Адресные пространства процессов не пересекаются. Строго последовательная обработка сообщений делает не нужной средства защиты памяти.
***
ПРОЦЕДУРНО-ОРИЕНТИРОВАННАЯ СИСТЕМА
Эта модель основана на механизмах адресации и защиты памяти, обеспечивающими быструю и эффективную смену контекстов процессов. Взаимодействие процессов реализуется путем применения блокировок, семафоров, мониторов или других структур синхронизации (предлагается общий термин - блокировка). Процесс может устанавливать блокировку, или останавливаться в ожидании, пока другой не снимет свою. Приостановка процесса более приоритетным осуществляется также установкой последним блокировки.
Успешными решениями здесь являются:
- Такая синхронизация может и защищать глобальные данные, и обеспечить к ним эффективный доступ.
- Создание процесса очень легко, т.к. не требуется никакая привязка каналов. Уничтожение процесса тоже легко, но только при условии, что он снял все свои блокировки.
- Процесс обычно связывается с решением некоторой одной задачи, но может для этого обращаться к разным частям системы (переключая контексты).
- В результате, все ресурсы системы делаются глобальными, а процессы приложений запрашивают к ним доступ.
Примеры подобных систем: HYDRA [W.Wulf, R.Levin, and C.Pierson, "Overview of the Hydra Operating System Development," Proceedings of the FiJ'th Symposium on Operating Systems Principals, Austin, Texas, November, 1975] и Plessey System 250 [D.M.England, "Capability concept mechanism and structure in System 250," Proceedings of the International Workshop on Protection in Operating Systems, IRIA, Rocquencourt, France, August, 1974].
Некоторые характеристики таких систем:
- Синхронизация процессов и выделение ресурсов организуются механизмом очередей, связанных с блокировками структур данных - процессов, ожидающих их снятия.
- Данные разделяются между процессами и процессы обычно стараются блокировать их маленькие фрагменты и на короткий срок.
- Работа с устройствами так же организуется при помощи общих областей памяти и их блокировок.
- Процессы наследуют приоритеты от процессов-родителей, приоритеты реализуются блокировками структур данных на определенное время.
- Защита глобальных областей данных реализуется путем переключения контекстов.
Средства, предоставляемые этой моделью (как расширение Pascal-подобного языка Mesa, XEROX [C.M.Geschke, J.H.Morris, and E.H.Satterthwaite, "Early experience with Mesa," Proceedings of ACM Conference on Language Design for Reliable Software, Raleigh, North Carolina, March 1977]):
- Объявления процедуры. Процедура - часть Mesa-текста, содержащая алгоритм, локальные данные, параметры и результаты. Работает внутри модуля и имеет доступ ко всем глобальным данным модуля.
- Вызовы процедур разделены на синхронные и асинхронные. Синхронные - это обычные Mesa-вызовы процедур, возвращающие результаты (как в обычных Algol-подобных языках). Асинхронные представлены следующими операторами:
- - processId := FORK procedureName[parameterList] - процедура вызывается как новый процесс (создается), в контексте своего объявления, как и при синхронном вызове, но имеет собственный стек и состояние. Процесс, вызвавший FORK, продолжает исполняться далее. Возвращенный идентификатор используется в JOIN.
- - [resultList] := JOIN processId - синхронизация с ранее запущенным процессом. Ожидается его завершение и получаются результаты (как при синхронном вызове). Только после этого процесс, вызвавший JOIN, может продолжаться, а завершенный уничтожается.
- Модули и мониторы. Модуль - это Mesa-единица компиляции, состоит из набора процедур и данных. Применяются обычные правила языка для указания, какие данные/процедуры являются доступными извне модуля. Монитор - специальный вид модуля, имеющий блокировку, гарантирующую, что только один процесс этого модуля может исполняться. Базируется на идее Hoare [C.A.R.Hoare, "Monitors: An Operating System Structuring Concept," Communications of the ACM, 17, 10, pp.549-557, October 1974].
- Создание экземпляра модуля (в т.ч. монитора) производится в Mesa операторами NEW и START. При этом создается контекст, разрешаются внешние ссылки и выполняется код инициализации модуля.
- Переменные условий. Тоже идея Hoare. Дополнительное, более гибкое, чем мониторы и JOIN средство синхронизации. В этой модели переменная условия связывается с монитором (и соответствующей очередью) и используется в двух операторах:
- - WAIT conditionVariable - процесс снимает блокировку монитора, приостанавливается и ставится в очередь.
- - SIGNAL conditionVariable - разрешает очередному ожидающему процессу исполнятся, блокируя монитор для других.
Практически, асинхронные вызовы столь же просты и быстры, как и синхронные. Т.е. создание и удаление процессов очень легко. А, вот, создание экземпляров модулей/мониторов достаточно сложно и должно производится перед началом работы системы. Модель не имеет никаких средств для удаления модулей.
Как и в предыдущем случае, представлен пример простого менеджера ресурса. Это монитор, содержащий глобальные данные (определяющие состояние ресурса) и объявления процедур (предоставляющих услуги его обслуживания):
Признак ENTRY используется для указания процедур, вызов которых возможен извне монитора. Любая процедура, конечно, может обращаться к процедурам других модулей. Внутри монитора для отслеживания доступности (управления доступом) ресурса применяются переменные условий.
В предлагаемой системе нет никаких средств взаимодействия компонентов, кроме вызовов процедур. Процессы могут переходить из контекста в контекст, вызывая процедуры из других модулей. Асинхронные вызовы позволяют параллельную работу. Процессы могут взаимодействовать, устанавливая блокировки и переменные условий. Т.о. никакой процесс не локализуется ни в одной какой-либо отдельной части системы.
***
ХАРАКТЕРИСТИКИ МОДЕЛИ
Главное в описанных моделях - их изоморфность. Программа, написанная для одной, может быть трансформирована в программу для другой. Логика программы, как показывают авторы, от этого не страдает. Как и функционал систем в целом. Дело не в моделировании примитивов одной модели на другой, а в эквивалентности обоих наборов.
***
ТАБЛИЦА СООТВЕТСТВИЯ
Таблица построена на сопоставлении основного функционала моделей и способов действий менеджеров ресурсов:
Т.е. средства, реализующие одну и ту же функциональность есть и в той, и в другой модели, только по-разному называются. Например, SendMessage с последующим через несколько операторов вызовом AwaitReply делает то же самое, что FORK и JOIN.
Наиболее интересное соответствие наблюдается между процессами первой модели и мониторами второй. Варианты в case соответствуют ENTRY-объявлениям. Цикл вокруг WaitForMessage делает тоже самое, что и блокировка монитора одним из процессов. Операторы из case могут быть без изменений перенесены в процедуры монитора и обратно, и будут вызываться при аналогичных условиях.
***
ПОДОБИЕ ПРОГРАММ
Если речь идет о строгом следовании описанным требованиям, то перевод программы из системы одной модели в другую производится автоматически - по приведенной таблице. Монитор переводится в процесс с циклом ожидания сообщений. Синхронные и асинхронные вызовы заменяются на вызовы SendMessage и AwaitReply. Возвраты из процедур - на SendReply. Использование переменных условий - на выборочное ожидание сообщений. И обратно.
Обратите внимание, данное преобразование совершенно не затрагивает логику программ. Все остается на своих местах. Разве что инициализация процесса описывается в начале текста, а монитора - в конце. Никакие алгоритмы и структуры не страдают. Меняются только операторы синхронизации, да и то только синтаксически, но не семантически.
Если рассматриваются не столь строго образцовые модели, то преобразование может быть и не столь простым. Системы, конечно, могут иметь примитивы синхронизации, которые будет трудно/нельзя привести к каноническому виду. Точно так же, могут существовать и менеджеры ресурсов имеющие сильно запутанную логику, которую будет трудно свести к примитивам. Это приводит к вопросу, на который пока нет ответа: Если нам предлагают некую подсистему очень сложную для перевода из одной категории в другую, то, может, речь идет о том, что изначально неуклюже и плохо написано? Например, оператор WAIT потенциально обеспечивает гораздо больше возможностей, чем WaitForMessage. WAIT можно ставить в любом месте любой процедуры монитора, а не только в начале одной из ENTRY-процедур. Однако, это потребует столь тщательной проверки логики синхронизации, что вряд ли будет хорошим решением.
Можно предложить использование для цикла WaitForMessage более Mesa-типичного синтаксиса, тогда текстовое подобие будет еще полнее.
***
ЗАКОНЫ СОХРАНЕНИЯ
Очевидно, что, кроме операторов синхронизации, в программах, подлежащих переносу из системы в систему, должны присутствовать и другие операторы - делающие что-то полезное. Перенос никак не должен помешать их функционированию или ухудшить характеристики программы (если, конечно, аппаратные возможности систем одинаковые). Рассмотрим по отдельности:
- время исполнения самой программы;
- время на работу с примитивами;
- время, затраченное на ожидание в очередях и на перераспределение ресурсов.
На первый компонент перенос программы никак повлиять не может. И количество кода и количество его прогонов никак не меняется.
Авторы утверждают, что оба набора примитивов одинаково эффективны, значит перенос не повлияет и на второй компонент.
- Посылка сообщения, включая размещение тела сообщения, манипуляции с очередью, переходом в контекст другого процесса, является вычислением той же сложности, как вызовы FORK, с такими же операциями с очередью и контекстами.
- Выход из монитора и, возможно, запуск следующего очередника, вычисление той же сложности, что и ожидание сообщения.
- Переключение процессов занимает примерно одинаковое время во всех процессах.
- Механизмы виртуальной памяти одинаково применимы в обоих системах.
Основанием для подобных заявлений служит пример GEC 4080 [General Electric Company (Marconi-Elliot Division), Borehamwood, London, Great Britain] и системы Mesa, где эти примитивы реализованы в микрокоде и примерно одинаково эффективны. В общем, мы видим, что обе модели без проблем реализуются на машинах дружественной архитектуры.
Любая дисциплина планирования, диспетчеризации и организации очереди может одинаково применятся и в одной, и в другой модели. Реакция на системные события так же одинакова в обоих моделях.
Это значит, что и время, затраченное на третий компонент одинаково в обоих системах. Каждому событию в одной соответствует аналогичное в другой. И системы их обработки одинаково эффективны. Те же самые процессы будут стоять в тех же очередях в ожидании тех же ресурсов, то же самое время.
Следовательно, и вся программа после переноса будет столь же эффективна. Как бы ни назывались процедуры синхронизации, их функционирование будет схожим, и код расположенный между ними будет работать точно так же.
***
ОБЛАСТЬ ЭКСПЕРИМЕНТОВ
По многим причинам, показать перенос реальной системы с одной модели на другую очень трудно. Внутрисистемных процессов столь много и они так сложно связаны, что это просто не окупиться. Поэтому с примерами проблема.
Однако, один случай вполне пригоден - Cambridge CAP Computer [R.M.Needharn and R.D.H.Walker, "The Cambridge CAP Computer and it protection system," Proceedings of the Sixth Symposium on Operating System Principles, Purdue University, Lafayette, Indiana, November 1977]. Эта система с замкнутой внутри модулей адресацией. Каждый модуль - отдельная целая программа (обычно на Algo168C). Соответственно, отдельные модули (в терминах CAP - защищенные процедуры) управляют многими отдельными ресурсами системы. Хотя такая архитектура была выбрана и по другим причинам, она делает систему подходящим примером.
Например, изначально в системе был процесс, обслуживающий центральный каталог файлов, на который ссылались все остальные каталоги. Этот процесс обрабатывал запросы на получение доступа к файловым объектам и увеличивал/уменьшал счетчик файловых ссылок. Выяснилось, что механизм сообщений оказался не совсем удобным и этот процесс был заменен на защищенную процедуру, включаемую во все процессы. Текстовые преобразования оказались тривиальными. Было решено принять стиль программирования, облегчающий в дальнейшем подобные преобразования и в остальных частях системы [R.M.Needham, "The CAP project - interim evaluation," Proceedings of the Sixth Symposium on Operating System Principles, Purdue University, Lafayette, Indiana, November 1977]. Все это очень похоже на то, что предлагается здесь.
Хотя стиль программирования CAP, оказавшийся таким подходящимся, и был продиктован требованиями защиты, но авторы считают, что подобные решения могут быть нормой и для других систем. B.J.Stroustrup высказывался в подобном роде [B.J.Stroustrup, "On unifying module interfaces," Operating System Review, 12, 1, pp.90-98, January 1978].
***
ПРЕДПОЧТЕНИЯ СТИЛЯ
Нет никакого качественного различия между двумя моделями с точки зрения программ-клиентов (соображение "нулевого порядка"). Вычислительная сложность обеих моделей с точки зрения их системной реализации одинакова (соображение "первого порядка"). Таким образом, выбрать предпочтительную модель можно только на основании соображений "высшего порядка". Такими соображениями могут быть в особенностях архитектуры машины, на которой система реализуется, и/или программной среды.
Например, на одной машине понятие процесса может быть связано с виртуализацией памяти, и можно будет легко организовать размещение тел сообщений и их постановку в очередь, но трудно организовать защитные процедуры. Понятно, на такой машине легче организовать систему, ориентированную на сообщения. На другой машине, с Algol-подобным стеком и блочной организацией, может быть удобнее реализовать процедурно-ориентированную систему. Архитектурные факторы, влияющие на выбор модели: организация физической и виртуальной памяти, размер описателей контекстов, особенности планирования и диспетчеризации, организация периферийных устройств и прерываний, набор команд и структура регистров. Они обычно выясняются до начала проектирования программного обеспечения (и даже операционной системы). Разработчик системы редко может (тем более, полностью) влиять на их выбор. Значит, он должен выбрать наиболее удобный в заданных условиях набор примитивов, чтобы сократить накладные расходы на функционирование системы.
Следовательно, все эти разговоры относительно выбора способа синхронизации процессов, столь же популярные, сколь и затратные, совершенно непродуктивны. Речь, скорее всего, идет лишь о терминологических разногласиях сторонников обеих систем (например, разном толковании слова "процесс"). В худшем случае, в результате таких споров случается выработка жутких компромиссов.
***
ЗАКЛЮЧЕНИЕ
Конечно, результат умозрительного опыта по сравнению двух абстракций, достаточно слаб, чтобы поколебать убежденность людей, убежденных в изначальном противопоставлении двух концепций. Время покажет.
Имеется несколько целей этих исследований. Во-первых, надо изжить эти непродуктивные споры о преимуществах одной из моделей. Оба в одинаковой степени элегантны, разумны и правильны. Во-вторых, такой подход сократит возможность "свернуть не туда" при разработки систем. Наконец, эквивалентность двух систем говорит о возможности разработки единой модели взаимодействия компонентов системы.
***
БЛАГОДАРНОСТИ
Авторы признательны Michael Melliar-Smith и коллегам по Xerox Palo Alto Research Center и System Development Division,за их наблюдения, предложения и участие в обсуждениях.
"Lauer, H.C., Needham, R.M., "On the Duality of Operating Systems Structures," in Proc. Second International Symposium on Operating Systems, IRIA, Oct. 1978, reprinted in Operating Systems Review, 13,2 April 1979, pp.3-19.
Перевод мой и, вероятно, где-то ошибочный. Часто не более, чем пересказ. Но, суть, надеюсь, вы уловите.
***
РЕЗЮМЕ
Многие операционные системы могут грубо отнесены к одной из двух категорий, в зависимости от того, как там понимаются термины "процесс" и "синхронизация". "Системы, ориентированные на сообщения" характеризуются относительно небольшим, практически постоянным числом процессов, использующих для общения специальную явную систему обмена сообщениями. "Процедурно-ориентированные системы" - большим, постоянно меняющимся числом процессов, синхронизирующихся механизмом доступа к общим данным.
Данная статья показывает, что эти две категории взаимозаменяемы и любой системе, первой категории может быть поставлена в соответствие точно так же работающая система второй категории. [Более важно то, что система, пытающаяся совместить в себе оба принципа, будет избыточна по определению.- G.] Главный вывод - ни одна категория не является предпочтительнее другой, и выбор из них диктуется более удобной реализацией на данной машине, но не требованиями к конечному результату.
***
Эта статья носит характер естественнонаучного опыта. Авторы выделили некоторые свойства наблюдаемых объектов и классифицировали их. На основе этой классификации были построены абстрактные модели свойств. Сравнивая поведение реальных объектов и абстрактных моделей подтвердили правильность последних и вывели заключения об их применимости.
Объекты, которые исследовались - операционные системы, а интересующие авторов свойства - взаимодействие и синхронизация процессов в них и их клиентах. Выделилось две категории операционок - "ориентированные на сообщения" и "процедурно-ориентированные". Большинство наблюдаемых систем тяготели либо к одному, либо к другому типу. Причем, внутри групп наблюдалось гораздо больше общих деталей, чем между любыми системами из разных групп. И, наконец, ни одна попытка совместить в одной системе черты обоих групп не увенчалась успехом.
***
Были построены канонические модели обеих категорий. Ориентированная на сообщения система характеризуется малым, статичным числом больших процессов с устойчивыми каналами связи между ними, минимумом разделяемых данных и привязкой пространств данных (контекстов) к процессам. Процедурно-ориентированная система - большим числом часто создаваемых и недолго живущих маленьких процессов, связанным посредством прямого доступа и блокировки данных в памяти, с контекстами, привязанными, скорее, к исполняемой функции, чем к процессу. Эти две модели определяются, соответственно, двумя наборами примитивных операций по управлению процессами их синхронизации. При исследовании их было сделано три наблюдения:
1. Обе модели эквивалентны. Т.е. программа или подсистема может быть перенесена из одной в другую только заменой примитивов.
2. Логика программы/подсистемы от такого переноса не меняется. И оба варианта могут быть сделаны текстуально практически одинаковыми, за исключением несущественными детали.
3. Жизнь программы/подсистемы в обоих моделях - длины очередей, время ожидания, скорость обслуживания - при тех же стратегиях планирования будет одинакова. Потенциальная эффективность примитивов одинакова для обоих моделей.
Основной сделанный вывод состоит в том, что выбор для реализации той или иной модели не зависит от требований к ее функционалу, но, лишь, от удобства реализации примитивов и поддерживающих их механизмов на той или иной архитектуре и аппаратуре.
Остаток статьи посвящен более подробной деталировке моделей, наблюдениям за их поведением, резонам, обоснованиям и, наоборот, опыту и выводам авторов.
***
ДВЕ МОДЕЛИ
Упор в статье сделан на неформальный подход с максимальной опорой на привычную терминологию.
Важно понимать, что ни одна реальная система не является в чистом виде строгим выражением предложенных моделей. Многие из них даже имеют наборы подсистем, тяготеющих к разным моделям. Т.о. наблюдения авторов за моделями относятся к реальным системам постольку поскольку.
Однако, авторы верят (и видят на практике), что, чем более системы или отдельные их части ближе к одной из идеальных моделей, тем лучше они работают, а большинство гибридных реализаций заведомо неудачны.
***
СИСТЕМА, ОРИЕНТИРОВАННАЯ НА СООБЩЕНИЯ.
В ее основе - механизм простого и быстрого обмена сообщениями между процессами (отслеживания событий или еще чего-нибудь - как ни назови). Наличествует механизм очередей сообщений, ожидающих обработки процессами. Процессы могут использовать примитивы посылки сообщений, ожидания сообщений, в т.ч. конкретного класса, проверки состояния очереди. Приостановка низкоприоритетных процессов достигается путем передачи сообщения самому привилегированному из ожидающих его процессов.
Некоторые полезные решения для подобных систем:
- Каналы связи между процессами (порты, сокеты и прочее - как ни назови) образуют устойчивые связи определенных видов между парами процессов. Эти связи обычно долгоживущи и могут быть установлены при инициализации системы.
- Числа процессов и связей между ними достаточно статичны. Уничтожение процессов затруднено наличием неизвестного количества оставшихся в их очередях сообщений, требующих обработки. Создание новых процессов и изменение связей между ними также может вызывать сложности.
- Каждый процесс живет в относительно статичном контексте. Виртуальные или физические пространства памяти ассоциируются с процессами в целом. Защита памяти используется редко (разве что, защита данных от исполнения и доступ к ядру системы), как и разделение данных.
- В результате, процессы имеют тенденцию ассоциироваться с системными ресурсами, и запросы приложений на системное обслуживание передаются как данные соответствующих сообщений.
Подобные решения наиболее обычны в системах реального времени и производственных системах управления, где все необходимые данные часто вмещаются в сообщения. Однако, такая архитектура присуща и некоторым операционным системам общего назначения. Например, IBM OS/360 [IBM Corporation, Operating System/360: Concepts and Facilites, Poughkeepsie, New York] и особенно GEC 4080 [General Electric Company (Marconi-Elliot Division), Borehamwood, London, Great Britain].
Многие из перечисленных выше решений в этих системах возникли закономерно, как следствие хорошего стиля программирования:
- Синхронизация процессов и выделение ресурсов реализуются с использованием прицепленных к управляющим ресурсами процессам очередей сообщений.
- Структуры данных, разделяемые процессами, передаются (в виде ссылок на них) в сообщениях. Никакой процесс, кроме того, кому поступило такое сообщение, не может иметь к ним доступа. В том числе и процесс, пославший сообщение.
- С периферийными устройствами обращаются как с процессами (возможно виртуальными). Управление устройствами реализуется как посылка им сообщений, а аппаратные прерывания от них рассматриваются как сообщения процессов.
- Приоритеты процессов назначаются еще во время разработки системы, сообразно времени, требуемому для работы с соответствующими устройствами.
- Процессы имеют одновременно дело с очень малым числом сообщений и обычно заканчивают все действия, связанные с одним сообщением, до выборки из очереди следующего.
- Поскольку процессы работают в статических контекстах, развитые процедурные интерфейсы и пространства имен не являются особо полезными.
Предложенная каноническая модель обеспечивает следующие механизмы:
- Сообщения и идентификаторы сообщений. Сообщение - структура данных, передаваемая от одного процесса к другому, обычно содержит маленькую фиксированную область для передачи данных, в т.ч. ссылок на большие структуры. Идентификатор идентифицирует конкретное сообщение.
- Каналы и порты передачи сообщений. Канал - абстрактная структура идентифицирующая получателя сообщения. Порт - очередь сообщений некоторого класса или типа, которая привязана к отдельному процессу. Каждый канал должен быть привязан к существующему порту, прежде чем его можно будет использовать. К одному порту может быть привязано несколько каналов.
- Четыре операции передачи сообщений:
- - SendMessage[messageChannel, messageBody] returns [messageId] - ставит сообщение в очередь(порт) соответствующего канала. Идентификатор сообщения возвращается для использования в других операциях.
- - AwaitReply[messageld] returns [messageBody] - система приостанавливает процесс в ожидании ответа на ранее посланное сообщение.
- - WaitForMessage[set of messagePort] returns [messageBody, messageId, messagePort] - процесс приостанавливается в ожидании сообщений, возвращаются параметры первого из сообщений.
- - SendReply[messageId, messageBody] - посылка ответа на сообщение.
- Объявление процесса. Совокупность локальных данных и алгоритмов, его порты и каналы сообщений.
- Операция создания процесса. Создается объявленный заранее процесс и связывает его каналы сообщений с соответствующими портами уже существующих процессов. Из-за связывания это операция достаточно сложна и не должна проводиться часто. (Операция удаления процесса в этой модели не рассматривается из-за сложности и ненужности).
Ниже приведен примерный шаблон процесса обслуживания некоторого ресурса.
- Код:
begin m: messageBody;
i: messageId;
p: portId;
s: set of portId;
... -- local data and state information for this process
initialize;
do forever;
[m, i, p] := WaitForMessage[s];
case p of
port1 => ... ; -- algorithm for port1
port2 => ...
if resourceExhausted then
s := s - port2;
SendReply[i, reply];
... ; -- algorithm for port2
portk => ...
s := s + port2;
... ; -- algorithm for portk
endcase;
endloop;
end.
Здесь обработка сообщения зависит от порта, куда оно прибыло. Эта обработка может включать посылку новых сообщений или ответ на полученное. Может возникнуть ситуация (например, истощение ресурса), которая повлечет временное игнорирование сообщений из некоторых портов (такие сообщения остаются в очереди, ожидая пока прослушивание порта не будет возобновлено).
Если система построена целиком в этом стиле, то все взаимодействие ее компонентов реализуется механизмом сообщений. Адресные пространства процессов не пересекаются. Строго последовательная обработка сообщений делает не нужной средства защиты памяти.
***
ПРОЦЕДУРНО-ОРИЕНТИРОВАННАЯ СИСТЕМА
Эта модель основана на механизмах адресации и защиты памяти, обеспечивающими быструю и эффективную смену контекстов процессов. Взаимодействие процессов реализуется путем применения блокировок, семафоров, мониторов или других структур синхронизации (предлагается общий термин - блокировка). Процесс может устанавливать блокировку, или останавливаться в ожидании, пока другой не снимет свою. Приостановка процесса более приоритетным осуществляется также установкой последним блокировки.
Успешными решениями здесь являются:
- Такая синхронизация может и защищать глобальные данные, и обеспечить к ним эффективный доступ.
- Создание процесса очень легко, т.к. не требуется никакая привязка каналов. Уничтожение процесса тоже легко, но только при условии, что он снял все свои блокировки.
- Процесс обычно связывается с решением некоторой одной задачи, но может для этого обращаться к разным частям системы (переключая контексты).
- В результате, все ресурсы системы делаются глобальными, а процессы приложений запрашивают к ним доступ.
Примеры подобных систем: HYDRA [W.Wulf, R.Levin, and C.Pierson, "Overview of the Hydra Operating System Development," Proceedings of the FiJ'th Symposium on Operating Systems Principals, Austin, Texas, November, 1975] и Plessey System 250 [D.M.England, "Capability concept mechanism and structure in System 250," Proceedings of the International Workshop on Protection in Operating Systems, IRIA, Rocquencourt, France, August, 1974].
Некоторые характеристики таких систем:
- Синхронизация процессов и выделение ресурсов организуются механизмом очередей, связанных с блокировками структур данных - процессов, ожидающих их снятия.
- Данные разделяются между процессами и процессы обычно стараются блокировать их маленькие фрагменты и на короткий срок.
- Работа с устройствами так же организуется при помощи общих областей памяти и их блокировок.
- Процессы наследуют приоритеты от процессов-родителей, приоритеты реализуются блокировками структур данных на определенное время.
- Защита глобальных областей данных реализуется путем переключения контекстов.
Средства, предоставляемые этой моделью (как расширение Pascal-подобного языка Mesa, XEROX [C.M.Geschke, J.H.Morris, and E.H.Satterthwaite, "Early experience with Mesa," Proceedings of ACM Conference on Language Design for Reliable Software, Raleigh, North Carolina, March 1977]):
- Объявления процедуры. Процедура - часть Mesa-текста, содержащая алгоритм, локальные данные, параметры и результаты. Работает внутри модуля и имеет доступ ко всем глобальным данным модуля.
- Вызовы процедур разделены на синхронные и асинхронные. Синхронные - это обычные Mesa-вызовы процедур, возвращающие результаты (как в обычных Algol-подобных языках). Асинхронные представлены следующими операторами:
- - processId := FORK procedureName[parameterList] - процедура вызывается как новый процесс (создается), в контексте своего объявления, как и при синхронном вызове, но имеет собственный стек и состояние. Процесс, вызвавший FORK, продолжает исполняться далее. Возвращенный идентификатор используется в JOIN.
- - [resultList] := JOIN processId - синхронизация с ранее запущенным процессом. Ожидается его завершение и получаются результаты (как при синхронном вызове). Только после этого процесс, вызвавший JOIN, может продолжаться, а завершенный уничтожается.
- Модули и мониторы. Модуль - это Mesa-единица компиляции, состоит из набора процедур и данных. Применяются обычные правила языка для указания, какие данные/процедуры являются доступными извне модуля. Монитор - специальный вид модуля, имеющий блокировку, гарантирующую, что только один процесс этого модуля может исполняться. Базируется на идее Hoare [C.A.R.Hoare, "Monitors: An Operating System Structuring Concept," Communications of the ACM, 17, 10, pp.549-557, October 1974].
- Создание экземпляра модуля (в т.ч. монитора) производится в Mesa операторами NEW и START. При этом создается контекст, разрешаются внешние ссылки и выполняется код инициализации модуля.
- Переменные условий. Тоже идея Hoare. Дополнительное, более гибкое, чем мониторы и JOIN средство синхронизации. В этой модели переменная условия связывается с монитором (и соответствующей очередью) и используется в двух операторах:
- - WAIT conditionVariable - процесс снимает блокировку монитора, приостанавливается и ставится в очередь.
- - SIGNAL conditionVariable - разрешает очередному ожидающему процессу исполнятся, блокируя монитор для других.
Практически, асинхронные вызовы столь же просты и быстры, как и синхронные. Т.е. создание и удаление процессов очень легко. А, вот, создание экземпляров модулей/мониторов достаточно сложно и должно производится перед началом работы системы. Модель не имеет никаких средств для удаления модулей.
Как и в предыдущем случае, представлен пример простого менеджера ресурса. Это монитор, содержащий глобальные данные (определяющие состояние ресурса) и объявления процедур (предоставляющих услуги его обслуживания):
- Код:
ResourceManager: MONITOR =
C: CONDITION;
resourceExhausted: BOOLEAN;
... -- global data and state information for this process
proc1: ENTRY PROCEDURE[...] =
...; -- algorithm for proc1
proc2: ENTRY PROCEDURE[...] RETURNS[...] =
BEGIN
IF resourceExhausted THEN WAIT C;
...
RETURN[results];
...;
END; -- algorithm for proc2
...
procL: ENTRY PROCEDURE[...] =
BEGIN
...;
resourceExhausted := FALSE;
SIGNAL C;
...;
END; -- algorithm for procL
endloop;
initialize;
END.
Признак ENTRY используется для указания процедур, вызов которых возможен извне монитора. Любая процедура, конечно, может обращаться к процедурам других модулей. Внутри монитора для отслеживания доступности (управления доступом) ресурса применяются переменные условий.
В предлагаемой системе нет никаких средств взаимодействия компонентов, кроме вызовов процедур. Процессы могут переходить из контекста в контекст, вызывая процедуры из других модулей. Асинхронные вызовы позволяют параллельную работу. Процессы могут взаимодействовать, устанавливая блокировки и переменные условий. Т.о. никакой процесс не локализуется ни в одной какой-либо отдельной части системы.
***
ХАРАКТЕРИСТИКИ МОДЕЛИ
Главное в описанных моделях - их изоморфность. Программа, написанная для одной, может быть трансформирована в программу для другой. Логика программы, как показывают авторы, от этого не страдает. Как и функционал систем в целом. Дело не в моделировании примитивов одной модели на другой, а в эквивалентности обоих наборов.
***
ТАБЛИЦА СООТВЕТСТВИЯ
Таблица построена на сопоставлении основного функционала моделей и способов действий менеджеров ресурсов:
| Система, ориентированная на сообщения | Процедурно-ориентированная система |
| Процессы, CreateProcess | Мониторы, NEW/START |
| Каналы сообщений | Имена процедуры, видимые снаружи модуля |
| Порты сообщений | ENTRY-имена процедур |
| SendMessage; AwaitReply (сразу) | Обычный вызов процедуры |
| SendMessage; ... AwaitReply (отложенный) | FORK;... JOIN |
| SendReply | RETURN (из процедуры) |
| Главный цикл менеджера ресурсов, WaitForMessage, case порт | Блокировка монитора, точки ENTRY |
| Операторы в вариантах case | Алгоритмы в объявлениях ENTRY-процедур |
| Ожидание сообщений | Переменные условий, WAIT, SIGNAL |
Т.е. средства, реализующие одну и ту же функциональность есть и в той, и в другой модели, только по-разному называются. Например, SendMessage с последующим через несколько операторов вызовом AwaitReply делает то же самое, что FORK и JOIN.
Наиболее интересное соответствие наблюдается между процессами первой модели и мониторами второй. Варианты в case соответствуют ENTRY-объявлениям. Цикл вокруг WaitForMessage делает тоже самое, что и блокировка монитора одним из процессов. Операторы из case могут быть без изменений перенесены в процедуры монитора и обратно, и будут вызываться при аналогичных условиях.
***
ПОДОБИЕ ПРОГРАММ
Если речь идет о строгом следовании описанным требованиям, то перевод программы из системы одной модели в другую производится автоматически - по приведенной таблице. Монитор переводится в процесс с циклом ожидания сообщений. Синхронные и асинхронные вызовы заменяются на вызовы SendMessage и AwaitReply. Возвраты из процедур - на SendReply. Использование переменных условий - на выборочное ожидание сообщений. И обратно.
Обратите внимание, данное преобразование совершенно не затрагивает логику программ. Все остается на своих местах. Разве что инициализация процесса описывается в начале текста, а монитора - в конце. Никакие алгоритмы и структуры не страдают. Меняются только операторы синхронизации, да и то только синтаксически, но не семантически.
Если рассматриваются не столь строго образцовые модели, то преобразование может быть и не столь простым. Системы, конечно, могут иметь примитивы синхронизации, которые будет трудно/нельзя привести к каноническому виду. Точно так же, могут существовать и менеджеры ресурсов имеющие сильно запутанную логику, которую будет трудно свести к примитивам. Это приводит к вопросу, на который пока нет ответа: Если нам предлагают некую подсистему очень сложную для перевода из одной категории в другую, то, может, речь идет о том, что изначально неуклюже и плохо написано? Например, оператор WAIT потенциально обеспечивает гораздо больше возможностей, чем WaitForMessage. WAIT можно ставить в любом месте любой процедуры монитора, а не только в начале одной из ENTRY-процедур. Однако, это потребует столь тщательной проверки логики синхронизации, что вряд ли будет хорошим решением.
Можно предложить использование для цикла WaitForMessage более Mesa-типичного синтаксиса, тогда текстовое подобие будет еще полнее.
***
ЗАКОНЫ СОХРАНЕНИЯ
Очевидно, что, кроме операторов синхронизации, в программах, подлежащих переносу из системы в систему, должны присутствовать и другие операторы - делающие что-то полезное. Перенос никак не должен помешать их функционированию или ухудшить характеристики программы (если, конечно, аппаратные возможности систем одинаковые). Рассмотрим по отдельности:
- время исполнения самой программы;
- время на работу с примитивами;
- время, затраченное на ожидание в очередях и на перераспределение ресурсов.
На первый компонент перенос программы никак повлиять не может. И количество кода и количество его прогонов никак не меняется.
Авторы утверждают, что оба набора примитивов одинаково эффективны, значит перенос не повлияет и на второй компонент.
- Посылка сообщения, включая размещение тела сообщения, манипуляции с очередью, переходом в контекст другого процесса, является вычислением той же сложности, как вызовы FORK, с такими же операциями с очередью и контекстами.
- Выход из монитора и, возможно, запуск следующего очередника, вычисление той же сложности, что и ожидание сообщения.
- Переключение процессов занимает примерно одинаковое время во всех процессах.
- Механизмы виртуальной памяти одинаково применимы в обоих системах.
Основанием для подобных заявлений служит пример GEC 4080 [General Electric Company (Marconi-Elliot Division), Borehamwood, London, Great Britain] и системы Mesa, где эти примитивы реализованы в микрокоде и примерно одинаково эффективны. В общем, мы видим, что обе модели без проблем реализуются на машинах дружественной архитектуры.
Любая дисциплина планирования, диспетчеризации и организации очереди может одинаково применятся и в одной, и в другой модели. Реакция на системные события так же одинакова в обоих моделях.
Это значит, что и время, затраченное на третий компонент одинаково в обоих системах. Каждому событию в одной соответствует аналогичное в другой. И системы их обработки одинаково эффективны. Те же самые процессы будут стоять в тех же очередях в ожидании тех же ресурсов, то же самое время.
Следовательно, и вся программа после переноса будет столь же эффективна. Как бы ни назывались процедуры синхронизации, их функционирование будет схожим, и код расположенный между ними будет работать точно так же.
***
ОБЛАСТЬ ЭКСПЕРИМЕНТОВ
По многим причинам, показать перенос реальной системы с одной модели на другую очень трудно. Внутрисистемных процессов столь много и они так сложно связаны, что это просто не окупиться. Поэтому с примерами проблема.
Однако, один случай вполне пригоден - Cambridge CAP Computer [R.M.Needharn and R.D.H.Walker, "The Cambridge CAP Computer and it protection system," Proceedings of the Sixth Symposium on Operating System Principles, Purdue University, Lafayette, Indiana, November 1977]. Эта система с замкнутой внутри модулей адресацией. Каждый модуль - отдельная целая программа (обычно на Algo168C). Соответственно, отдельные модули (в терминах CAP - защищенные процедуры) управляют многими отдельными ресурсами системы. Хотя такая архитектура была выбрана и по другим причинам, она делает систему подходящим примером.
Например, изначально в системе был процесс, обслуживающий центральный каталог файлов, на который ссылались все остальные каталоги. Этот процесс обрабатывал запросы на получение доступа к файловым объектам и увеличивал/уменьшал счетчик файловых ссылок. Выяснилось, что механизм сообщений оказался не совсем удобным и этот процесс был заменен на защищенную процедуру, включаемую во все процессы. Текстовые преобразования оказались тривиальными. Было решено принять стиль программирования, облегчающий в дальнейшем подобные преобразования и в остальных частях системы [R.M.Needham, "The CAP project - interim evaluation," Proceedings of the Sixth Symposium on Operating System Principles, Purdue University, Lafayette, Indiana, November 1977]. Все это очень похоже на то, что предлагается здесь.
Хотя стиль программирования CAP, оказавшийся таким подходящимся, и был продиктован требованиями защиты, но авторы считают, что подобные решения могут быть нормой и для других систем. B.J.Stroustrup высказывался в подобном роде [B.J.Stroustrup, "On unifying module interfaces," Operating System Review, 12, 1, pp.90-98, January 1978].
***
ПРЕДПОЧТЕНИЯ СТИЛЯ
Нет никакого качественного различия между двумя моделями с точки зрения программ-клиентов (соображение "нулевого порядка"). Вычислительная сложность обеих моделей с точки зрения их системной реализации одинакова (соображение "первого порядка"). Таким образом, выбрать предпочтительную модель можно только на основании соображений "высшего порядка". Такими соображениями могут быть в особенностях архитектуры машины, на которой система реализуется, и/или программной среды.
Например, на одной машине понятие процесса может быть связано с виртуализацией памяти, и можно будет легко организовать размещение тел сообщений и их постановку в очередь, но трудно организовать защитные процедуры. Понятно, на такой машине легче организовать систему, ориентированную на сообщения. На другой машине, с Algol-подобным стеком и блочной организацией, может быть удобнее реализовать процедурно-ориентированную систему. Архитектурные факторы, влияющие на выбор модели: организация физической и виртуальной памяти, размер описателей контекстов, особенности планирования и диспетчеризации, организация периферийных устройств и прерываний, набор команд и структура регистров. Они обычно выясняются до начала проектирования программного обеспечения (и даже операционной системы). Разработчик системы редко может (тем более, полностью) влиять на их выбор. Значит, он должен выбрать наиболее удобный в заданных условиях набор примитивов, чтобы сократить накладные расходы на функционирование системы.
Следовательно, все эти разговоры относительно выбора способа синхронизации процессов, столь же популярные, сколь и затратные, совершенно непродуктивны. Речь, скорее всего, идет лишь о терминологических разногласиях сторонников обеих систем (например, разном толковании слова "процесс"). В худшем случае, в результате таких споров случается выработка жутких компромиссов.
***
ЗАКЛЮЧЕНИЕ
Конечно, результат умозрительного опыта по сравнению двух абстракций, достаточно слаб, чтобы поколебать убежденность людей, убежденных в изначальном противопоставлении двух концепций. Время покажет.
Имеется несколько целей этих исследований. Во-первых, надо изжить эти непродуктивные споры о преимуществах одной из моделей. Оба в одинаковой степени элегантны, разумны и правильны. Во-вторых, такой подход сократит возможность "свернуть не туда" при разработки систем. Наконец, эквивалентность двух систем говорит о возможности разработки единой модели взаимодействия компонентов системы.
***
БЛАГОДАРНОСТИ
Авторы признательны Michael Melliar-Smith и коллегам по Xerox Palo Alto Research Center и System Development Division,за их наблюдения, предложения и участие в обсуждениях.
Gudleifr- Admin
- Сообщения : 3399
Дата регистрации : 2017-03-29
Страница 1 из 1
Права доступа к этому форуму:
Вы не можете отвечать на сообщения